Hands on hadoop tutorial
This tutorial was originally created by Darrell Aucoin for the Stats Club. Follow along with the orginal and additional files here.
In pioneer days they used oxen for heavy pulling, and when one ox couldn’t budge a log, they didn’t try to grow a larger ox. We shouldn’t be trying for bigger computers, but for more systems of computers. —Grace Hoppe
Motivation
Q: Why do we need Hadoop when we have SQL?
Our capability of storing data has outpaced our ability to read it
Harddrives speeds have not improved as fast as their capacity
Processing capacity have bottlenecked, increasing the need for parallelization of tasks
SQL servers do not scale very well in comparison to Hadoop SQL is best for Gigabytes of data, Hadoop for Terabyes/Petrabyes of data SQL skills are still useful in a Hadoop ecosystem (Hive, Spark SQL, Impala)
Q: Who uses Hadoop?
Q: Why learn Hadoop?
According to O’Reilly Data Science Survey,knowledge of Hadoop and related tools are correlated to the highest salaries in Data Science The highest salaries are correlated to joint knowledge of Hadoop and SQL
Hadoop vs RDBMS (SQL)
| t | SQL | Hadoop |
|---|---|---|
| Data Size | Gigabytes | Terabyte/Petrabytes |
| Access | Interactive and batch | Batch |
| Updates | Read and write many times | Write once, read many times |
| Integrity | High | Low |
| Scaling | Nonlinear | Linear |
| Schema | Write-on Schema | Read-on Schema |
| Data formating | Normalized | Optimally De-normalized |
| Structure | Static schema, highly structured | Dynamic schema, Semi-structured |
When going from a RDBMS to Hadoop, the biggest trade off is the guanrantee of atomicity, consistency, isolation, and durability for scalability.
Write-on Schema: Information is inputted, transformed and written into the predefined schema: we can enforce consistency through this.
Read-on Schema: Bring in files without any predefined gatekeeping or consistency services. The schema is created when reading the files using a set of predefined rules. For instance, a comma seperated file could have it’s first entry interpretated as a string, the second as an integer, the third as a float, etc.
What is Hadoop?
Definition. Hadoop is a MapReduce framework built on top of a distributed file system (HDFS for Hadoop).
Hadoop is distributed system, meaning it’s an interconnected system of computers that looks to the user as just one single entity.
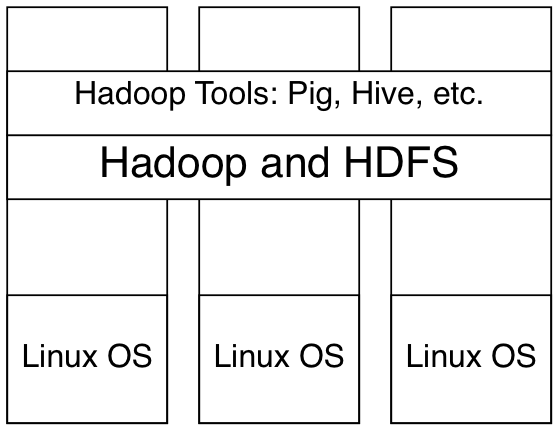
When a client submits a MapReduce Job, the job is split into several tasks and the nodes takes on a fixed number of tasks per node Written in mainly in Java, with some components written in C and bash Designed around processing high throughput of large data rather than response times Hadoop is highly configurable, both in it’s operations and job configurations
Note:
All components and modules have to be installed on every node in a cluster (i.e. to use a module in R, the module has to be installed on every node)
A single node may be running several tasks from several different jobs
Hadoop V1.x and V2.x
Due to compatiability breaking problems with V1.x, V2.x was created: 2.x allows Hadoop Streaming to stream binary data compared to just text with 1.x 2.x is more scalable, 1.x has a bottleneck in it’s design (a singular NameNode) Various Hadoop configuration options changed names
What is MapReduce?
Definition. MapReduce is a programming paradigm model of using parallel, distributed algorithims to process or generate data sets. MapRedeuce is composed of two main functions:
Map(k,v): Filters and sorts data.
Reduce(k,v): Aggregates data according to keys (k).
Hadoop MapReduce Components
###Hadoop 1.x JobTracker Coordinates jobs, scheduling task for tasktrackers and records progress for each job If a task fails, it’s rescheduled on different TaskTracker
TaskTracker Runs tasks and send progress reports to the jobtracker
###Hadoop 2.x ResourceManager: Arbitrates resources among all applications in the system.
ApplicationMaster: A per-application framework tasked with negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and manitor tasks the component tasks.
MRAppMaster: per application
NodeManager: YARN’s per-node agent: Keeping up-to-date with ResourceManager Overseeing individual tasks life-cycle management Constructing a JVM, running the task, then deconstructing the JVM
Monitoring resource usage for each task: memory, CPU Tracking node-health Logging management and auxiliary services
What is HDFS?
Definition. HDFS (Hadoop Distributed File System) is a fault tolerant, distributed, scalable file-system accross multiple interconnected computer systems (nodes).
Fault tolerant means that a single node failure will not halt operations. It does this by replicating the data accross multiple nodes (usually 3).
Distributed means that data is shared accross multiple computer nodes. This means that one node can have data that another node does not. The data nodes can “talk” to each other to balance the data.
Scalable means that performance for clients/node are roughly linear. To increase performance, add new nodes which allows a greater number of clients.
HDFS Components
NameNode The master node: maintains the namespace of the directories and files and manages the blocks on each DataNode.
Usually the most RAM intensive component of HDFS (keeping all metadata of files/directories in memory) - Best to have input files at least a gigabyte in size - The greatest bottleneck for Hadoop 1.x, having only 1 NameNode: too many files requires more ram than the NameNode can provide. Hadoop 2.x uses HDFS Federation, a collection of independent NameNodes.
DataNode Provides the actual storage of the blocks of files.
Secondary NameNode Performs periodic checkpoints of the NameNode and in the event of NameNode failure, can restart the NameNode from last checkpoint (can take a while and a chance of data loss). Secondary Namespace lags behind primary, thus total failure of primary will likely result in data loss Otherwise, copy metadata to secondary and run that as the new primary
Various Hadoop Projects
Hive: Allows users to create SQL-like queries
(HQL) and convert them to MapReduce jobs. (INSERT, UPDATE, DELETE statements
are not allowed).
Pig: An easy to learn hadoop-based language that is adept at very deep, very long data pipelines. Very commonly used with DataFu, LinkedIn assortment of User Defined Functions useful for data analysis.
Spark: Another implementation of MapReduce that is more effective for iterative algorithms (machine learning algorithms). Also has built in packages for Spark SQL, and machine learning.
HBase: Non-relational database allowing low- latency, quick lookups in Hadoop. Can do updates, inserts, and deletes.
Oozie: A workflow processing that lets users define a series of jobs written in multiple languages: Hadoop, Pig, and Hive and then link them to one another.
Avro: A data serialization system that allows for encoding the schema of Hadoop files. It is adept at parsing data and performing removed procedure calls.
Mahout: A data mining library using the most popular data mining algorithims for performing clustering, regression testing and statistical modeling and implements them using the Map Reduce model.
Sqoop: A conectivity tool for moving data from non-Hadoop databases (SQL, etc.) into Hadoop.
HCatalog: A centralized metadata mangagement and sharing service for Hadoop, allowing a unified view of all data in Hadoop clusters.
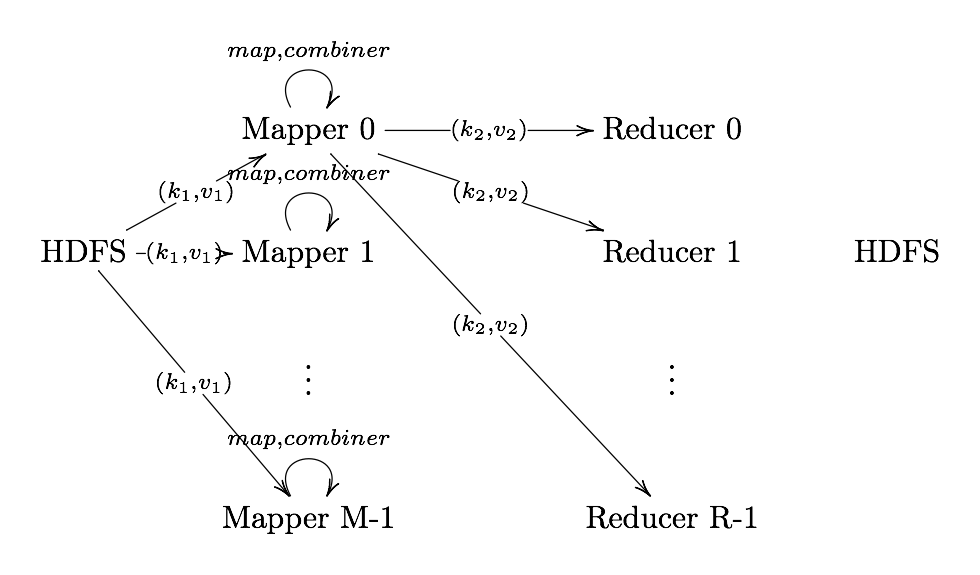
MapReduce Phases
MapReduce is broken down into several steps:
- Record Reader
- Map
- Combiner (Optional)
- Partitioner
- Shuffle and Sort
- Reduce
- Output Format
Record Reader
Record Reader Translates an input into records to be processed by the user- defined map function in the form of a key-value pair on each map cluster.
The key is positional information (the number of bytes from start of file) and the value is the chunk of data composing a single record.
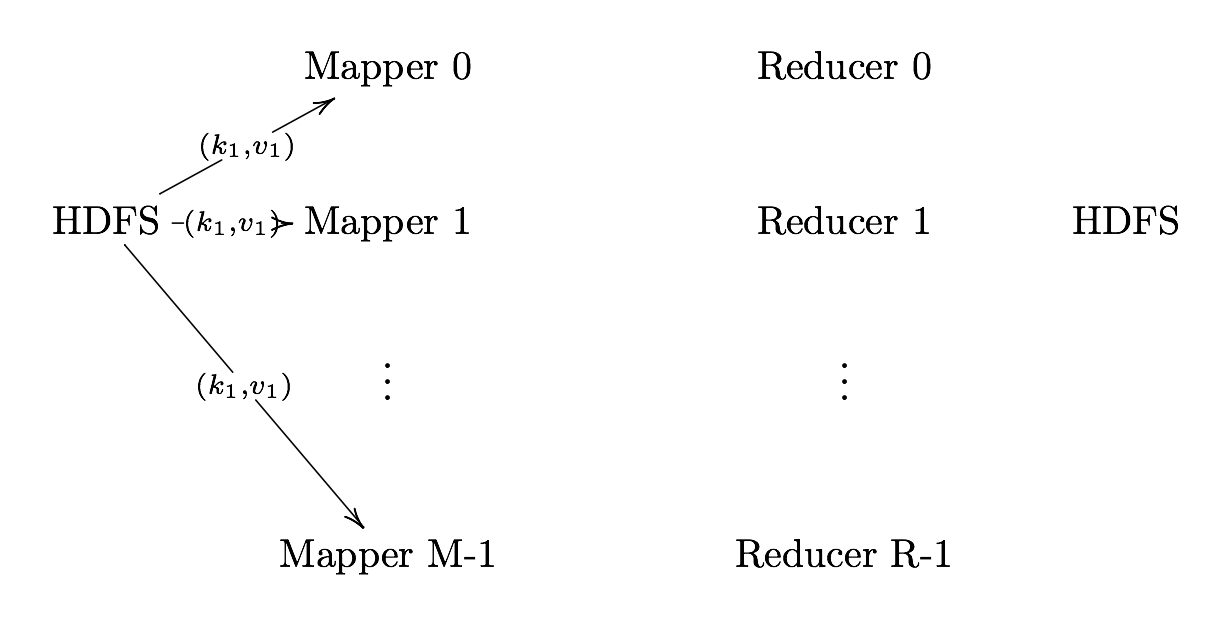
In hadoop, each map task’s is an input split which is usually simply a HDFS block - Hadoop tries scheduling map tasks on nodes where that block is stored (data locality) - If a file is broken mid-record in a block, hadoop requests the additional information from the next block in the series
Map
Map User defined function outputing intermediate key-value pairs for the
reducers
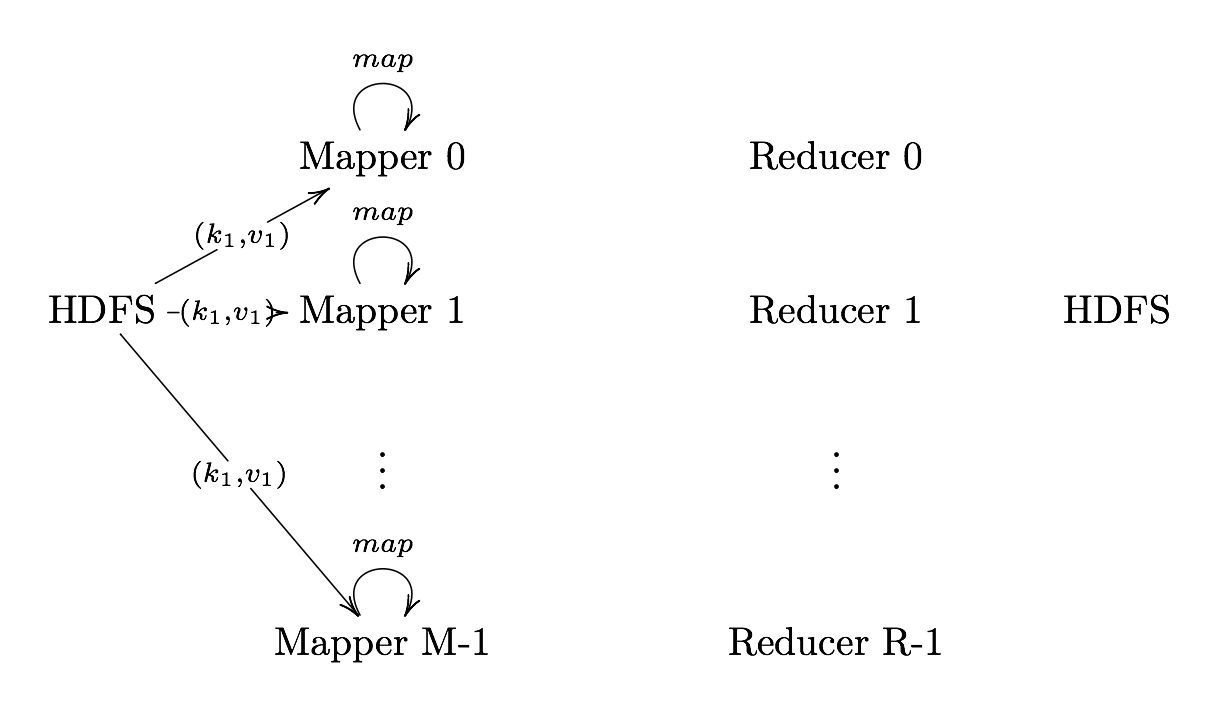
key ($k_{2}$): Later, MapReduce will group and possibly aggregate data according to these keys, choosing the right keys is here is important for a good MapReduce job.
value ($v_{2}$): The data to be grouped according to it’s keys.
Combiner (Optional)
Combiner User defined function that aggregates data according to
intermediate keys on a mapper node
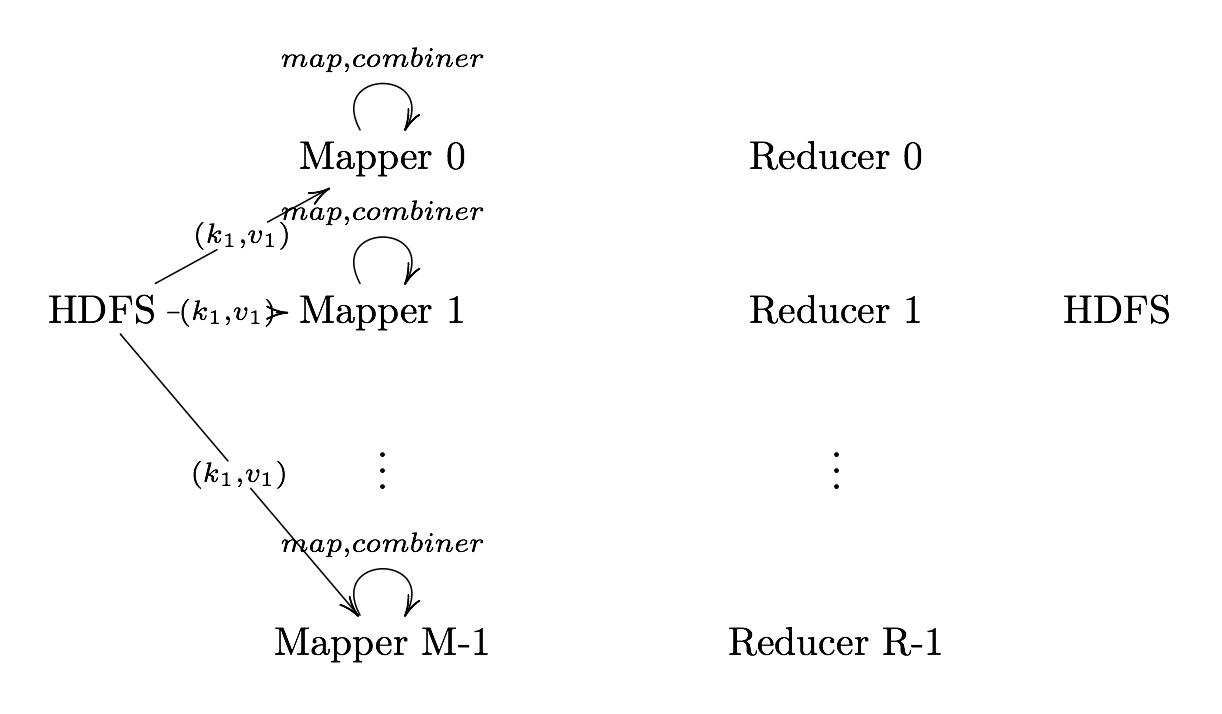
This can usually reduce the amount of data to be sent over the network
increasing efficiency
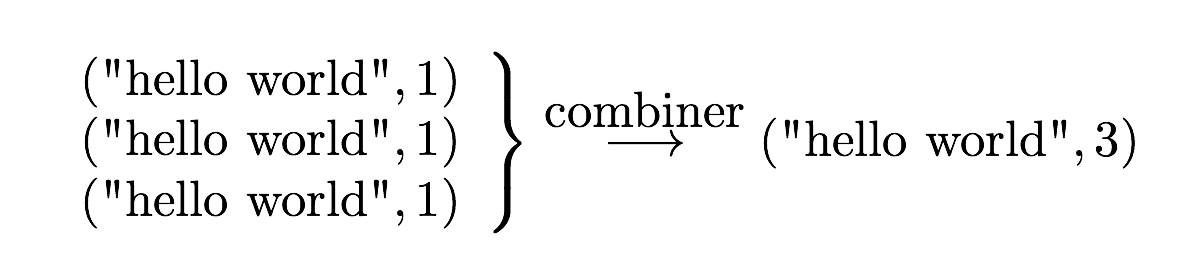
Combiner should be written with the idea that it is executed over most but not
all map tasks. ie.
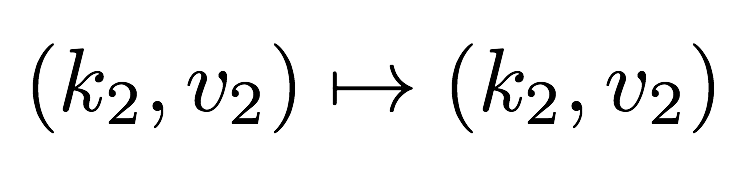
Usually very similar or the same code as the reduce method.
Partitioner
Partitioner Sends intermediate key-value pairs (k,v) to reducer by
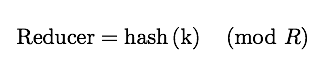
will usually result in a roughly balanced load accross the reducers while ensuring that all key-value pairs are grouped by their key on a single reducer. A balancer system is in place for the cases when the key-values are too unevenly distributed. In hadoop, the intermediate keys ($k_{2},v_{2}$) are written to the local harddrive and grouped by which reduce they will be sent to and their key.
Shuffle and Sort
Shuffle and Sort On reducer node, sorts by key to help group equivalent keys
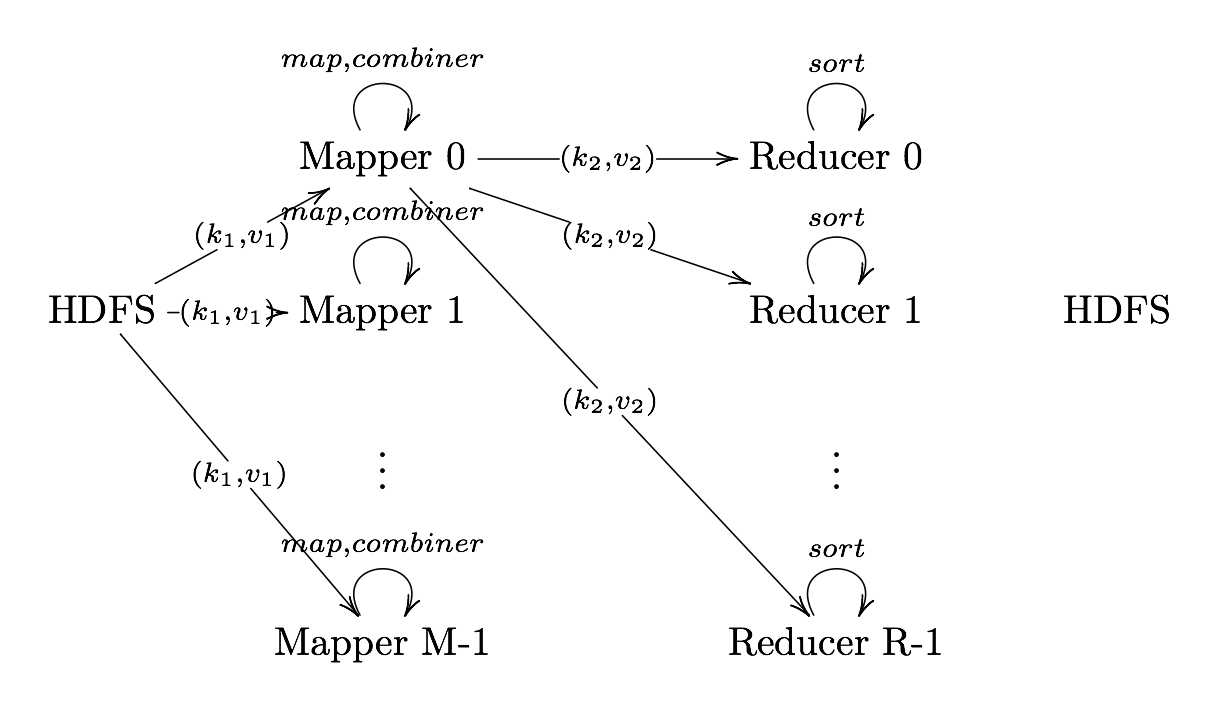
Reduce
Reduce User Defined Function that aggregates data (v) according to keys
(k) to send key-value pairs to output
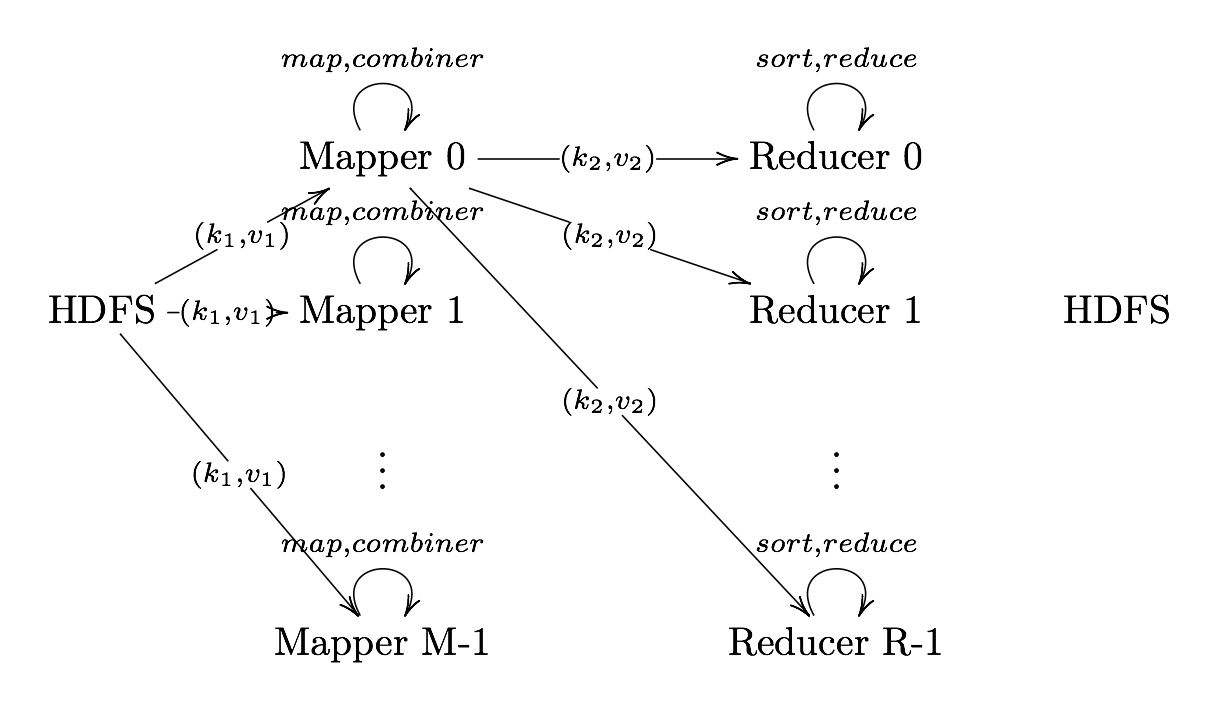
Output Format
Output Format Translates final key-value pairs to file format (tab-seperated
by default).
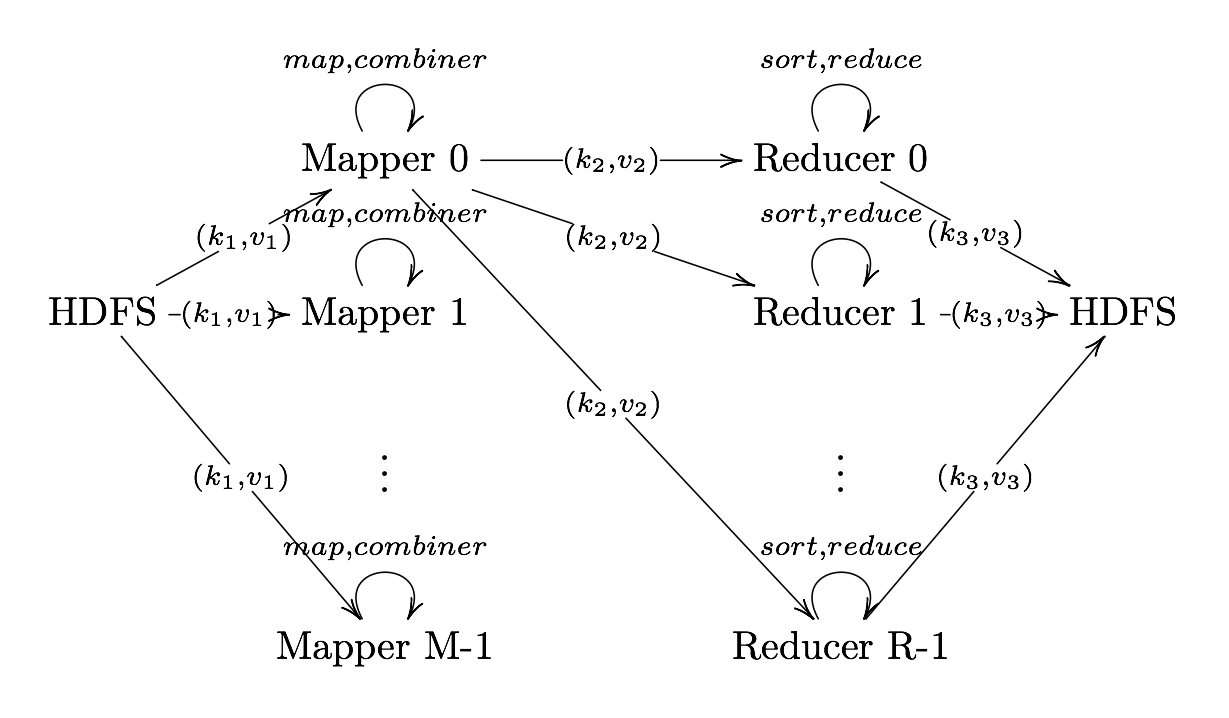
MapReduce Example: Word Count
 Image Source: Xiaochong Zhang’s Blog
Image Source: Xiaochong Zhang’s Blog
HDFS Operation
HDFS (Hadoop File System): A distributed file system designed to store huge streamable files running on commodity hardware.
Distributed File System: A file system that manages and stores files across a network of computer allowing files to be parititioned and stored across multiple computer nodes.
Community Hardware: Commonly available hardware. i.e. the computer in front of you.
Huge Files: File sizes from 100MB to petabytes.
Streamable: Documents in HDFS must be able to be partitioned where each partition can be read independently.
A LaTeX document is NOT streamable as the begining of the document defines parameters that are used throught the whole document A comma seperated value (CSV) text document IS streamable as it is readable from any parition of the document
HDFS is not very good with:
-
Low-latency requirements: HDFS is designed with high throughput in mind, usually giving up low-latency access for higher throughput in the design decisions.
-
Lots of small files: The namenode holds the filesystem metadata in main memory, meaning more files in the system means more memory needed in the namenode. Too many files can slow down the cluster or create a system crash.
-
Best to either concatonate files together or compress the files into a compression format that is partitionable (each HDFS block is independently readable)
-
YARN (MapReduce 2) has less problems with lots of small files but is a problem
-
-
Arbitrary file modifications: Files in HDFS can only be written to by a single writer by appending to the end of the file. The file can only be changed at the end as otherwise it would have to shift all of the other bits in the file (including other blocks) around.
HDFS Concepts
HDFS Block: Data stored in HDFS is broken into chucks, 64 MB by default, but 128 MB or 256MB are commonly used, which are spread accross various nodes in HDFS. HDFS blocks are best utitilized by having them evenly distributed across the cluster and sufficiently large to justify creating a JVM for each map task.
The block size is a balance of reduction of head seeks on disk, RAM memory usage of bringing in blocks for map tasks, and distributing the blocks of the file across the cluster
A file smaller than the block will not occupy a full block’s worth of underlying storage
Filesystem maintaince tools fsck can be used to work on blocks
HDFS Federation: For YARN (Hadoop 2.x) allows a cluster to have multiple namenodes which manages mutually exclusive potions of the filesystem namespace.
One NameNode might manage files/directories under /user and another manage /share
Manages a namespace volume: metadata of namespace, block pool (all blocks for files in namespace).
They are independent: if one NameNode fails, the others will still work just fine.
Balancer: HDFS data is not always distributed evenly across the cluster, the balancer moves blocks across the cluster to create a rough balance.
Keep one of the replicas of a block on the same node that it is writing the block
One of the replicas is placed in the same rack as IO is preformed
Spread different replicas across racks to ensure no data loss with loss of a rack (one replica on a different rack)
Failure Recovery
There are several ways that a MapReduce job may fail. Failure recovery is thus built into Hadoop:
- A task failing.
- Exception is thrown. i.e. A corrupt block being read.
- Node running out of memory.
- A task operating too long without a status update.
- A node failing (going offline).
- A NameNode failing (the worst point of failure).
Task Failing
If a map or reduce throws a exeception and it isn’t caught in code, then the task fails.
By default, if a map task fails, then it is first rerun on the same node then tried one last time on a different node.
By default, if a task fails 3 times then the job fails.
Possible Causes of exceptions:
Reading a corrupt block
Handle the exception in code (catch the exception)
A bad record can be skipped by enabling skipping mode using SkipBadRecords
class
Bad formatting of the file Ensure correct formatting of the file Handle problems in code
Node running out of memory Write memory efficient code
Lack of Updates
After 10 mins, by default, of no updates from a task Hadoop tries to kill the task and rerun the task while running procedures to ensure consistency.
Ensure regular updates: either updating a counter, or writing to stderr (which is then sent to the client) - This is really important for monte carlo simulations on hadoop.
Node Failing
If a DataNode fails, Hadoop tries isolating the node from the system and reassigning tasks that DataNode was operating on.
NameNode Failing
If a NameNode fails then the whole system (or at least a partition of it for 2.x) is down. The system recovers by setting up a new NameNode via the information in the Secondary NameNode as well as the edit logs. However since there is a lag between the NameNode’s operation and edit logs there is almost always data loss after recovery.
- One cause of NameNode failure is too many files in the system:
- The NameNode keeps all metadata for HDFS files in memory, more files means more memory is needed and NameNode failing due to lack of memory.
- It is HIGHLY recommended to keep most if not all data for a MapReduce job in a single file
With Hadoop 1.x can take about 30 mins for a new NameNode to be setup while Hadoop 2.x usually takes a min or two.
Hadoop Operations
Running Hadoop Jobs
Three basic ways of runing MapReduce jobs:
- Java MapReduce MapReduce Job written in Java
- Most efficient method
- Running Hadoop Streaming with other languages: C++, Python, etc.
- Easiest to use but least efficient interface
- Hadoop Pipes: C++ interface using sockets between Java and C++
Java MapReduce
Hadoop is written in Java code, thus one of the main ways of running MapReduce jobs is with Java.
$ hadoop jar <java file> [mainClass] args...
Hadoop Streaming
Hadoop Streaming allows Hadoop to use any programming languages with stdin, stdout: C++, Python, Perl, etc.
$ hadoop jar ${HADOOP_HOME}/share/hadoop/tools/lib/hadoop-streaming-*.jar \
-input <InputDirs> \
-output <OutputDir> \
[-file <MapperFileToBeSent>] \
-mapper <MapperFile> \
[-file <ReducerFileToBeSent>] \
-reducer <ReducerFile>
Hadoop Cheatsheet gives an outline of how to use this
Remember any files to be used must be sent using -file option (the mapper and reducer nodes need a copy of the files)
Hadoop Streaming: Ver 1.x vs 2.x
Hadoop Streaming for version 1.x can only use text for stdin and stdout, while 2.x is not.
1.x This means that stdin takes in text and then break the text back into the datatypes needed for computations.stdout is a print statement with a tab character seperating keys (\t)
2.x Can do text as well as stream objects Python would use emit() function to pass along each key-value pair instead of printing like in 1.x
Hadoop Pipes
We can connect to Hadoop C++ via pipes operator. Pipes makes a socket connect from Java to C++.
We can run a pipes job by the command:
hadoop pipes \
-input inputPath \
-output outputPath \
-program path/to/C++/executable
MapReduce Web UI
For Hadoop you can check on the Hadoop system using the systems web UI. For the local node cluster, the web site URL is:
http://localhost:50070/dfshealth.jsp
http://localhost:8088/cluster
Hadoop Commands
Common HDFS File Commands
Commands for HDFS is very similar to bash
$ hdfs [--config confdir] dfs <Cmd> <args>
| Cmd | args | Description | args Description | |
|---|---|---|---|---|
-ls |
-R |
path(s) | List files in path(s) | -R =including subdirs |
-cat |
path(s) | Print files in path(s) | ||
-mkdir |
-p |
path | Create directory | -p =including parents |
-rm |
-r |
file(s)/dir | Remove files | -r =including subdirectories |
-put |
localFiles HDFSdir | Copy localFiles to HDFSdir |
| Cmd | args | Description | args Description | |
|---|---|---|---|---|
-get |
HDFSfiles localDir | Copy HDFSfiles to localDest | ||
-getmerge |
HDFSfiles localDir | Concatenate HDFSfiles to localDest |
More commands are on the cheatsheet attached
HDFS File Command Examples
$ hdfs dfs -ls
15/02/28 14:02:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 2 items
drwxr-xr-x - darrellaucoin supergroup 0 2015-01-20 16:33 input
drwxr-xr-x - darrellaucoin supergroup 0 2015-02-15 16:31 out
$ echo "Hello world!" > ~/example.txt
$ hdfs dfs -put ~/example.txt /user/darrellaucoin
15/02/28 14:02:38 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
$ hdfs dfs -ls
15/02/28 14:02:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Found 3 items
-rw-r--r-- 1 darrellaucoin supergroup 13 2015-02-28 14:02 example.txt
drwxr-xr-x - darrellaucoin supergroup 0 2015-01-20 16:33 input
drwxr-xr-x - darrellaucoin supergroup 0 2015-02-15 16:31 out
$ hdfs dfs -cat example.txt
15/02/28 14:02:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Hello world!
$ hdfs dfs -rm example.txt
15/02/28 14:02:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/02/28 14:03:00 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes.
Deleted example.txt
Hadoop Streaming Command
$ hadoop [--config confdir] jar ${HADOOP_HOME}/share/hadoop/tools/lib/hadoop-
streaming-*.jar \
[genericOptions] <streamingOptions>
####streamingOptions
| Cmd | args | Description |
|---|---|---|
-input |
dir/filename | Input location |
-output |
dir | Output location |
-mapper |
executable | Mapper executable |
-reducer |
executable | Reducer executable |
-file |
filename | File that needs to be sent to clusters (Mappers, reducer, combiners and other files they need) |
$ hadoop [--config confdir] jar ${HADOOP_HOME}/share/hadoop/tools/lib/hadoop-
streaming-*.jar \
[genericOptions] <streamingOptions>
| Cmd | Description | |
|---|---|---|
-combiner |
executable | Combiner executable |
-inputformat |
JavaClassName | Java Class specifying format of key-value pairs of text class for input. TextInputFormat is default |
-outputformat |
JavaClassName | Java Class specifying format of key-value pairs of text class for output. TextOutputFormat is default |
-numReduceTasks |
integer | The number of reducers to use |
$ hadoop [--config confdir] jar ${HADOOP_HOME}/share/hadoop/tools/lib/hadoop-
streaming-*.jar \
[genericOptions] <streamingOptions>
Be sure to place the generic options before the streaming options, otherwise the command will fail.
####Some genericOptions
| Parameter | Description | |
|---|---|---|
-D |
property=value | Set hadoop property to value |
-files |
file1, file2, … | Comma-separated files to be copied to the |
| Map/Reduce cluster |
MapReduce Properties
Hadoop is highly configurable, both on the admin and MapReduce job side. Most options are for performance tuning but some can do significantly change a MapReduce job - i.e. change the input split to number of lines instead block size (useful for Monte Carlo simulations and web crawling multiple websites)
Debugging Hadoop
Hadoop can run in 3 different modes, 2 of which are are useful for debugging: 1. Local: Hadoop installed an a single machine, everything is run in a single JVM instance, thus making tracking down problems easier. 2. Pseudo-Distribution: Essentially a 1 node cluster. Useful for finding problems related to the distributed nature of Hadoop. 3. Full-Distribution: A hadoop system installed on a cluster.
Counters
Hadoop has various counters associated with a job (i.e. how many map, reduce tasks have run etc.).
Counters have the dual purpose of keeping the system informed that a task is still running as well as metrics on a jobs progress. Custom counters can also be written in Java.
Built-in Counters
For Hadoop 2.x
| Group | Name/Enum |
|---|---|
| MapReduce Task Counters | org.apache.hadoop.mapreduce.TaskCounter |
| Job Counters | org.apache.hadoop.mapreduce.JobCounter |
| Filesystem Counters | org.apache.hadoop.mapreduce.FileSystemCounter |
| File Input Format Counters | org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter |
| File Output Format Counters | org.apache.hadoop.mapreduce.lib.output.FileOutputFormatCounter |
Task Counters
| Counter | Description |
|---|---|
| MAP_INPUT_RECORDS | Number of input records consumed |
| COMBINE_INPUT_RECORDS | Number of input records consumed by combiners |
| REDUCE_INPUT_GROUPS | Number of distinct key groups consumed by reducers |
| REDUCE_INPUT_RECORDS | Number of input records consumed by reducers |
| MAP_OUTPUT_RECORDS | Number of output records by mappers |
| COMBINE_OUTPUT_RECORDS | Number of output records produced by combiners |
| REDUCE_OUTPUT_RECORDS | Number of output records produced by reducers |
| Counter | Description |
|---|---|
| MAP_INPUT_RECORDS | Number of input records consumed |
| COMBINE_INPUT_RECORDS | Number of input records consumed by combiners |
| REDUCE_INPUT_GROUPS | Number of distinct key groups consumed by reducers |
| REDUCE_INPUT_RECORDS | Number of input records consumed by reducers |
| MAP_OUTPUT_RECORDS | Number of output records by mappers |
| COMBINE_OUTPUT_RECORDS | Number of output records produced by combiners |
| REDUCE_OUTPUT_RECORDS | Number of output records produced by reducers |
| MAP_SKIPPED_RECORDS | Number of skipped input records |
| MAP_INPUT_BYTES | Number of uncompressed bytes consumed |
| MAP_OUTPUT_BYTES | Number of uncompressed bytes by mappers |
| MAP_OUTPUT_MATERIALIZED_BYTES | Number of bytes by mappers to HD |
| REDUCE_SKIPPED_GROUPS | Number of distinct keys skipped by reducers |
| REDUCE_SKIPPED_RECORDS | Number of input records skipped by reducers |
| REDUCE_SHUFFLE_BYTES | Number of map output bytes copied by shuffle to reducers |
| SPILLED_RECORDS | Number of records spilled to disk by mappers and reducers |
| CPU_MILLISECONDS | Cumulative CPU time for a task in miliseconds |
| PHYSICAL_MEMORY_BYTES | The physical memory being used by a task in bytes |
| VIRTUAL_MEMORY_BYTES | The virtual memory being used by a task in bytes |
| COMMITTED_HEAP_BYTES | Total amount of memory available in the JVM in bytes |
| SHUFFLED_MAPS | Number of files transferred from mappers to reducers by shuffle |
| FAILED_SHUFFLE | Number of failed file transfers to reducers by shuffle |
| MERGED_MAP_OUTPUTS | Number of map outputs that have been merged in reducer |
| BYTES_READ | Number of bytes read by mapper and reducers |
| BYTES_WRITTEN | Number of bytes written by mappers and reducers |
| SPLIT_RAW_BYTES | Bytes of input-split objects read by mappers |
| GC_TIME_MILLIS | Milliseconds for garbage collection in tasks |
File Input Format Counters
| Counter | Description | ||-| | BYTES_READ | Bytes read by mappers |
File Output Format
| Counter | Description |
|---|---|
| BYTES_WRITTEN | Bytes written reducers or (for map-only jobs) mappers |
Job Counters
| Counter | Description |
|---|---|
| TOTAL_LAUNCHED_MAPS | Number of map launched tasks |
| TOTAL_LAUNCHED_REDUCES | Number of launched reduce tasks |
| TOTAL_LAUNCHED_UBERTASKS | Number of uber tasks |
| NUM_UBER_SUBMAPS | Number of maps in uber tasks |
| NUM_UBER_SUBREDUCES | Number of reduces in uber tasks |
| NUM_FAILED_MAPS | Number of failed maps |
| NUM_FAILED_REDUCES | Number of failed reduces |
| NUM_FAILED_UBERTASKS | Number of failed uber tasks |
| DATA_LOCAL_MAPS | Number of data local mappers |
| RACK_LOCAL_MAPS | Number of rack local mappers |
| OTHER_LOCAL_MAPS | Number of non-local rack mappers |
| SLOTS_MILLIS_MAPS | Total time running mappers (milliseconds) |
| SLOTS_MILLIS_REDUCES | Total time running reducers (milliseconds) |
Hadoop Streaming and R
Setting Environment Settings for R
Either run the following code in R, each time you need to do a Hadoop job:
#The Hadoop installation directory
Sys.setenv("HADOOP_PREFIX"="/usr/local/hadoop/2.*")
#The location for Hadoop executable
Sys.setenv("HADOOP_CMD"="/usr/local/hadoop/2.*/bin/hadoop")
#The location of hadoop streaming jar file
Sys.setenv("HADOOP_STREAMING"="/usr/local/hadoop/2.*/share/hadoop/tools/lib
/hadoop-streaming-2.*.jar")
or include the following into ~/.bashrc file
export HADOOP_PREFIX=${HADOOP_HOME}
export HADOOP_CMD=${HADOOP_HOME}/bin/hadoop
export HADOOP_STREAMING=${HADOOP_HOME}/share/hadoop/tools/lib/hadoop-
streaming-*.jar
rmr2: mapreduce
mapreduce Defines and executes a map reduce job. (Pkg rmr2)
mapreduce(input, output = NULL, map = to.map(identity),
reduce = NULL, combine = NULL,
input.format = "native",
output.format = "native",
vectorized.reduce = FALSE,
in.memory.combine = FALSE,
backend.parameters = list(),
verbose = TRUE)
input Can be:
A set of file paths in HDFS A Big Data Object (a stub of information on some data in HDFS) A list of a combination of both
output A path to the destination folder on HDFS; if missing, a Big Data Object is returned.
map An optional R map function that returns either NULL or a keyval object
reduce An optional R reduce function that returns either NULL or a keyval object
combine refers to:
A function with the same signature and possible return values as the reduce function, or
TRUE, which means use the reduce function as combiner.
NULL means no combiner is used.
input.format Input format specification, see make.input.format

output.format Output format specification, see make.output.format

rmr2: keyval
keyval(key, val) Function that returns key-value pair, only val can ever be NULL. This is what mapper, reducer and combiner functions return.
rmr2: from.dfs
from.dfs Read R objects from HDFS.
from.dfs(input, format = "native")
input A valid path to HDFS or a big.data.object
format Either
A string naming the format, or
A value returned by the function make.input.format
rmr2: to.dfs
to.dfs Write R objects to HDFS and return a Big Data Object. (Useful for test purposes only)
to.dfs(kv, output = dfs.tempfile(), format = "native")
input A valid path to HDFS or a big.data.object
format Either
A string naming the format, or
A value returned by the function make.input.format
rmr2: keys( ) and values( )
keys Get keys from a big data object or HDFS file path
keys(kv)
values Get values from a big data object or HDFS file path
values(kv)
rmr2: Preamble
For rmr2 to work, some variables need to be set in bash:
Sys.setenv("HADOOP_PREFIX"="/usr/local/hadoop/2.2.0")
Sys.setenv("HADOOP_CMD"="/usr/local/hadoop/2.2.0/bin/hadoop")
Sys.setenv("HADOOP_STREAMING"=
"/usr/local/hadoop/2.2.0/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar")
Some Useful R Functions
system
system Invokes OS command specified by the character string command. (Pkg base)
system(command, intern = FALSE,
ignore.stdout = FALSE, ignore.stderr = FALSE,
wait = TRUE, input = NULL, show.output.on.console = TRUE,
minimized = FALSE, invisible = TRUE)
command Character string to be invoked in terminal.
intern a logical (not NA) which indicates whether to capture the output of the command as an R character vector.
ignore.stdout, ignore.stderr a logical (not NA) indicating whether messages written to ‘stdout’ or ‘stderr’ should be ignored.
wait a logical (not NA) indicating whether the R interpreter should wait for the command to finish, or run it asynchronously. This will be ignored (and the interpreter will always wait) if intern = TRUE.
input if a character vector is supplied, this is copied one string per line to a temporary file, and the standard input of command is redirected to the file.
show.output.on.console, minimized, invisible arguments that are accepted on Windows but ignored on this platform, with a warning.
Example: Command for hadoop to remove previous contents of out
system("${HADOOP_CMD} fs -rm -r /user/darrellaucoin/out")
file.path
file.path Construct a path from components to be easily translated accross different OS (Mac, Windows, Linux). (Pkg base)
file.path(...)
… character vectors
Example: Command for hadoop to remove previous contents of out
hdfs.root <-'/user/darrellaucoin'
input <- file.path(hdfs.root, 'input')
strsplit
strsplit Split elements of a character vector x into substrings, split with matches to the regular expression in split argument. (Pkg base)
strsplit(x, split, fixed = FALSE, perl = FALSE, useBytes = FALSE)
x character vector
split character vector containing regular expressions to tell when to break the substring. If split has length 0, x is split to individual characters.
perl logical. Should perl-compatible regular expressions be used?
useBytes logical. Should matching be done byte by byte?
Example:
str = 'this is a string'
strsplit(str, split = ' ')
list
list construct a list from the objects. A list is like a vector that can have different datatypes.
list(x, all.names = FALSE)
… objects to coerced into a list
x object to coerced into a list
all.names logical. whether to copy all values or (default) only those whose names do not begin with a dot.
Example:
a.list = list(1,2,3,'string', 2.23, lm(y~x))
unlist
unlist Simplifies a list structure x to a vector containing atomic components which occur in x. (Pkg base)
unlist(x, recursive = TRUE, use.names = TRUE)
x a list or vector
recurvisve logical
use.names logical. Should names be preserved? Example:
vec = unlist(a.list)
write
write
write(x, file = "data",
ncolumns = if(is.character(x)) 1 else 5,
append = FALSE, sep = " ")
x the data to be written
file connection or character string naming the file to written to.
For Hadoop, we want to write to standard error (stderr()) for it to go
to the client.
ncolumns number of columns to write the data in
append if TRUE the data are appended to the connection.
sep string used to serparate the columns
Example:
write("prints to stderr", stderr())
Debugging Hadoop within R
Debugging is essential to running a MapReduce job and ensuring everything is working correctly. As such, we have two functions to help us debugg code:
- rmr.options when we are running on hadoop (either in pseudo-distribution or full-distribution mode). When in hadoop mode, there are several options to collect information to help debug.
When trying to look for bugs it is usually best look in local mode to find potential problems within R, then failing that look in pseudo-distributed mode for any problems (connections problems between R and Hadoop etc.) Profiling works by writing out the call stack every interval seconds, to the file specified
- Rprof when we are running on local mode (using
rmr.options(backend = "local")). When local mode is turned on, hadoop is never run but a simulation of hadoop entirely within R is run, as such Rprof is used to collect any debugging information we might need.
rmr.options Set and get package options. (Pkg rmr2)
rmr.options(backend = c("hadoop", "local"),
profile.nodes = c("off", "calls", "memory", "both"),
hdfs.tempdir = "/tmp",
exclude.objects = NULL,
backend.parameters = list())
… Names of options to get values of, as length of one character vectors.
backend Use either hadoop, or the current R interpreter, sequentially, for learning and debugging.

profile.nodes Collect profiling and memory information when running additional R interpreters (besides the current one) on the cluster. No effect on the local backend, use Rprof instead. For backward compatibility, “calls” is equivalent to TRUE and “off” to FALSE

Rprof when we are running on local mode (using rmr.options(backend =
"local") ). When local mode is turned on, hadoop is never run but a simulation
of hadoop entirely within R is run, as such Rprof is used to collect any
debugging information we might need.
summaryRprof
Functions will only be recorded in the profile log if they put a context on
the call stack
Individual statements will be recorded in the profile log if line.profiling is set to TRUE, and if the code being executed was parsed with source references.
Hadoop Examples
Word Count
We want a word count in a text (or group of texts).
Sys.setenv("HADOOP_PREFIX"="/usr/local/hadoop/2.5.2")
Sys.setenv("HADOOP_CMD"="/usr/local/hadoop/2.5.2/bin/hadoop")
Sys.setenv("HADOOP_STREAMING"=
"/usr/local/hadoop/2.5.2/share/hadoop/tools/lib/hadoop-streaming-2.5.2.jar")
library(rmr2)
library(data.table)
system('${HADOOP_CMD} fs -rm -r /user/darrellaucoin/out/')
map=function(k,lines) {
words.list = strsplit(lines, ' ')
words = unlist(words.list)
return( keyval(words, 1) )
}
reduce=function(word, counts) {
keyval(word, sum(counts))
}
mapreduce(input='/user/darrellaucoin/input/War_and_Peace.txt',
output='/user/darrellaucoin/out',
input.format="text",
map=map,
reduce=reduce
)
count = from.dfs('/user/darrellaucoin/out')
results = as.data.table(count)
setnames(results, c('word', 'count'))
results[order(results$count, decreasing=T), ]
Linear Regression
To understand the MapReduce framework, lets solve a familar problem of Linear Regression. For Hadoop/MapReduce to work we MUST figure out how to parallelize our code, in other words how to use the hadoop system to only need to make a subset of our calculations on a subset of our data.
Assumption: The value of p, the number of explanatory variables is small enough for R to easily handle i.e.
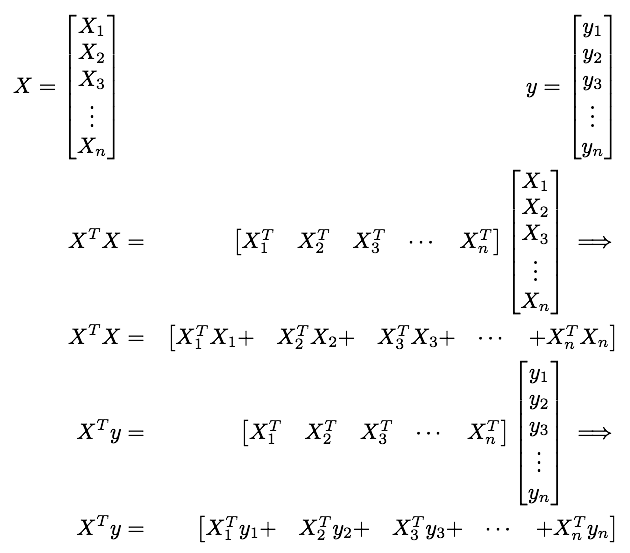
We know from linear regression, that our estimate of $\hat{\beta}$:
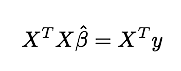
$\left(X^{T}X\right){p\times p}$ and $\left(X^{T}y\right){p\times1}$ is small enough for R to solve for $\hat{\beta}$, thus we only need $X^{T}X,X^{T}y$ to get $\hat{\beta}$.
To break up this calculation we break our matrix $X$ into submatricies $X_{i}$:
Sys.setenv("HADOOP_PREFIX"="/usr/local/hadoop/2.5.2")
Sys.setenv("HADOOP_CMD"="/usr/local/hadoop/2.5.2/bin/hadoop")
Sys.setenv("HADOOP_STREAMING"=
"/usr/local/hadoop/2.5.2/share/hadoop/tools/lib/hadoop-streaming-2.5.2.jar")
library(rmr2)
library(data.table)
#Setup variables
p = 10
num.obs = 200
beta.true = 1:(p+1)
X = cbind(rep(1,num.obs), matrix(rnorm(num.obs * p),
ncol = p))
y = X %*% beta.true + rnorm(num.obs)
X.index = to.dfs(cbind(y, X))
rm(X, y, num.obs, p)
map.XtX = function(., Xi) {
Xi = Xi[,-1] #Get rid of y values in Xi
keyval(1, list(t(Xi) %*% Xi))
}
map.Xty = function(., Xi) {
yi = Xi[,1] # Retrieve the y values
Xi = Xi[,-1] #Get rid of y values in Xi
keyval(1, list(t(Xi) %*% yi))
}
Sum = function(., YY) {
keyval(1, list(Reduce('+', YY)))
}
The reason we are returning a list in the map function is because otherwise Reduce will only return a some of the elements of the matricies.
list prevents this by Reduce iterating though the elements of the list (the individual $X_{i}^{T}X_{i}$ matricies) and applying the binary function ‘+’ to each one.
list is used in the reduce function Sum because we will also use this as
a combiner function and if we didn’t use a list we would have the same problem
as above.
XtX = values(from.dfs(
mapreduce(input = X.index,
map = map.XtX,
reduce = Sum,
combine = TRUE)))[[1]]
Xty = values(from.dfs(
mapreduce(
input = X.index,
map = map.Xty,
reduce = Sum,
combine = TRUE)))[[1]]
beta.hat = solve(XtX, Xty)
print(beta.hat)
15/02/28 16:58:19 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable packageJobJar: [/usr/local/hadoop/2.5.2/hdfs/tmp/hadoop- unjar2544978824408962002/] [] /var/folders/p3/jb65k2x55g1brywqlf6m10p00000gn/T/streamjob622039766772640798.jar tmpDir=null 15/02/28 16:58:20 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 15/02/28 16:58:20 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 15/02/28 16:58:21 INFO mapred.FileInputFormat: Total input paths to process : 1 15/02/28 16:58:21 INFO mapreduce.JobSubmitter: number of splits:2 15/02/28 16:58:22 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1425160610091_0002 15/02/28 16:58:22 INFO impl.YarnClientImpl: Submitted application application_1425160610091_0002 15/02/28 16:58:22 INFO mapreduce.Job: The url to track the job: http://v1020-wn-6-180.campus- dynamic.uwaterloo.ca:8088/proxy/application_1425160610091_0002/ 15/02/28 16:58:22 INFO mapreduce.Job: Running job: job_1425160610091_0002 15/02/28 16:58:30 INFO mapreduce.Job: Job job_1425160610091_0002 running in uber mode : false 15/02/28 16:58:30 INFO mapreduce.Job: map 0% reduce 0% 15/02/28 16:58:39 INFO mapreduce.Job: map 50% reduce 0% 15/02/28 16:58:47 INFO mapreduce.Job: map 100% reduce 0% 15/02/28 16:58:54 INFO mapreduce.Job: map 100% reduce 100% 15/02/28 16:58:54 INFO mapreduce.Job: Job job_1425160610091_0002 completed successfully 15/02/28 16:58:54 INFO mapreduce.Job: Counters: 50 File System Counters FILE: Number of bytes read=413 FILE: Number of bytes written=311808 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=26712 HDFS: Number of bytes written=546 HDFS: Number of read operations=13 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=51344 Total time spent by all reduces in occupied slots (ms)=20704 Total time spent by all map tasks (ms)=12836 Total time spent by all reduce tasks (ms)=5176 Total vcore-seconds taken by all map tasks=12836 Total vcore-seconds taken by all reduce tasks=5176 Total megabyte-seconds taken by all map tasks=52576256 Total megabyte-seconds taken by all reduce tasks=21200896 Map-Reduce Framework Map input records=3 Map output records=3 Map output bytes=400 Map output materialized bytes=419 Input split bytes=186 Combine input records=3 Combine output records=3 Reduce input groups=1 Reduce shuffle bytes=419 Reduce input records=3 Reduce output records=3 Spilled Records=6 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=348 CPU time spent (ms)=0 Physical memory (bytes) snapshot=0 Virtual memory (bytes) snapshot=0 Total committed heap usage (bytes)=531628032 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=26526 File Output Format Counters Bytes Written=546 rmr reduce calls=2 15/02/28 16:58:54 INFO streaming.StreamJob: Output directory: /tmp/file72e60803cf9 15/02/28 16:58:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable 15/02/28 16:58:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable 15/02/28 16:58:59 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes. Deleted /tmp/file72e243880be 15/02/28 16:59:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable 15/02/28 16:59:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable 15/02/28 16:59:05 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
[,1]
[1,] 1.045835
[2,] 1.980511
[3,] 2.993829
[4,] 4.011599
[5,] 5.074755
[6,] 6.008534
[7,] 6.947164
[8,] 8.024570
[9,] 9.024757
[10,] 9.888609
[11,] 10.893023
Your Data isn’t THAT BIG
Hadoop has several difficulties and limitations:
Paradigm shift of MapReduce: re-vision (and recoding) algorithms into the paradigm of MapReduce
Debugging code is more difficult than just regular code
Data security isn’t as well defined as most SQL engines
Alternatives
Q: Is there a way of fitting the data in memory?
A gigabyte csv file can be loaded into memory on most computers
Q: Can the process be done reading lines from a file?
R and Python have functions like readLines that can read a file line by line
Q: Can a SQL server handle the information/calculation?
SQL doesn’t require all data to be loaded into memory to execute it’s queries SQL can handle queries over many Gigabytes of data
SQL tables can be indexed (unlike Hadoop) making for faster processing time
R packages like dplyr can translate some R-code into SQL queries and can
execute said code with a SQL backend
Can also execute SQL queries from R, importing the results into a
dataframe
PostgreSQL has an extension (MADlib) allowing Machine Learning algorithms to run over large datasets on PostgreSQL
Q: What if the data isn’t structured for SQL tables? i.e. JSON file, binary blobs
PostgreSQL does have a JSON datatype
Can process the file using a script, reading line by line and then write to file as needed