Big data tools
Popular Hadoop Projects
Hadoop: A distributed file system and MapReduce engine YARN.
Spark: An in-memory based alternative to Hadoop’s MapReduce which is better for machine learning algorithms.
Spark SQL, MLlib (machine learning), GraphX (graph-parallel computation), and Spark Streaming.
Storm: Distributed tool for processing fast, large streams of data.
Cassandra: NoSQL system implemented on Hadoop.
Hive: Allows users to create SQL-like queries (HQL) and convert them to MapReduce.
HCatalog: A centralized metadata management and sharing service for Hadoop, allowing a unified view of all data in Hadoop clusters.
Pig: An easy to learn hadoop-based language that is adept at very deep, very long data pipelines.
Mahout: A data mining library using the most popular data mining algorithms using the Map Reduce model.
Non-Hadoop Projects
NoSQL (Not Only SQL): A database that is not based storage and retrieval of tabular relations used in relational databases. Some can provide a distributed database.
Examples: MongoDB, CouchDB, Accumulo, and some NoSQL databases are implemented on Hadoop: Cassandra, HBase.
SQL: Can spill to disk allowing datasets to be larger than memory size.
MADlib: Machine learning library extension for PostgreSQL.
Hadoop Ecosystem
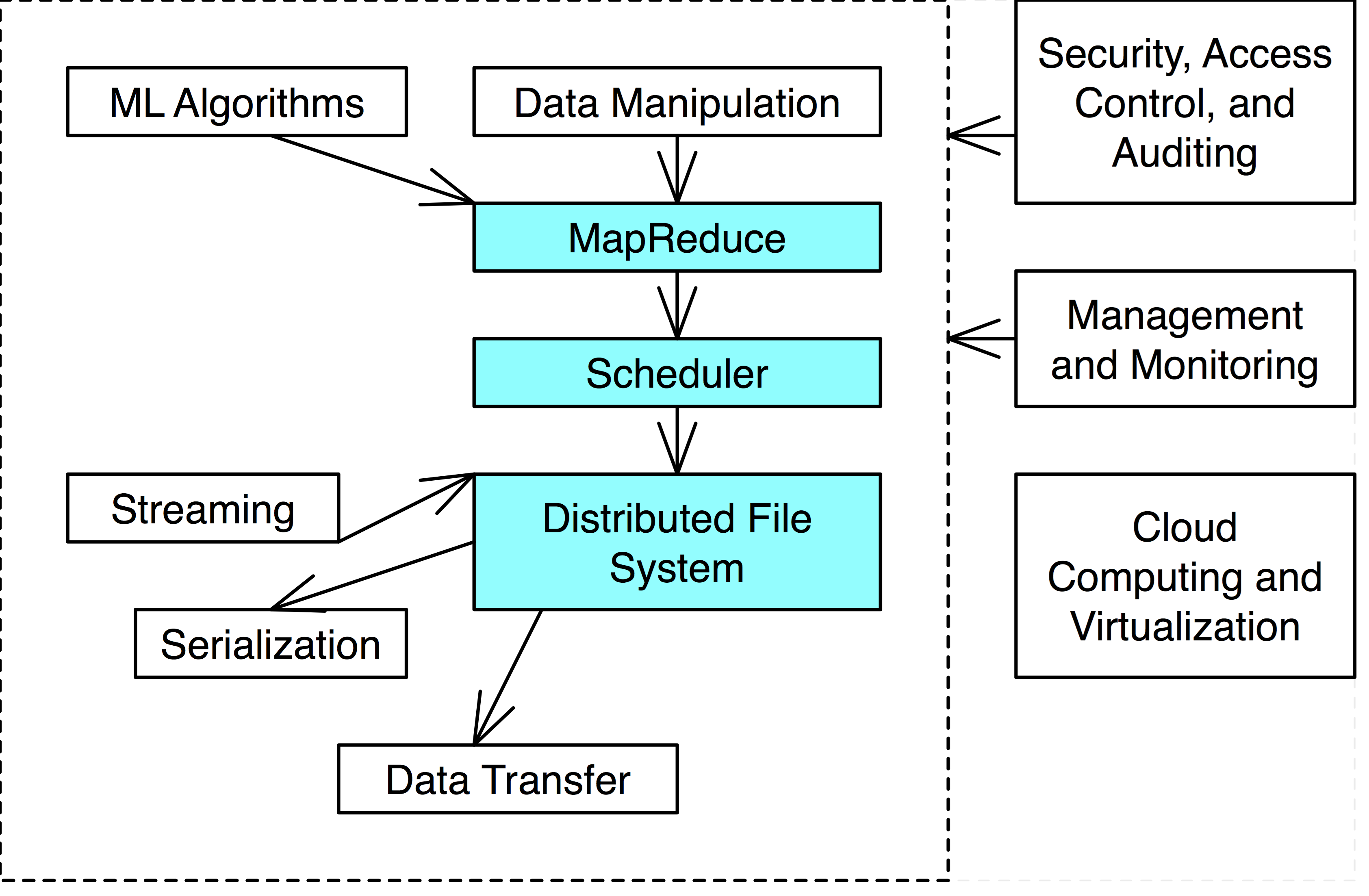
- The blue is the necessary components of a Hadoop Ecosystem
- Some tools provide several functionalities.
- i.e. Hadoop is a distributed file system with MapReduce engine and scheduler.
Distributed File System
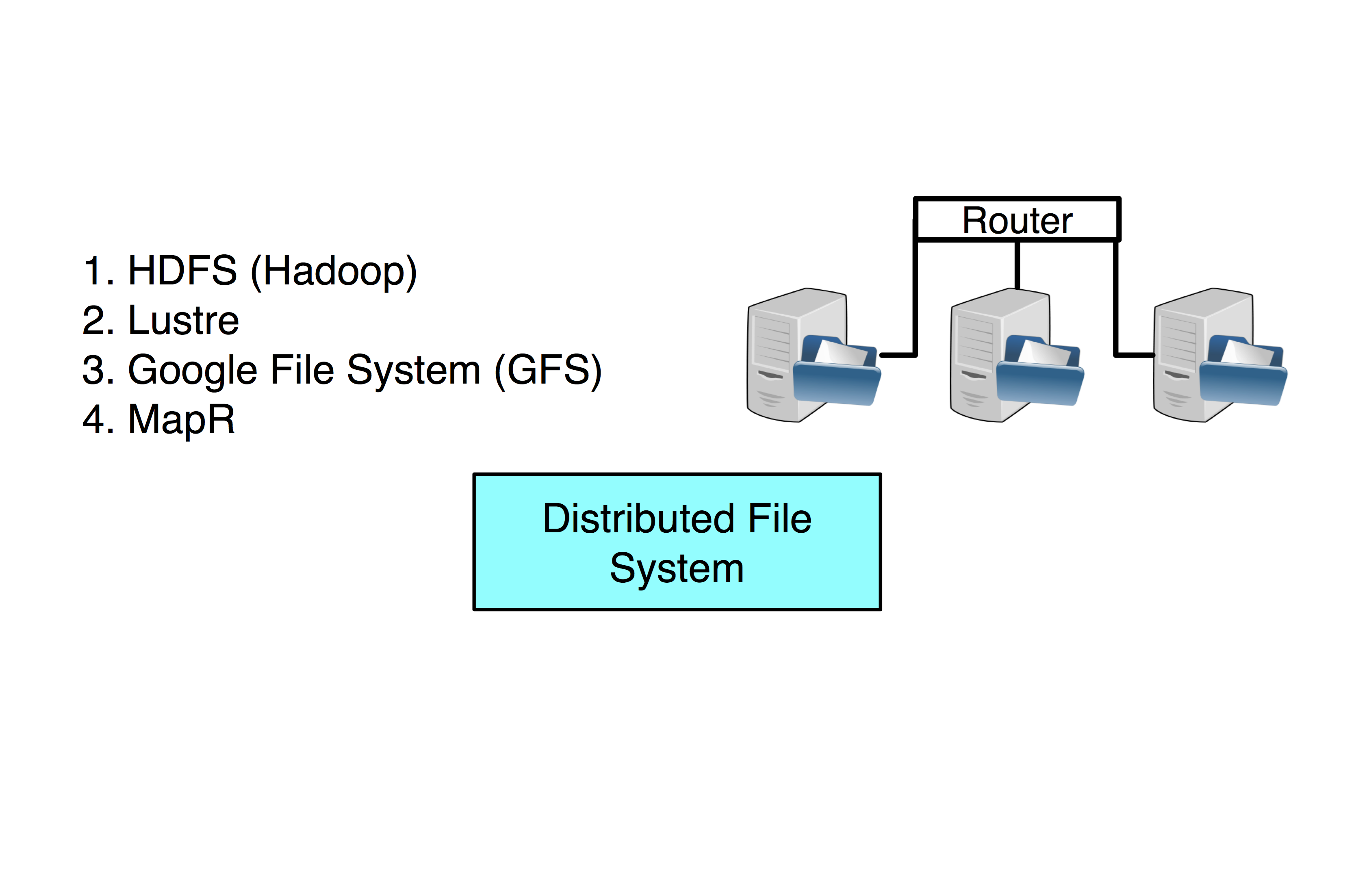
HDFS (Hadoop Distributed File System) is a distributed file-system across multiple interconnected computer systems (nodes).
- Data is stored across multiple hard drives.
Lustre: DFS used by most enterprise High Performance Clusters (HPC). Usually uses a shared networked drive.
Google File System (GFS): Google propriety distributed file system.
MapR: DFS inspired by HDFS but written in C++ instead of Java.
MapReduce
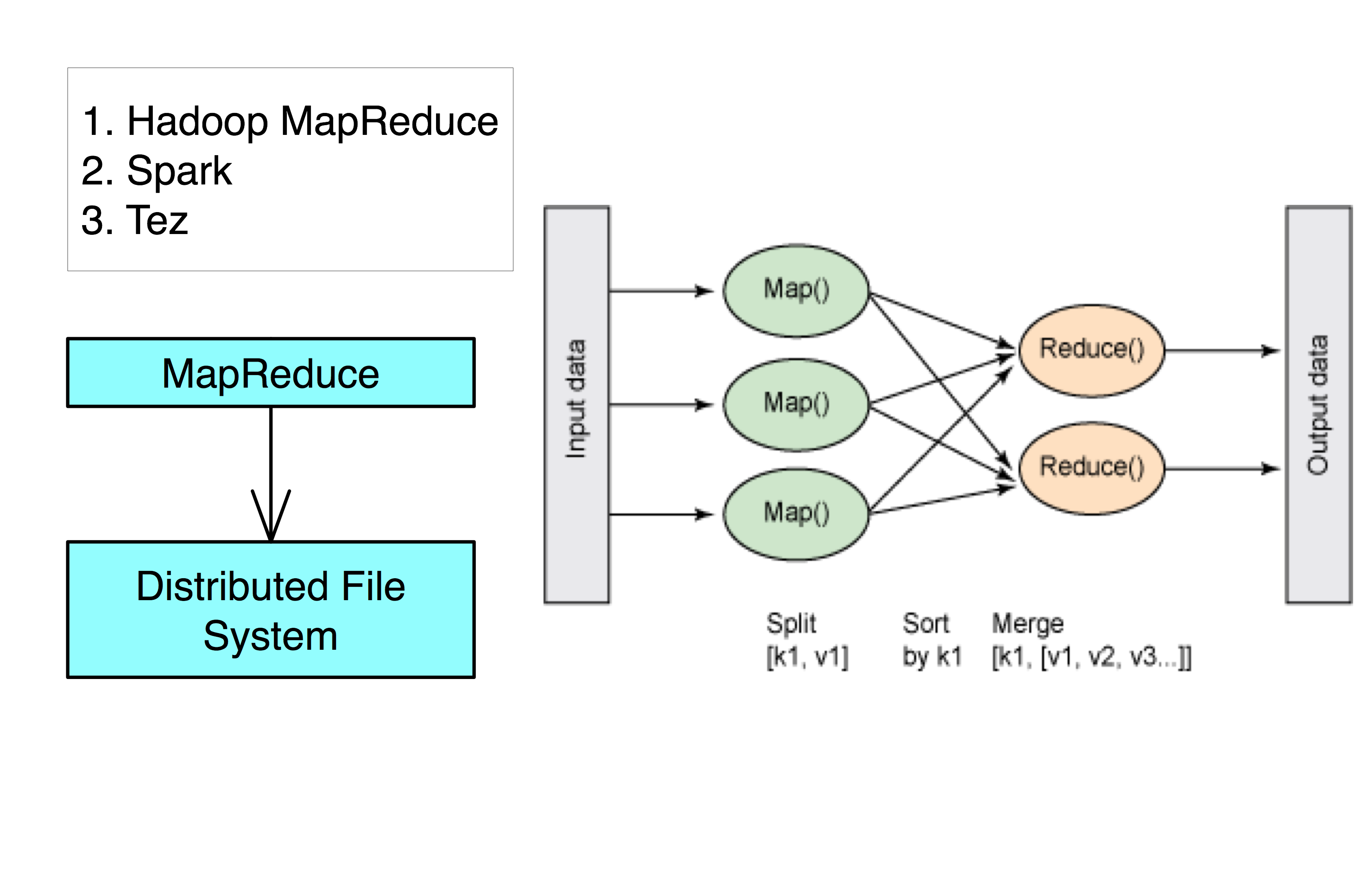
- MapReduce is the engine that processes data in a Hadoop Ecosystem.
- Spark and Tez uses a more flexiable in memory model of MapReduce which is better for Machine Learning algorithms.
Scheduler
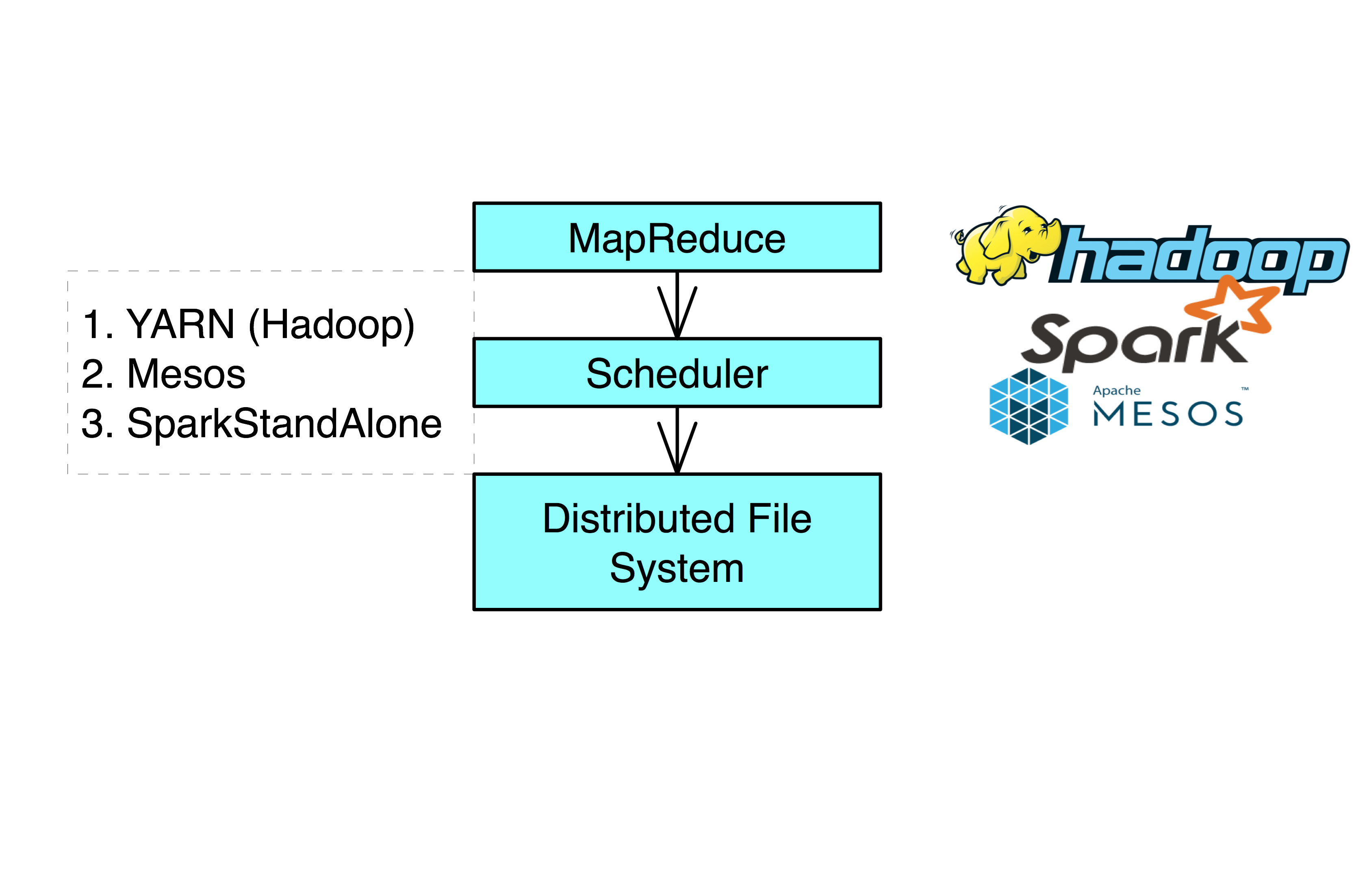
In order for multiple people to run on the same cluster, a scheduler is needed.
Data Manipulation
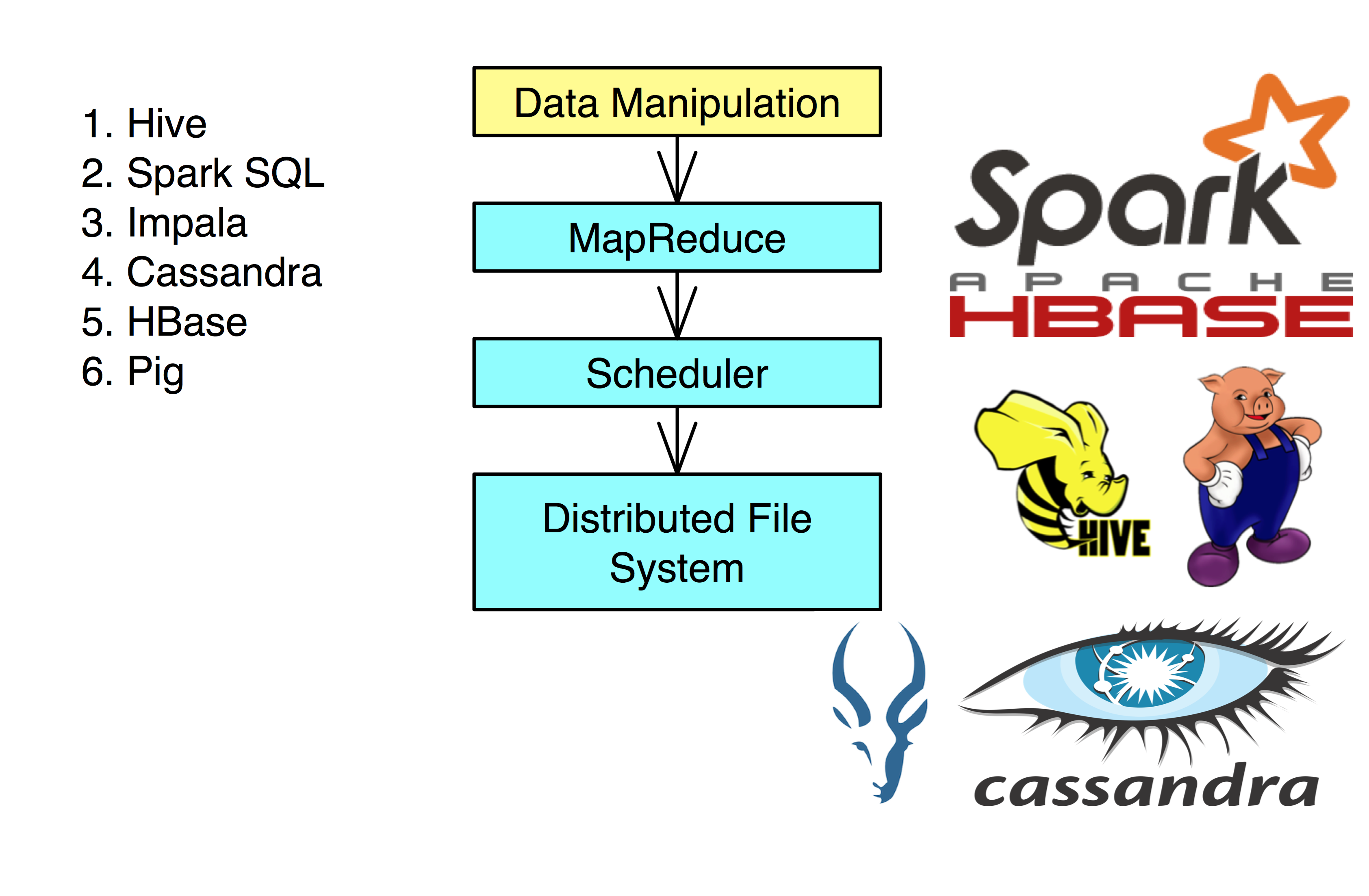
These are the tools to help parse, transform, and combine various datasets.
- Hive, Spark SQL, Impala, Cassandra, and HBase all use a SQL-like language to help manipulate data.
- Hive can be implemented using the Spark MapReduce Engine (significantly speeding it it’s processes).
Data Analysis
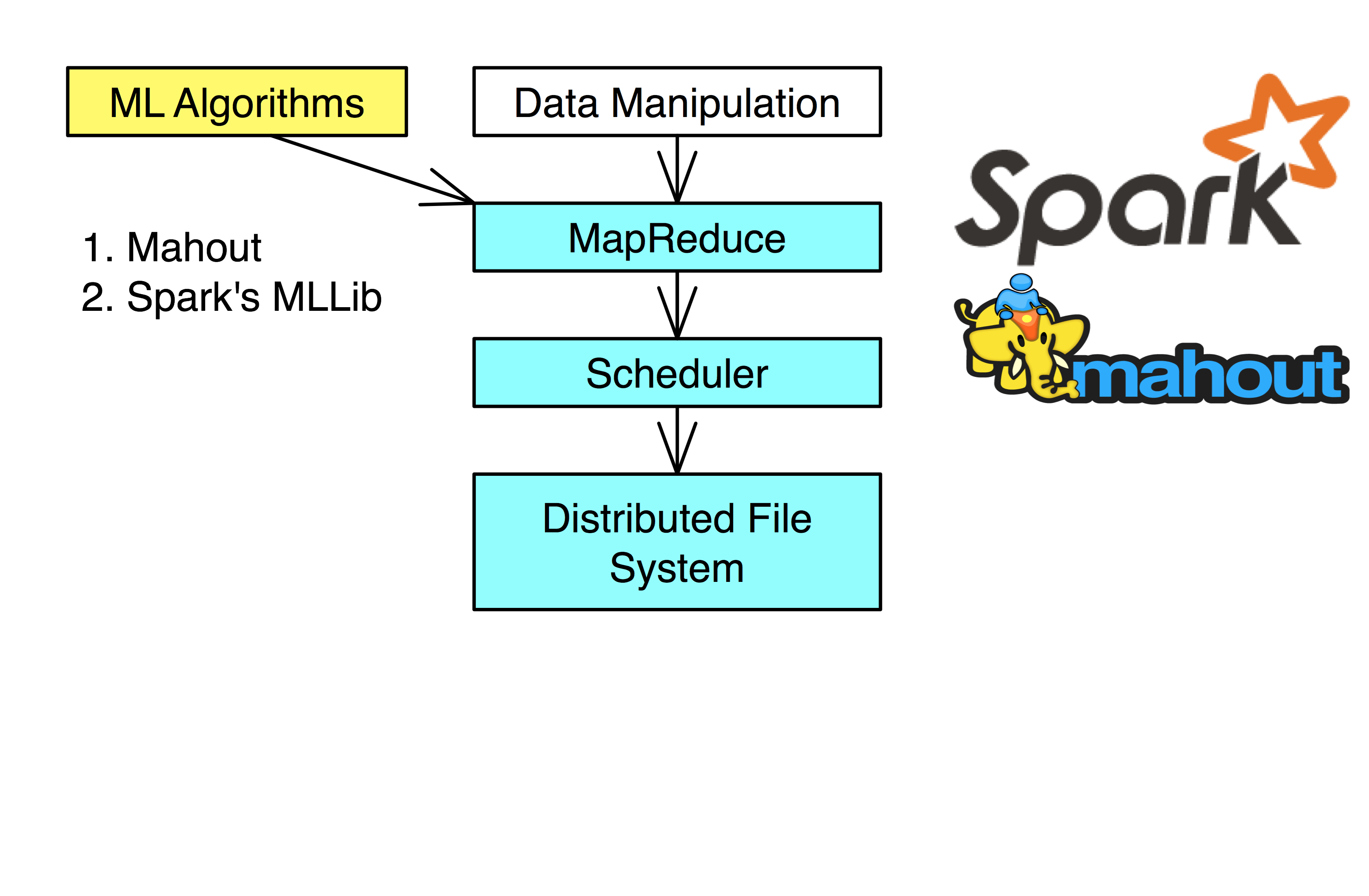
There are several Machine Learning algorithms already in place for the Hadoop Ecosystem.
- Mahout can be implemented on Spark, Tez, and Hadoop
- Spark also has GraphX, which uses graphs to perform analytics (PageRank, etc.)
There is also specialized tools:
Hadoop Image Processing Interface (HIPI): Image processing package helping to determine image similarity.
SpatialHadoop: Extension to process datasets of spatial data in Hadoop.
Serialization
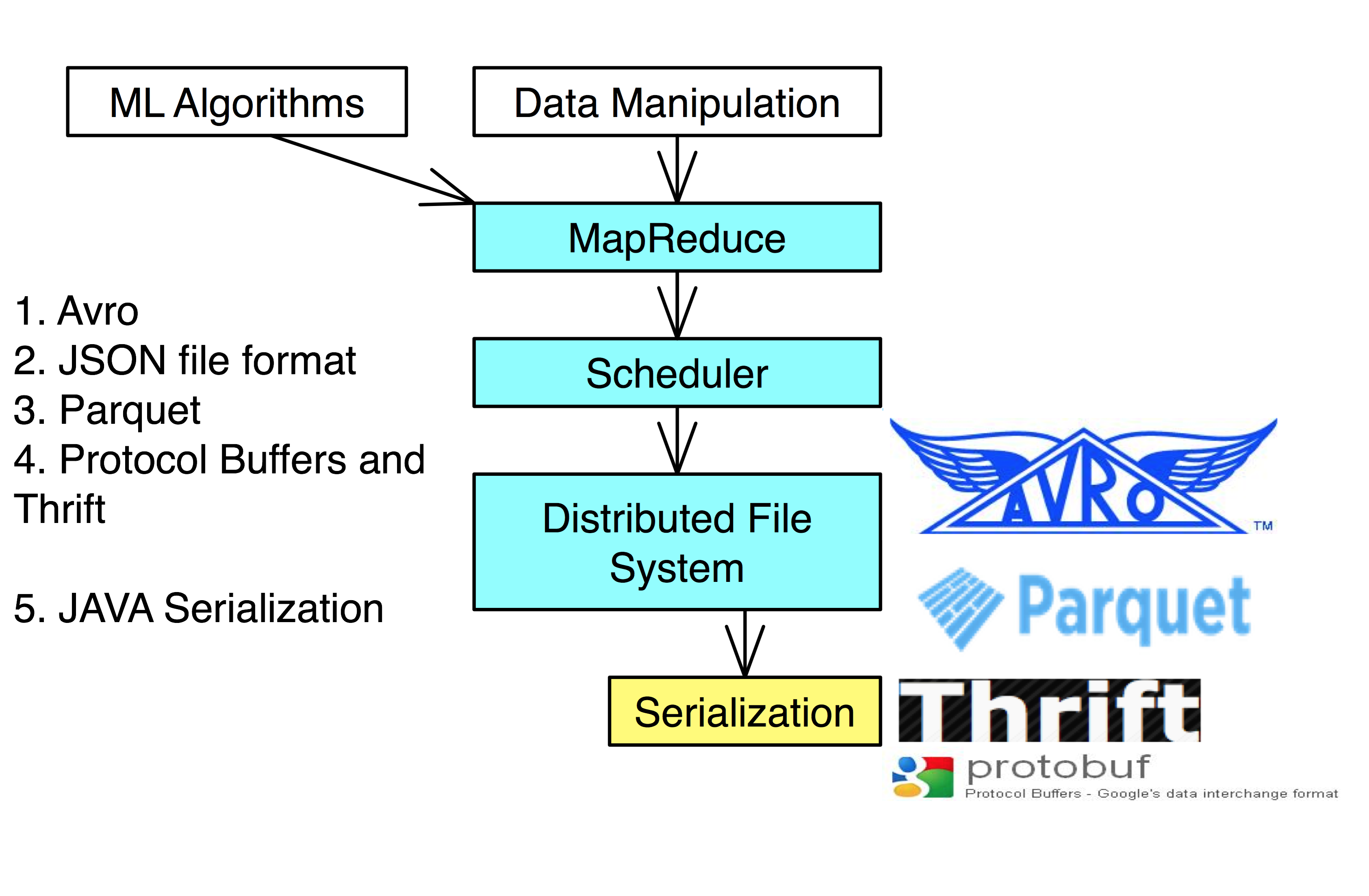
Parsing, transforming and combining the data into a useable dataset can be time consuming. Thus, once a suitable amount of work is done to create a useable dataset it is best to save it for future work.
Serialization saves the state of the data, allowing it to be recreated at a later date.
- JAVA Serialization is the worst of the above and should only be used for legacy reasons
Avro: Serialization made for Hadoop.
JSON: Java Script Object Notation is a convenient way of describing, serializing, and transferring data.
Protocol Buffers: More optimal serialization that requires the precise structure of the data when job is being run. Has less support for programming languages.
Parquet: A columnar data storage format, allowing it perform well for structured data with a fair amount of repetition.
Data Transfer
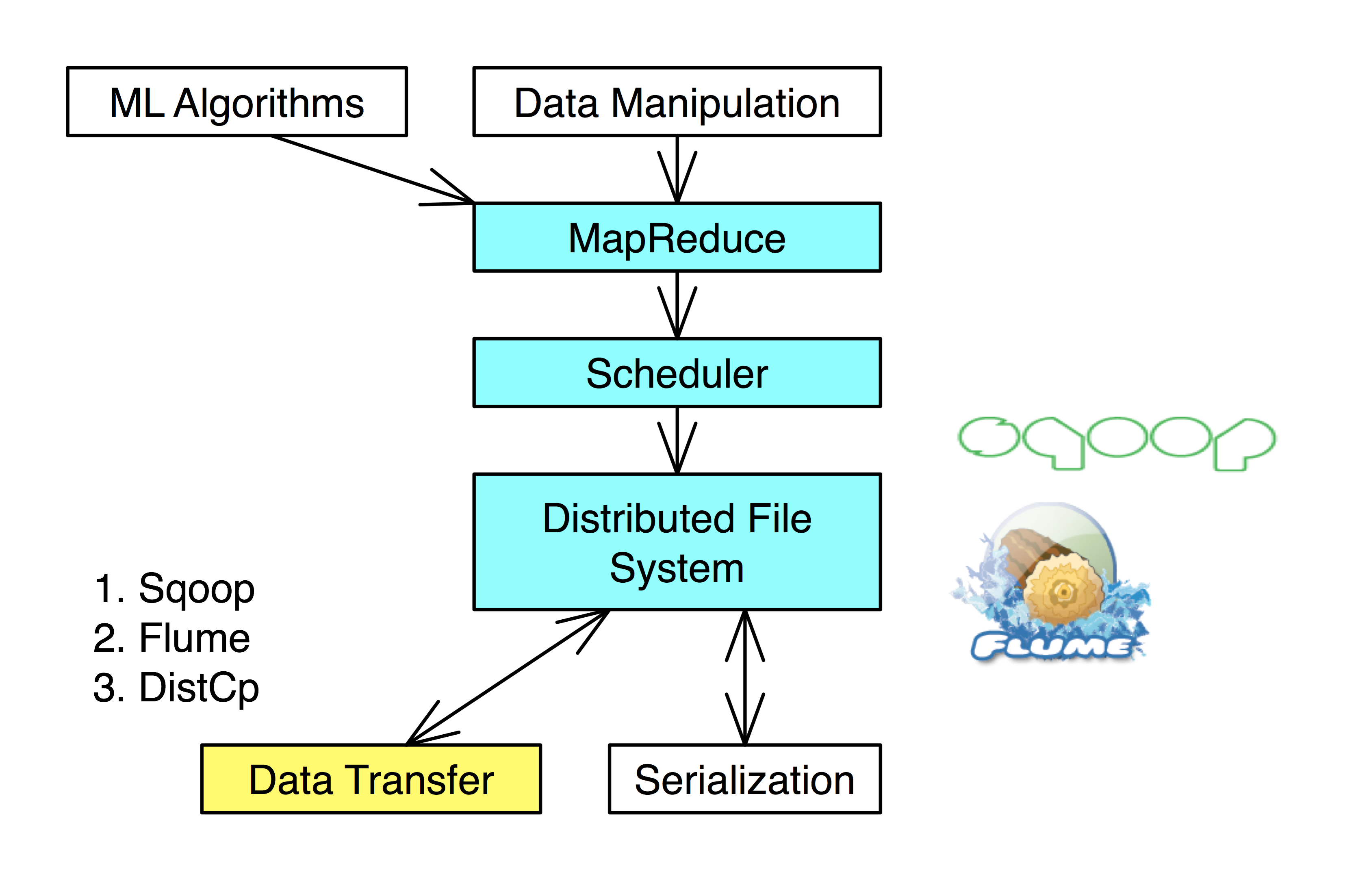
Data transfer of large amounts of data to and from dfs.
Flume, DistCp: Move files and flat text into Hadoop.
Sqoop: Move data between Hadoop and SQL.
Streaming
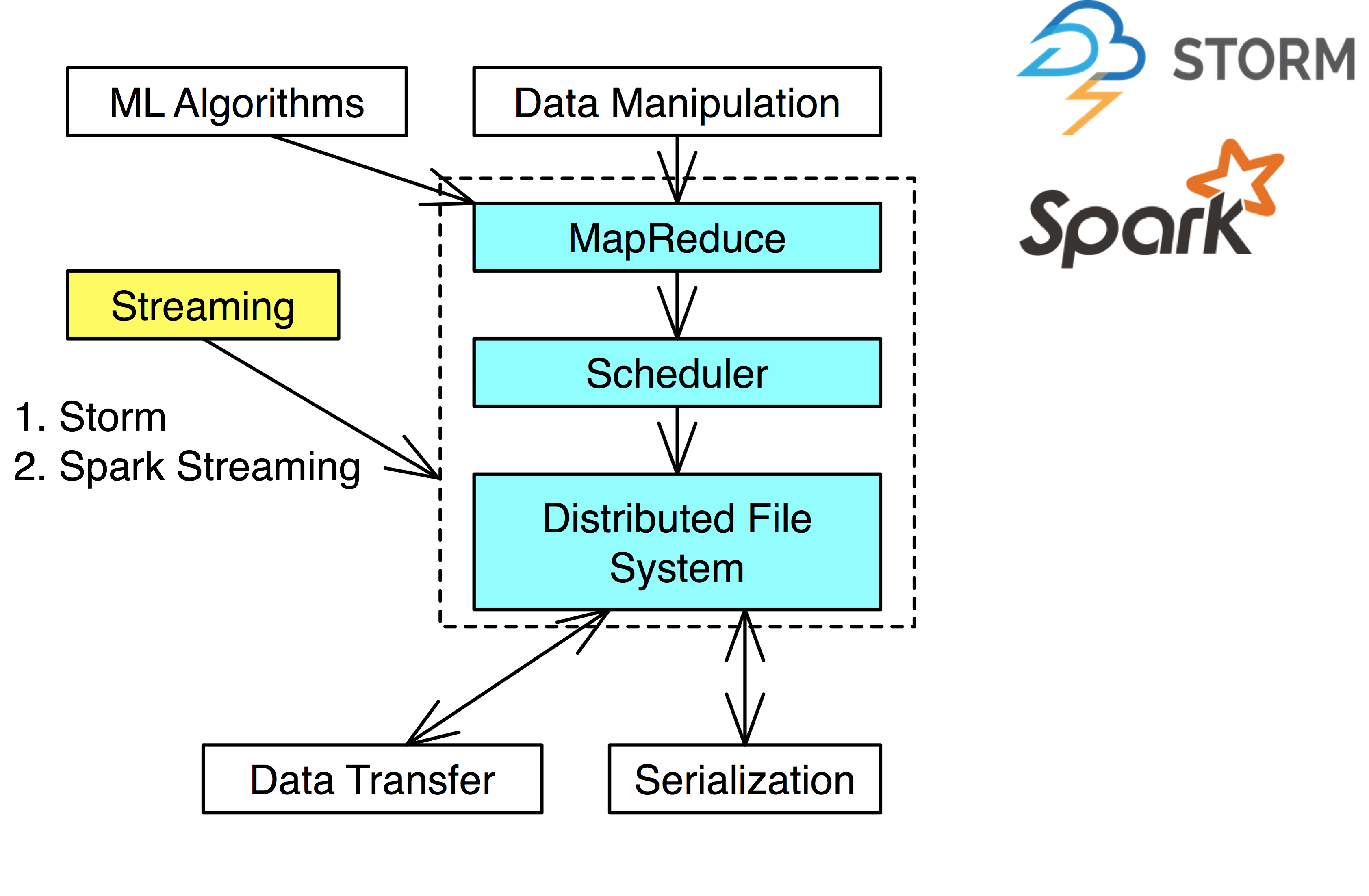
Streaming provides new calculations based on incoming data.
Example: Netflix ‘Trending Now’ feature. Possibly with personalized medicine to use medical devices to detect heart attacks before they happen.
Spark Streaming: Uses a micro-batch model that checks updates every 0.5-10 seconds and updates it’s model.
Storm: Uses either streaming or micro-batch updates to update model.
Management and Monitoring
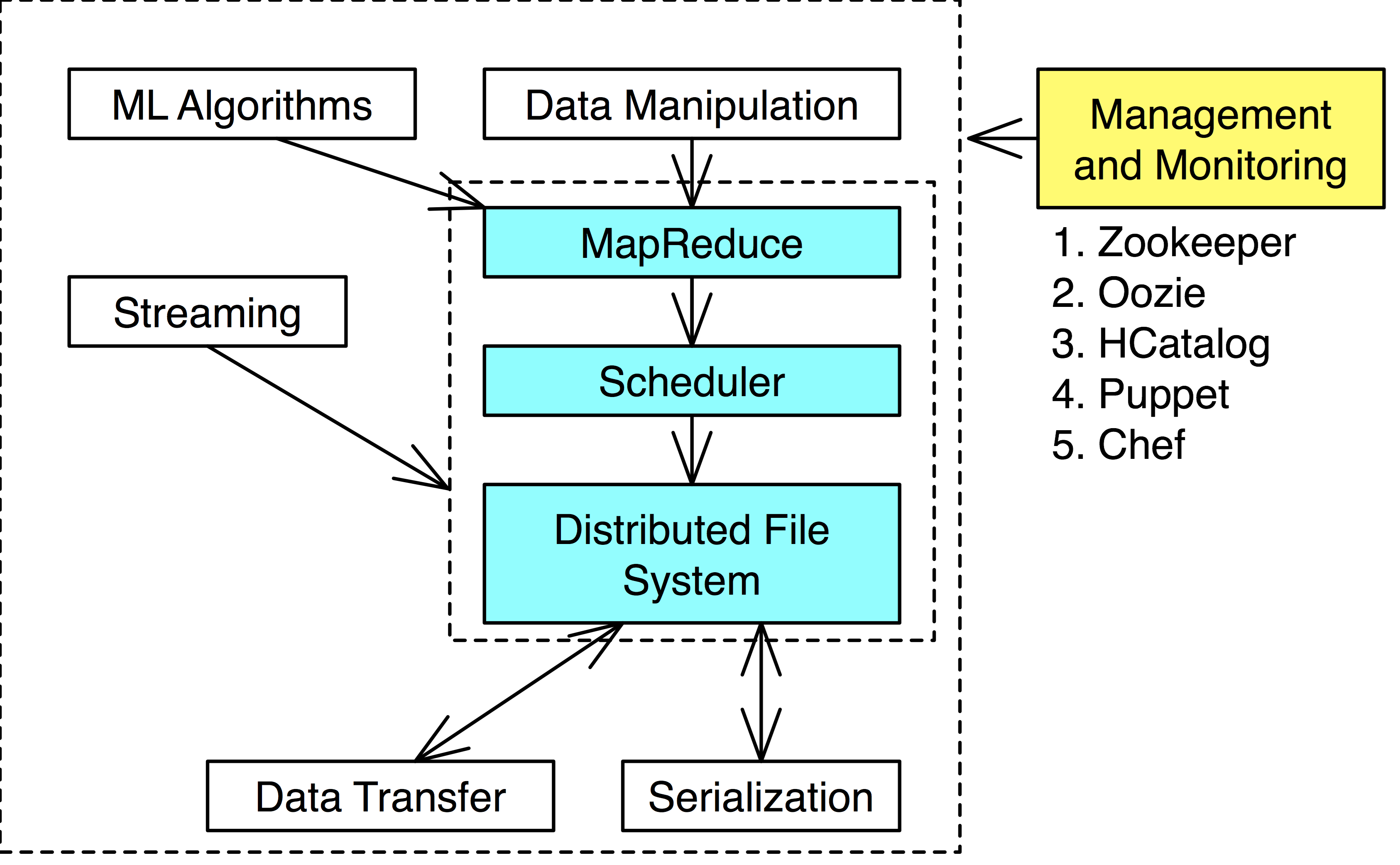
Node configuration management: Puppet, Chef. Change operating system parameters and install software.
Resource Tracking: Monitor the performance of many tools.
Coordination: Helps synchronize many tools in a single application: Zookeeper.
Ambari: Tool to help install, starting, stopping, and reconfiguring Hadoop cluster.
HCatalog: Central catalog of file formats and locations of data. Data looks like a table-like to user.
Nagios: Alert failures and problems through a graphical interface and alert administration though email of problems.
Puppet, Chef: Manager for configuration of a large number of machines.
Zookeeper: Helps coordination of tools.
Oozie: Workflow scheduler to start, stop, suspend and restart jobs, controlling the workflow so that no task is performed before it is ready.
Ganglia: Visualize how systems are being used and keeping track of general health of cluster.
Security, Access Control, and Auditing
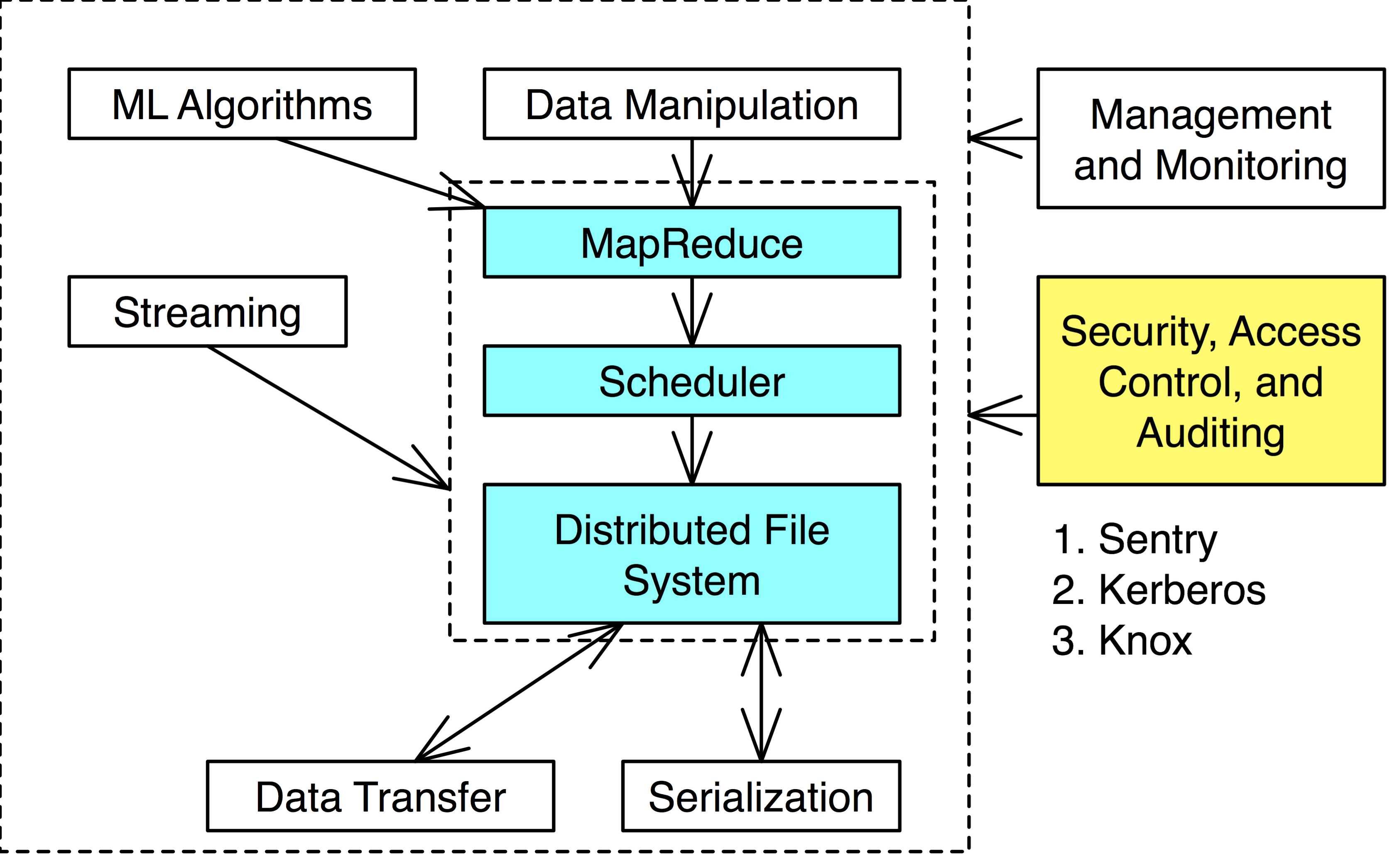
Hadoop in itself doesn’t provide much security. As Hadoop increased in popularity, so has security projects.
Kerberos, Sentry, Knox are such projects.
Cloud Computing and Virtualization
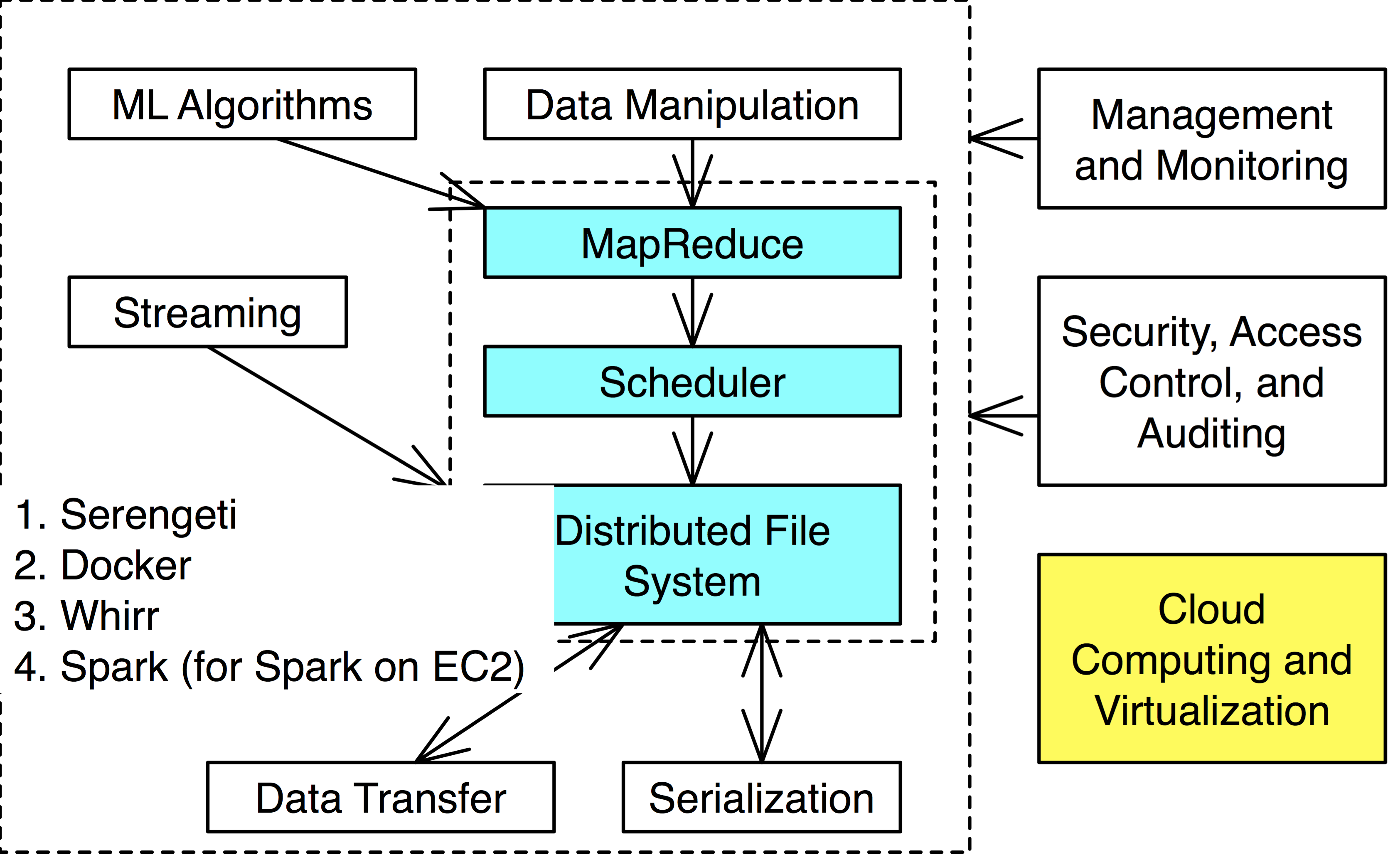
Sometimes you only need intermediate use of a cluster and creating/maintaining one of your own is prohibitively expensive.
Cloud computing and virtualization tools provide easy construction of Hadoop environments with relative ease on cloud computering environments like AWS.
Distribution Platforms
Distribution platforms help (for a cost) easy installation and software maintaince of a Hadoop cluster.
- Tool versions are checked for compatability, usually meaning that they are not the newest versions
Some of these are: Cloudera, MapR, and Hortonworks.
Next Steps: Data Science Framework
Now that you have been introduced to the tools, start on the next module and learn the data science framework.