List of notes
-
Hands on SQL introduction/ tutorial
Orginally created by Darrell Aucoin in conjuection with the Stats Club, find the original here.
Installation of SQLite Browser
Windows
Download and install the file below
Mac
Download and install the package below
Ubuntu and Linux Mint
In terminal execute the following command
sudo apt-get install sqlitebrowserGet the material
- Go to https://github.com/NormallySane/IntroSQL
- Download zip
file
- Unzip downloaded file in your preferred directory
Using SQLite Browser
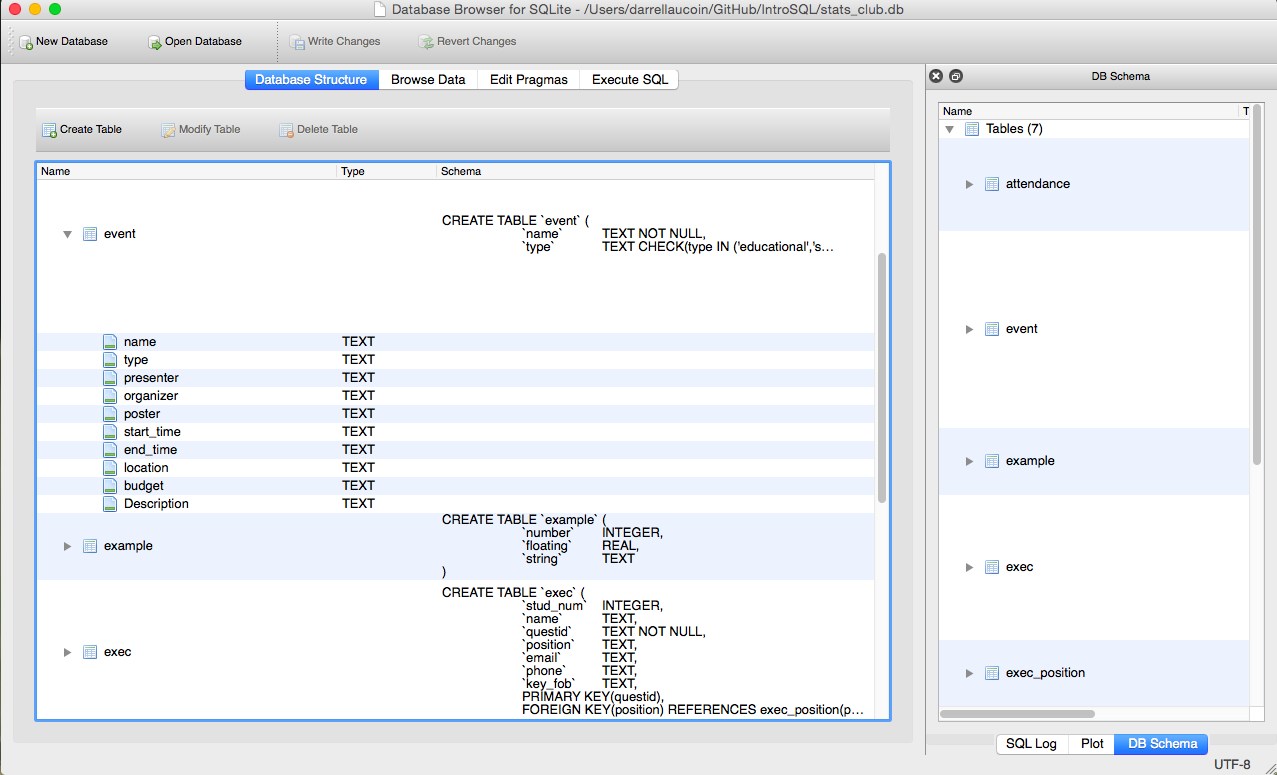
- Open SQLite browser
- Open
stats_club.dbdatabase file in the downloaded directory - Click on ‘Execute SQL’ tab
- Open SQL file
IntroSQL_Presentation1.sqlfile in the downloaded directory,IntroSQL_Presentation2.sqlfor second presentation. - Follow along with file, executing statement as topics dictate
- Open SQL file
- Content of the talk is on https://github.com/NormallySane/IntroSQL/wiki (open in your favorite browser)
- SQLite browser is a great tool for learning SQLite and SQL in general
Features of SQLite Browser
- Lets you see the data structure of tables in the database
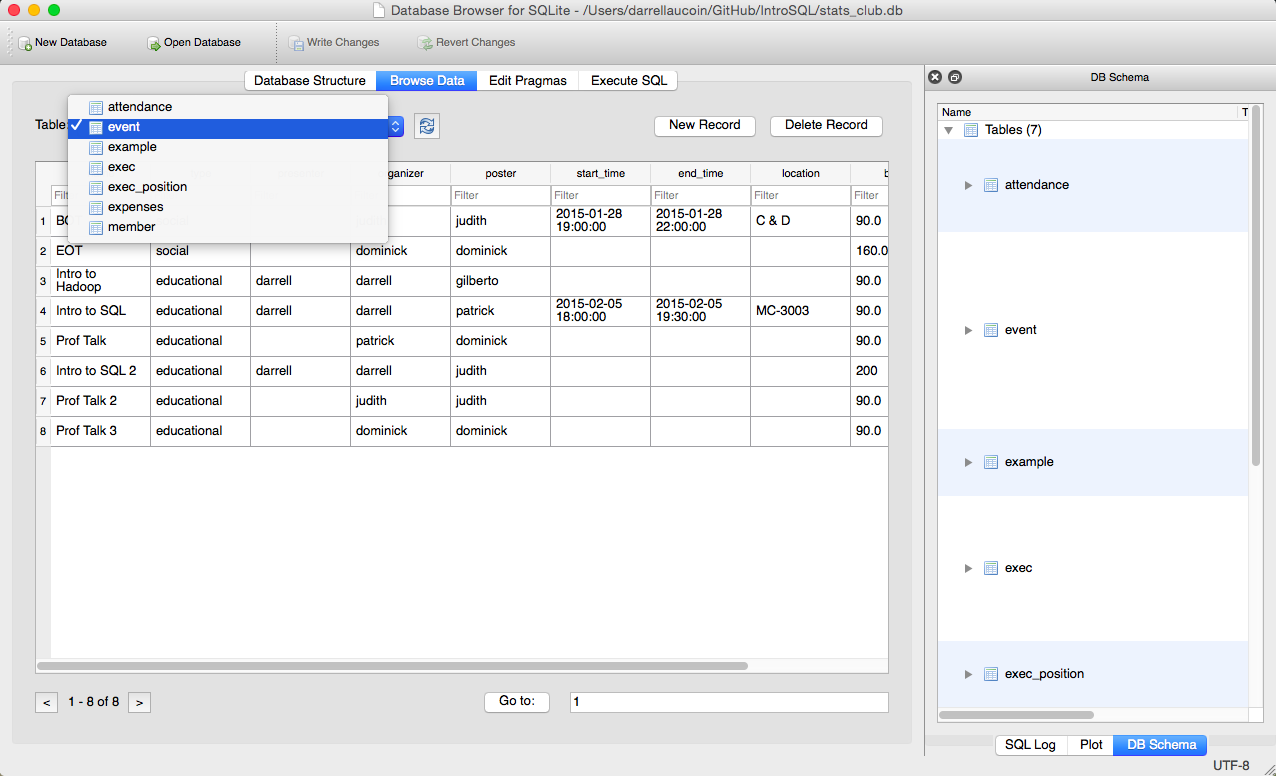
- Explore the data entered in tables
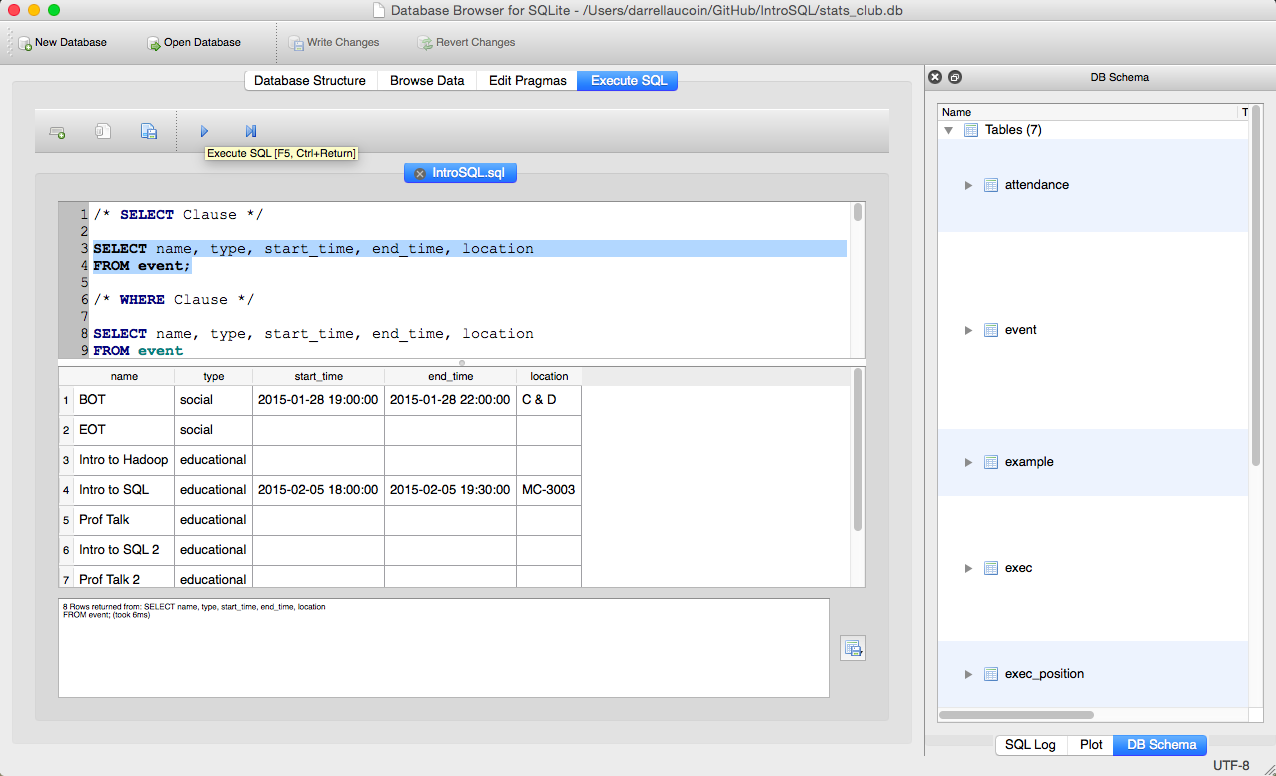
- Execute SQL statements and see results
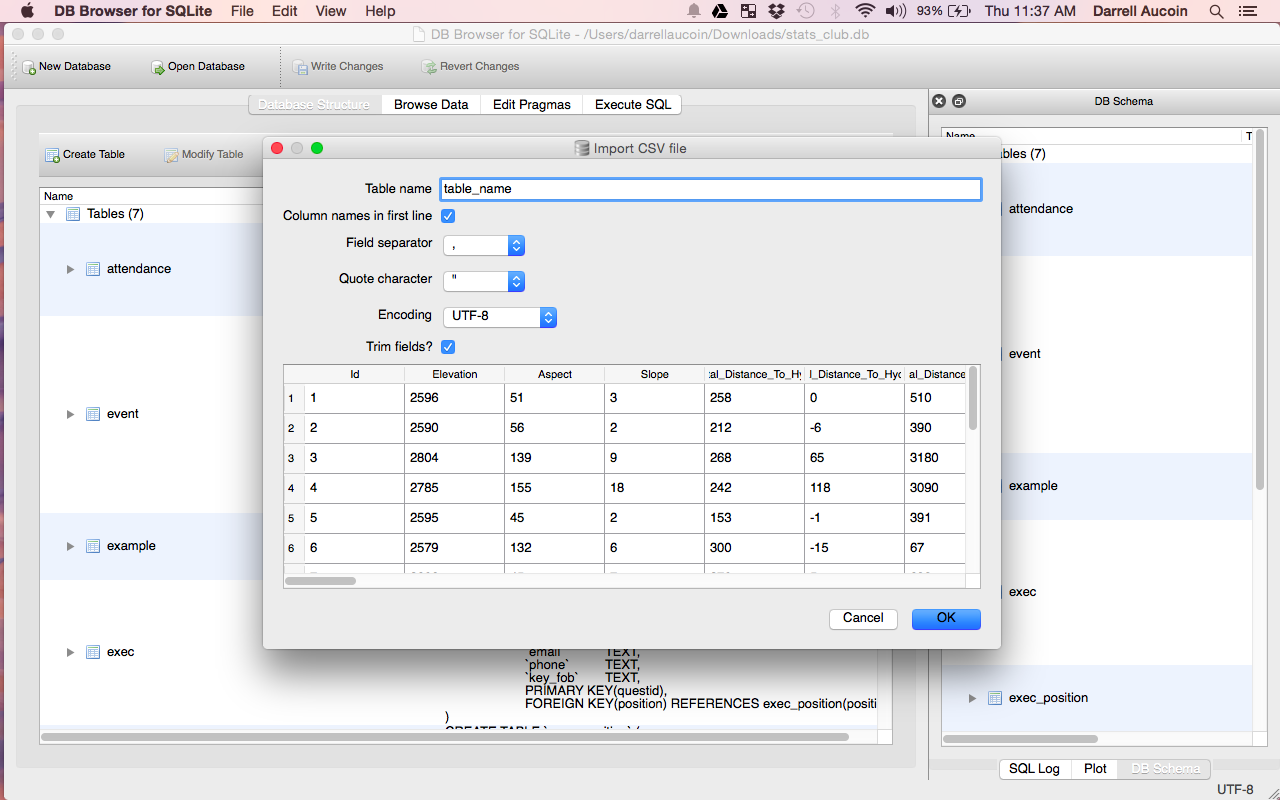
- Easily construction tables from files
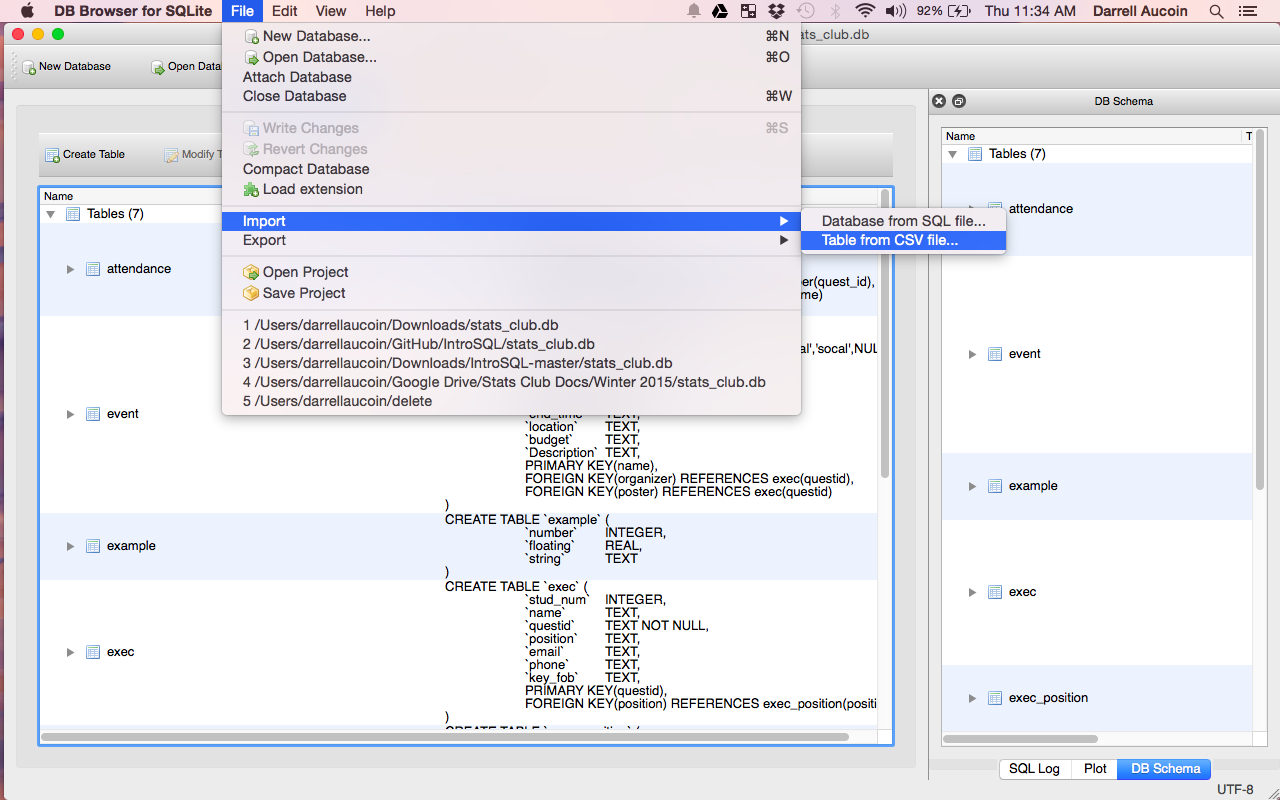
- If the table is already created it will just import the data into the table, otherwise it will create a new table
- SQLite functionality can also be extended by various user created extensions
Motivation
Q: Why learn a database lanugage?
- Data is rarely tidy as they are in many stats courses
- Most of the time the data we want (outside of assignments) is in a database
Q: Why learn SQL?
- One of the most popular data analysis tools (O’Reilly Data Scientist Survey for 2014)
- One of the most in-demand skills for 2014 (Workopolis)
- SQL not only can retrieve data, but can slice, dice and transform the data as needed
Q: What is SQL?
- A programming language allowing multiple concurrent users storing, manipulating, and querying data stored in a relational database.
- Data does not necessary have to fit into memory.
Q: Why use SQLite?
- Very easy to install
- Easy to share (database is a single file)
- Good SQL language to practice with (can easily use it to preprocess data for kaggle competitions)
Different Implementations of SQL
MySQL: Highly popular open source SQL implementation.
PostgreSQL: Open source SQL designed around letting users create User Defined Functions (UDF).
SQLite: Open sources light weight SQL usually used as an embedded database for applications (web browsers, mobile applications, etc.), or light to medium traffic websites. Database is saved as a single file and only allows one writer at a time. Various OS’s have SQLite preinstalled (type
sqlite3in terminal for mac)Oracle: SQL implementation produced and marketed by Oracle Corporation.
Microsoft SQL Server: SQL implementation developed by Microsoft.
DB2: SQL developed by IBM. The database used by University of Waterloo.
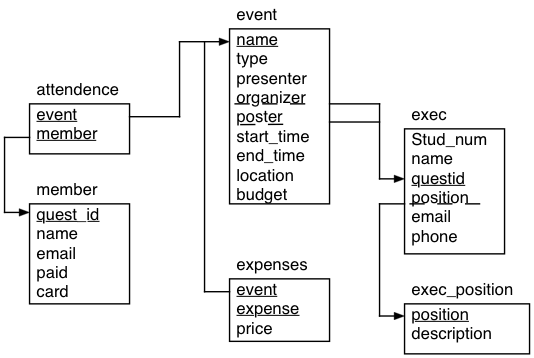
Relational Databases
Relational Database: A relational database is a system organized in tables containing records (rows) related to other records in other tables. Each entity having attributes (columns also called fields) which give additional information on an entity.
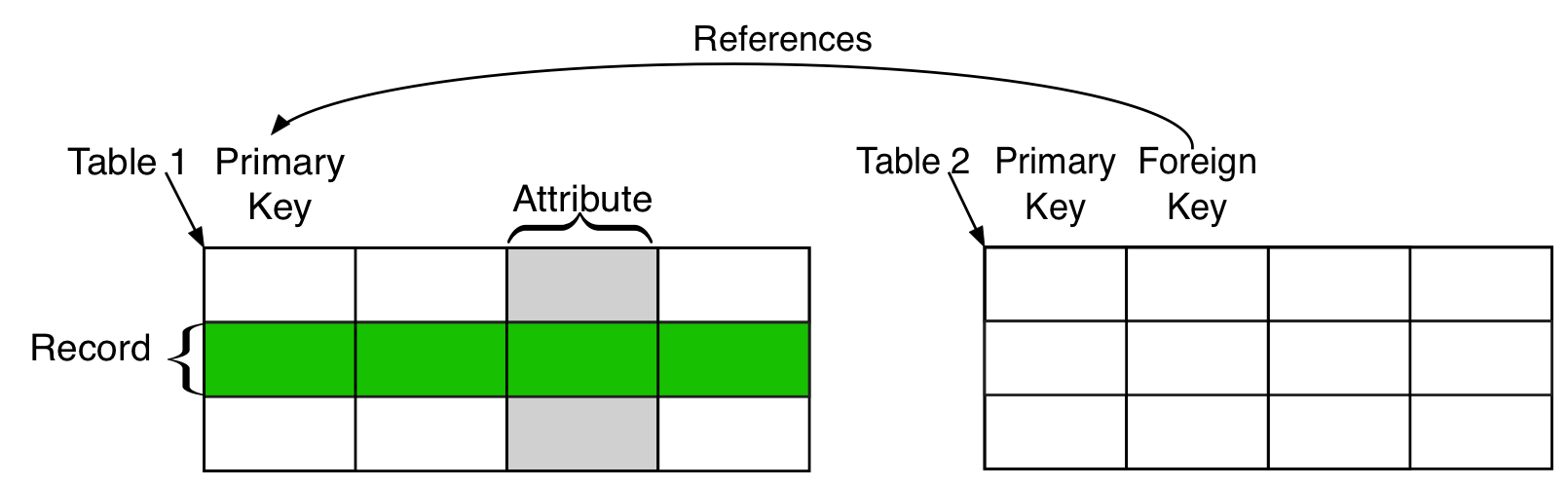 Field, Attribute (Column): An individual piece of data stored in a table.
Record (Row): A tuple of columns describing an entity or action of an entity.
Table: A collection of rows. Usually in reference a persistent table saved permanently to memory
Result set: A non-persistent table, usually the result of a query.
(Virtual) View: A named query saved into memory and performed whenever it is named. Some SQL servers have materialized views that permanently save the data for faster access.
Subquery: A query that returns a table to another query.
Primary key: A tuple of columns that uniquely define each row in a table.
Foreign key: A tuple of columns identifying a relationship to another table.
The E-R Model
The E-R (entity-relationship) Model is an analysis tool for relational databases. E refers to entity: An object R refers to relationship: As in how objects relate to each other.
Each entity has properties associated with every instance of an object.
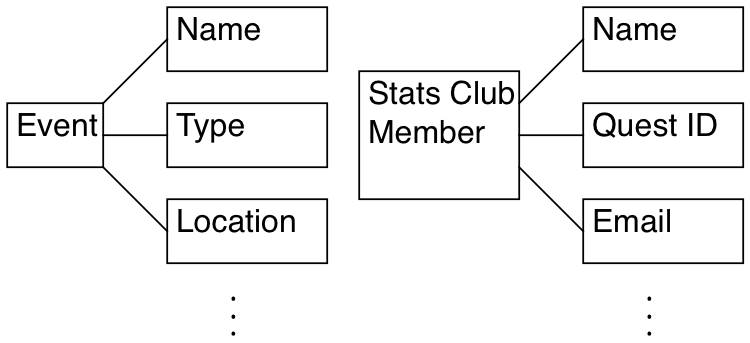 Objects are related to each other through relationships:
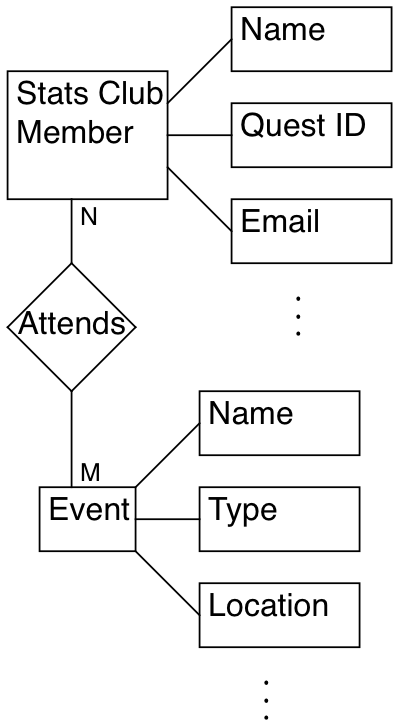 E-R Relationships
- One to one relationships: For every instance of object A, there are
exactly one instance of object B.
- Every student has exactly one quest account
- One to many relationships: For every instance of object A, there are an
indeterminate number of instances of object B.
- A single course section has many students
- Many to one relationships: For many instances of object A, there are a
single instance of object B.
- Many students are enrolled in a course section
- Many to many relationships: For many instances of object A, there are a
many possible instances of object B.
- Many students take many courses
Normalization
Database Normalization is a process in relational databases to minimize redundacy. Data can be constructed so that additions, deletions, and modifications can be made in just one table.
Data goes through three forms until it is fully utilizied by a relational database:
- First Normalized Form: Each attribute contains only atomic values and only a single value from that domain. i.e. The data is in the form of a table with no merged columns or rows.
- Second Normalized Form: Each attribute in the table is dependent on the entity it is describing (dependent on the primary key).
- Third Normalized Form: All non-primary key attributes are not determined by any other non-primary key attributes.
Example: For each event for Stats Club we have: 1. a list of attendies along with some basic information (email, ect.), 2. the event’s name, type (social or education), the roles for Stats Club execs for the event, time and location of the event, and a budget, 3. as well as a list of expenses for the event
A report of the event would look something like:
 We first need to tabulate the data:
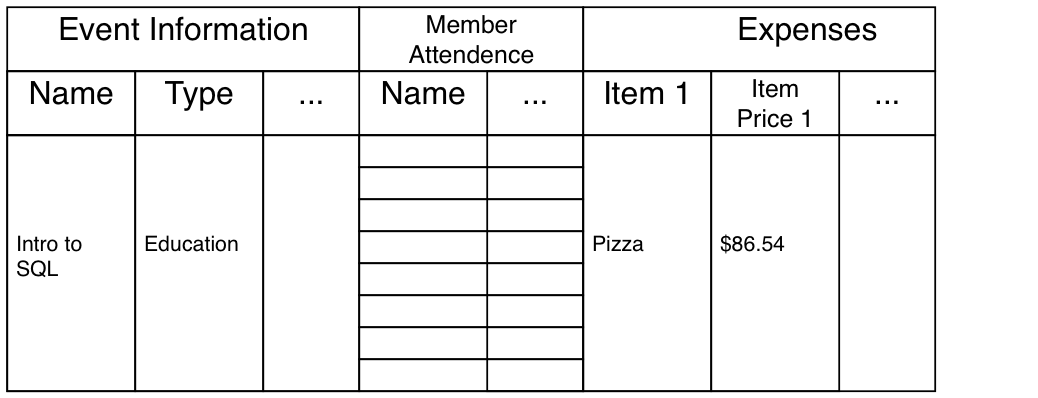 However this is not enough, the data is not in a form that can be easily recognized by computers. - How do you add new events? - What about members that attend multiple events? - that attend no events?
1st Normalization
First Normalized Form: Each attribute contains only atomic values and only a single value from that domain
Example: To bring the data into 1st normalized form we need to break the table into two tables: Event, and Expenses:
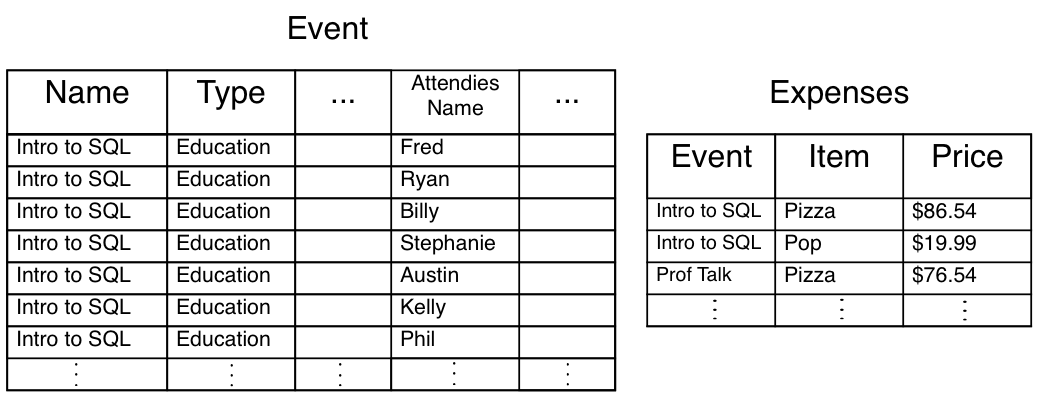  - This contains all of the information before but is more organized for the computers to deal with
- Still not enough, a mispelling of an event or type could make the database think there is a new event
2nd Normalization
Second Normalized Form: Each attribute in the table is dependent on the entity it is describing (dependent on the primary key).
Example: To bring the data into 2nd normalized form, we need to break the Event table again. Let’s break the table so we get important description of the events (name, type, presenter, organizer, etc.) and a list of members that attended each event.
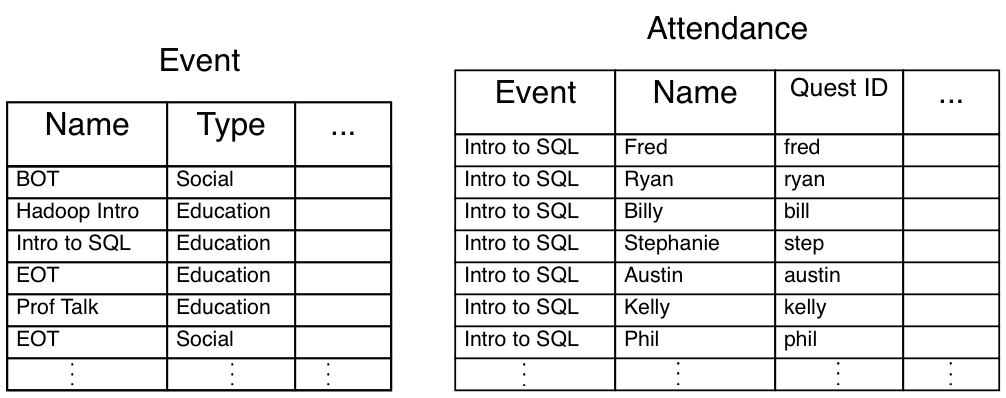  - Attendance is 2nd normalized form if we consider the primary key as the tuple of event and quest ID.
- Attendance still has redundant information, several members can attend multiple events or none at all
3rd Normalization
Third Normalized Form: All non-primary key attributes are not determined by any other non-primary key attributes.
Example: The information on each member (name, email, etc.) is not determined by the event. We need to break the attendance table to bring into 3rd normalized form: attendance and members.
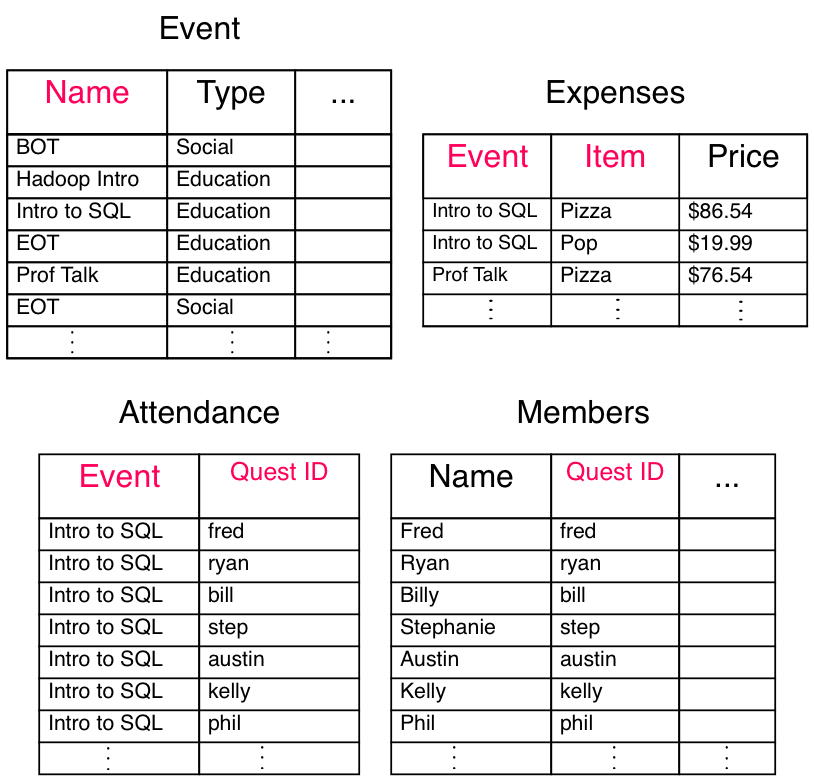 Primary Keys and Foriegn Keys
We can reconstruct the orignal table by joining tables, foreign keys with what they reference (primary keys). - We can only construct an instance of a foreign keys if their is already an instance of their reference - i.e. the set of foreign keys for one table is a subset of the primary keys they reference
Primary key: A tuple of columns that uniquely define each row in a table. (Red items below) Foreign key: A tuple of columns identifying a relationship to another table. (Blue items below)
 Quiz: Normalization
Normalize the following table:
Student Name Quest ID Course Description Section Solutions are here
Relational Algebra Operations
Projection: Returns a subset of columns.
Selection: Returns only entities where some condition is true.
Rename: Rename an attribute.
Natural Join: Tuples from one table is joined to tuples from another table based on common attributes (at least one column with the same name and possible values is common between them)
Θ__-Join and Equijoin:__ Join tuples from two different tables where some binary condition (Θ = {≥, ≤, >, <, =}) between two tables attributes is true. When Θ is =, the join is called an equijoin.
Set Operations: Set theory’s unions, set difference, and cartesian product of tuples performed on tuples of different tables.
Quiz: Relational Algebra
Q1: What kind of operation is performed on the following tables?
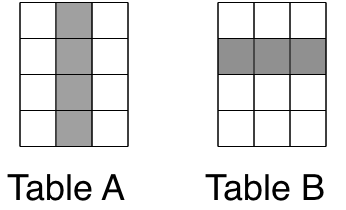 Q2: What kinds of joins can peform on tables?
Solutions are here
Constraints
Constraints limit what can be entered into fields in a table and help ensure encapsulation:
PRIMARY KEY constraints Uniquely identifies each record in a table (quickly referencing it)
FOREIGN KEY constraints Points to a PRIMARY KEY of another table, enabling them to easily join them
CHECK constraints Limits the range of values that a field can take.
UNIQUE constraints Enforces uniqueness on an field (column).
NOT NULL constraints Enforces a field to always contain a value.
- We can also create indexes for fields making them easily searchable
SQL Language
- Case does not matter, for presentation purposes UPPER CASE is used for SQL key words
-
SQL statements are processed as a whole (ignoring white space and new lines) and ends with a ‘;’
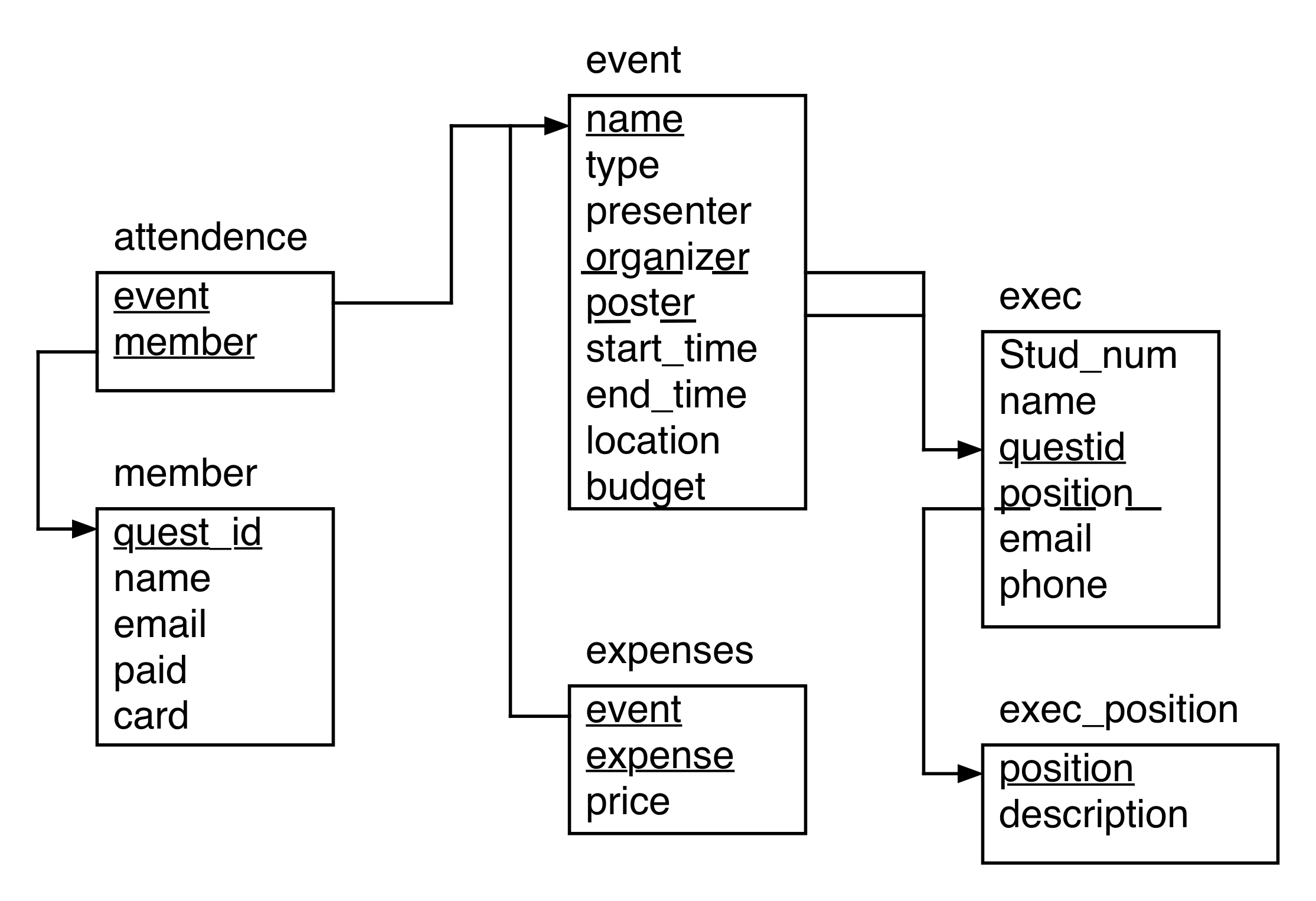
- We will be used a database based on Stats Club, supplied with fake data:
 Data Types
In SQLite3, there are 5 basic data types:
-
INTEGER The value is a signed integer.
-
REAL The value is a floating point value, stored as an 8-byte IEEE floating point number.
-
TEXT The value is a text string.
-
BLOB The value is a blob of data, stored exactly as it was input.
-
NUMERIC May contain integer or real values. The data is stored as text but converted as necessary.
SQL General Data Types
- Different implementations of SQL uses different datatypes but there are some general commonalities:
Data type Description CHAR(n) Character string. Fixed length n VARCHAR(n) Character string. Variable length <= n BINARY(n) Binary string. Fixed length n BOOLEAN TRUE or FALSE values VARBINARY(n) Binary string. Variable length <= n INTEGER(p) Integer numerical (no decimal). Precision p SMALLINT Integer numerical (no decimal). Precision 5 INTEGER Integer numerical (no decimal). Precision 10 BIGINT Integer numerical (no decimal). Precision 19 DECIMAL(p,s) Exact numerical. precision p, scale s NUMERIC(p,s) Exact numerical. precision p, scale s FLOAT(p) Floating point number. mantissa precision p REAL Approximate numerical. Mantissa percision 7 FLOAT Approximate numerical. Mantissa percision 16 DATE Stores year, month, and day values TIME Stores hour, minute, and second values TIMESTAMP Stores year, month, day, hour, minute, and second values NULL Values
NULL A NULL can be thought of as an unknown value. - Any datatype can have NULL values - if either x or y is NULL:
x+y => NULL x>y => NULL SQL uses a three-value logic system: TRUE, FALSE, NULL:
AND TRUE FALSE NULL TRUE T F NULL FALSE F F F NULL NULL F NULL OR TRUE FALSE NULL TRUE T T T FALSE T F NULL NULL T NULL NULL NOT TRUE FALSE NULL F T NULL Projection (SELECT Clause)
SELECT Statement: The SELECT statement returns a table of values (sometimes empty) as specified in the statement.
SELECT Clause: The SELECT clause of a SELECT statement specifies the columns for the result set.
SELECT col1, col2, ... FROM table_name;- We can also specify all columns from a table
SELECT * FROM table_name;- If we leave out ‘
FROM table’ we are effectively taking from an empty table
In SELECT clauses, we can specify more than just columns from a table: Literials: Strings, numbers that are repeated for every row Expressions: Expressions of columns/literals Functions: Built in functions in SQL (ROUND(), etc.) User Defined Functions: Functions that a user can create within SQL to run
Example: Let’s try something simple: some literials and a calculation of
1 / 2SELECT 1, 2, 'this is a string', 1/2;1 2 'this is a string' 1/2 0 1 2 this is a string 0 Q: What happened here?
A: Since 1 and 2 are both integers, the expression 1/2 returns an integer. To get 0.5, we need to use a real number (a FLOAT).
SELECT 1, 2, 'this is a string', 1/2, 4/2, 5/2, 1/2., 1./2, 1/CAST(2 AS FLOAT);1 2 'this is a string' 1/2 4/2 5/2 1/2. 1./2 1/CAST(2 AS FLOAT) 0 1 2 this is a string 0 2 2 0.5 0.5 0.5 SQL statements ignore white spaces and new lines, the statement is only processed when after it sees ‘;’
Example: The following two statements produce the same table.
SELECT 1, 2, 'this is a string', 1/2;1 2 'this is a string' 1/2 0 1 2 this is a string 0 SELECT 1, 2, 'this is a string', 1/2;1 2 'this is a string' 1/2 0 1 2 this is a string 0 SQL Functions
There are many functions in SQLite and each implementation of SQL have different functions. Here are some random functions in SQLite:
Function Description ABS(col) Absolute value of numeric column LENGTH(col) Return length of string column LOWER(col) Return the string column in lower case UPPER(col) Return the string column in upper case RANDOM() A pseudo-random integer between -9223372036854775808 and +9223372036854775807 SELECT ABS(-8), LENGTH('This is a String'), LOWER('ThIS Is A StRiNg'), RANDOM();ABS(-8) LENGTH('This is a String') LOWER('ThIS Is A StRiNg') RANDOM() 0 8 16 this is a string 1085249690759383083 There are many more core functions within SQLite.
Quiz: SELECT Clause
Calculate the average of 2 random numbers.
Q: What is the upper and lower case for the string ‘UPPER or lower’?
Solutions are here
FROM Clause
FROM Clause: Specifies the table: either a persistant table, or a result set: a join of two or more tables or a subquery or some combination of the two.
SELECT col1, col2, ... FROM table_name;Example: What are the names, type, times and locations for Stats Club?
SELECT name, type, start_time, end_time, location FROM event;name type start_time end_time location 0 BOT social 2015-01-28 19:00:00 2015-01-28 22:00:00 C & D 1 EOT social None None None 2 Intro to Hadoop educational None None None 3 Intro to SQL educational 2015-02-05 18:00:00 2015-02-05 19:30:00 MC-3003 4 Prof Talk educational None None None 5 Intro to SQL 2 educational None None None 6 Prof Talk 2 educational None None None 7 Prof Talk 3 educational None None None Quiz: FROM Clause
Q: Who are the execs for Stats Club, and what are their positions, and emails? - Projection of name, position, and email from the table exec
Solutions are here
Aggregate Functions
Aggregate Functions: Takes in the columns of a table and aggregates over the entries.
Function Return value AVG(column) Average of non-null values COUNT(column) Count of non-null values MAX(column) Maximum of values MIN(column) Minimum of values SUM(column) Sum of values GROUP_CONCAT(column) Concatenation of column strings - There are more aggregate functions for other implementations of SQL
More detailed descriptions of the aggregate functions within SQLite can be found here.
SELECT COUNT( 12 ), COUNT('ssdf'), COUNT(NULL), SUM(23), SUM(0), SUM(NULL), AVG(0), AVG(NULL);COUNT( 12 ) COUNT('ssdf') COUNT(NULL) SUM(23) SUM(0) SUM(NULL) AVG(0) AVG(NULL) 0 1 1 0 23 0 None 0 None Lets work with some aggregate functions with the table
examplebelow:number floating string 0 1 23.23 this 1 3232 -21.23 is 2 11 -2.00 a 3 -23 54.00 string 4 2 NaN concatenated SELECT COUNT(*), COUNT(string), COUNT(floating), AVG(number), SUM(number), GROUP_CONCAT(string, ' ') FROM example;COUNT(*) COUNT(string) COUNT(floating) AVG(number) SUM(number) GROUP_CONCAT(string, ' ') 0 5 5 4 644.6 3223 this is a string concatenated DISTINCT Prefix
In the SELECT clause we can specify to return only distinct tuples of columns
SELECT DISTINCT col1, col2, ... FROM table_name;- We can also use DISTINCT within aggregate functions making them only aggregate over distinct entries
SELECT aggregate_function(DISTINCT column_name) FROM table_name;Example: What events have members attended? - What are the distinct events where at least one member attended?
SELECT DISTINCT event FROM attendance;event 0 Intro to SQL 1 BOT 2 EOT 3 Intro to Hadoop 4 Intro to SQL 2 5 Prof Talk 6 Prof Talk 2 Quiz: DISTINCT
Q: What are the distinct majors of Stats Club members?
Q: How many distinct majors of Stats Club members are there?
- DISTINCT can be within aggregate functions
Solutions are here
Alias
Column Alias
To increase the readability of SQL as well as the result set, we can give columns new names:
SELECT col AS new_name FROM table_name;- Column aliases make the final table more readiable and workiable for subqueries
Table Alias
We can also give tables new names as well:
SELECT table_alias_1.col_name, table_alias_2.col_name, ... FROM table_1 AS table_alias_1, table_2 AS table_alias_2;- Very useful when tables have common column names
Note: We can reference what table a column is coming from by a ‘.’
table_name.column_nameExample: If we give column aliases for the previous table, we make the result more interpretiable:
SELECT COUNT(*) AS num_rows, COUNT(string) AS num_strings, COUNT(floating) AS num_float, AVG(number) AS avg_integer, SUM(number) AS sum_int, GROUP_CONCAT(string, ' ') AS cat_string FROM example;num_rows num_strings num_float avg_integer sum_int cat_string 0 5 5 4 644.6 3223 this is a string concatenated Quiz: Aliases
Perform a query using a table alias, and use this table alias when referencing the column i.e.
table_alias.column_name- This will be really important for bigger, more complicated queriesSolutions are here
Selection (WHERE Clause)
WHERE clauses filters the result set, removing rows where the condition returns either FALSE or NULL.
SELECT col1, col2, ... FROM table_name WHERE condition;Example: What Stats Club events are social?
SELECT name, type, start_time, end_time, location FROM event WHERE type = 'social';name type start_time end_time location 0 BOT social 2015-01-28 19:00:00 2015-01-28 22:00:00 C & D 1 EOT social None None None Prediate Operators
Operator Description Example = Equal to WHERE gender = ‘M’ <>, != Not equal to WHERE gender <> ‘M’ > Greater than WHERE num > 5 < Less than WHERE num < 5 >= Greater than or equal to WHERE num >= 5 <= Less than or equal to WHERE num <= 5 IS NULL Value is NULL WHERE num IS NULL IS NOT NULL Value is not NULL WHERE num IS NOT NULL BETWEEN Between a range WHERE num BETWEEN 3 AND 5 IN In a list of values WHERE num IN (3, 5, 8) LIKE Pattern Search WHERE str LIKE ‘F%’ EXISTS Subquery have any rows? WHERE EXISTS (subquery) LIKE Predicate
LIKE predicates
‘_’ means a character of any type ‘%’ means between 0 or more characters of any type
Example: What Stats Club members has a name begining with F?
SELECT * FROM member WHERE name LIKE 'F%';quest_id name email faculty major paid card 0 fred Fred E. Finch fred@uwaterloo.ca Math Pure Math Y Y 1 frances Frances A. Miller frances@uwaterloo.ca Math Stats Y Y Operator Modifiers
ALL, ANY or SOME Operator Modifiers
The operators =, <>, !=, >, <, >=, <= can be used with a list of values and the operators
ALLorANY / SOME.- SQLite does NOT have
ALLorANY / SOMEimplemented
ANY, SOME Operator returns true, if operator is true for any value in the set.
ALL Operator returns true, if operator is true for all values in the set.
SELECT * FROM table_name WHERE column_name < ALL (subquery_returning_one_column);Example: What are the expenses for non-social events? (
ALL,ANY, andSOMEare not implmented in SQLite)SELECT * FROM expenses WHERE event != ALL (SELECT name FROM event WHERE type = 'social');event expense price 0 Intro to SQL pizza 87.43 1 Intro to SQL pop 15.34 2 Intro to Hadoop coffee 23.12 3 Intro to Hadoop water 10.23 4 Intro to Hadoop donuts 53.23 5 Intro to Hadoop cookies 10.23 6 Intro to SQL: Basic Queries cookies 10.23 7 Intro to SQL: Basic Queries donuts 20.34 8 Intro to SQL: Basic Queries pop 21.54 9 Intro to SQL: Basic Queries water 10.52 10 Prof Talk pop 20.31 11 Prof Talk pizza 62.56 12 Prof Talk 2 pizza 61.56 13 Prof Talk 2 pop 15.65 14 Prof Talk 3 pizza 62.45 15 Prof Talk 3 pop 13.23 16 Intro to SQL: Advanced Queries cookies 10.23 17 Intro to SQL: Advanced Queries donuts 20.34 18 Intro to SQL: Advanced Queries pop 21.54 19 Intro to SQL: Advanced Queries water 10.52 AND, OR Operators
A group of filter conditions can be linked together with AND or OR operators.
SELECT col1, col2, ... FROM table_name WHERE (condition1 AND condition2 ) OR condition3;Example: What Stats Club members has a name with it’s second letter as A or ends in B?
SELECT name FROM member WHERE name LIKE '_a%' OR name LIKE '%b';name 0 Darrell Aucoin 1 James M. Eddings 2 James A. Foxt 3 Daniel J. Moore 4 Nancy P. Jackson 5 Ralph L. Waldrop 6 Tameika M. McMaster 7 Janelle T. Smith 8 Ruben Lamb 9 Patrick Robertson Quiz: Filtering (WHERE Clause)
Q: What events for Stats Club are introductory talks? - Introductory talk names start with ‘Intro’
Q: What Stats Club members have their first name starting with a letter BETWEEN A and G?
Solutions are here
GROUP BY Clause
- GROUP BY clause groups the table by a column (or tuple of columns) and applies
a function to each group
- In the SELECT portion of the statement, you can only list the grouped column(s) and aggregate functions on them.
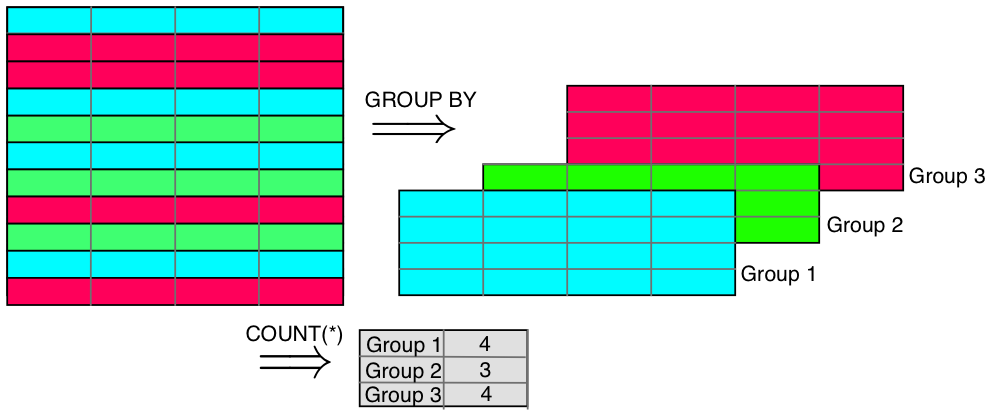 SELECT col1, col2, ..., aggregate_function FROM table_name GROUP BY col1, col2, ...;Aggregate Functions
Recall: Aggregate Functions: Takes in the columns of a table and aggregates over the entries. - If we use a GROUP BY clause, the aggregation will be over those groups
Function Return value AVG(column) Average of non-null values COUNT(column) Count of non-null values MAX(column) Maximum of values MIN(column) Minimum of values SUM(column) Sum of values GROUP_CONCAT(column) Concatenation of column strings - There are more aggregate functions for other implementations of SQL
Example: What are the number of each type of event for Stats Club?
SELECT type, COUNT(*) AS num_events FROM event GROUP BY type;type num_events 0 educational 6 1 social 2 HAVING Clause
HAVING clauses are very similar to WHERE clauses but can have aggregate function in their conditions.
You can have a WHERE and HAVING clause in the same statement.
Example: How many Stats Club members are in each major where the major has at least 2 members?
SELECT faculty, major, COUNT(*) FROM member GROUP BY faculty, major HAVING COUNT(*) >= 2;faculty major COUNT(*) 0 Math Act Sci 10 1 Math Applied Math 2 2 Math C & O 2 3 Math CS 3 4 Math Pure Math 2 5 Math Stats 14 GROUP BY with ROLLUP / CUBE
The ROLLUP operator produces a result set where the aggregate function is applied to each level of the GROUP BY hierachy. - The ROLLUP operator is NOT implemented in SQLite - Useful for making reports with totals and subtotals
SELECT col1, col2, ..., aggregate_function FROM table_name GROUP BY col1, col2, ... WITH ROLLUP;Example: What are the number of Stats Club members in each faculty and major, including subtotals?
SELECT faculty, major, COUNT(*) AS num_members FROM member GROUP BY faculty, major WITH ROLLUP;faculty major num_members 0 Art Econ 1 1 Art None 1 2 Math Act Sci 10 3 Math Applied Math 2 4 Math C & O 2 5 Math CS 3 6 Math Pure Math 2 7 Math Stats 14 8 Math None 33 9 None None 34 Note that for Art and Math in faculty there is a row which has a NULL value. This is a total for those groups.
There is also one row with NULL values for faculty and major, this is the grand total of all members.
Quiz: Aggregation (GROUP BY Clause)
Q: What is the attendance for each Stats Club event?
Solutions are here
Joins
At times, we need information from multiple tables, to do this we need to join tables together. We can do this several ways:
- CROSS JOIN: The cartesian product of rows from each table.
- INNER JOIN: Join two tables on a join-predicate, losing rows when evaluated false/null.
-
OUTER JOIN: Retains each record for the table(s) even when it has no matching rows from the other table. The returning table has null values for missing records.
-
LEFT OUTER JOIN: Keep each record for first table but not the table it’s joining with.
-
RIGHT OUTER JOIN: Keep each record for second table but not the table it’s joining with.
-
FULL OUTER JOIN: Keep all record for all tables.
-
- NATURAL JOIN: Tables with the exact same column name and datatype are joined along that column.
CROSS JOIN
CROSS JOIN is the cartesian product of two tables
SELECT col1, col2, ... FROM table1 CROSS JOIN table2;- if table1 has n rows and table2 has m rows, then the result set has n * m rows
We can also get a CROSS JOIN by listing the tables seperated by a ‘,’
SELECT col1, col2, ... FROM table1, table2;Example: Suppose we are creating a games tourtament between Stats Club members where every member play every other member once. How can we create such a table?
SELECT m1.name AS Player_1, m2.name AS Player_2 FROM member AS m1 CROSS JOIN member AS m2;Player_1 Player_2 0 Darrell Aucoin Darrell Aucoin 1 Darrell Aucoin Fred E. Finch 2 Darrell Aucoin Ryan T. Luby 3 Darrell Aucoin Billy L. Hunter 4 Darrell Aucoin John J. Oquendo 5 Darrell Aucoin Stephanie R. Matthews 6 Darrell Aucoin Robert B. Williams 7 Darrell Aucoin Austin K. Gilliard 8 Darrell Aucoin James M. Eddings 9 Darrell Aucoin Elaine S. Ott 10 Darrell Aucoin James A. Foxt 11 Darrell Aucoin Daniel J. Moore 12 Darrell Aucoin Kelly S. Ferguson 13 Darrell Aucoin Joseph L. Wood 14 Darrell Aucoin Vivian R. Donley 15 Darrell Aucoin Frances A. Miller 16 Darrell Aucoin Mina W. Lawrence 17 Darrell Aucoin Phillip C. Mascarenas 18 Darrell Aucoin Jeff M. Wright 19 Darrell Aucoin Deborah D. Helfrich 20 Darrell Aucoin Nancy P. Jackson 21 Darrell Aucoin Bobbie D. Mathews 22 Darrell Aucoin Arnold J. Fuller 23 Darrell Aucoin Melvin O. Martin 24 Darrell Aucoin Ralph L. Waldrop 25 Darrell Aucoin Mildred F. Hottinger 26 Darrell Aucoin Tameika M. McMaster 27 Darrell Aucoin Melissa R. Anderson 28 Darrell Aucoin Janelle T. Smith 29 Darrell Aucoin Ann W. McLaughlin ... ... ... 1126 Patrick Robertson John J. Oquendo 1127 Patrick Robertson Stephanie R. Matthews 1128 Patrick Robertson Robert B. Williams 1129 Patrick Robertson Austin K. Gilliard 1130 Patrick Robertson James M. Eddings 1131 Patrick Robertson Elaine S. Ott 1132 Patrick Robertson James A. Foxt 1133 Patrick Robertson Daniel J. Moore 1134 Patrick Robertson Kelly S. Ferguson 1135 Patrick Robertson Joseph L. Wood 1136 Patrick Robertson Vivian R. Donley 1137 Patrick Robertson Frances A. Miller 1138 Patrick Robertson Mina W. Lawrence 1139 Patrick Robertson Phillip C. Mascarenas 1140 Patrick Robertson Jeff M. Wright 1141 Patrick Robertson Deborah D. Helfrich 1142 Patrick Robertson Nancy P. Jackson 1143 Patrick Robertson Bobbie D. Mathews 1144 Patrick Robertson Arnold J. Fuller 1145 Patrick Robertson Melvin O. Martin 1146 Patrick Robertson Ralph L. Waldrop 1147 Patrick Robertson Mildred F. Hottinger 1148 Patrick Robertson Tameika M. McMaster 1149 Patrick Robertson Melissa R. Anderson 1150 Patrick Robertson Janelle T. Smith 1151 Patrick Robertson Ann W. McLaughlin 1152 Patrick Robertson Judith B. Gibbons 1153 Patrick Robertson Ruben Lamb 1154 Patrick Robertson Dominick Byrd 1155 Patrick Robertson Patrick Robertson 1156 rows × 2 columns
However we have have players playing themselves, and rounds with the same players in opposite roles. We just need to filter these out.
SELECT m1.name AS Player_1, m2.name AS Player_2 FROM member AS m1 CROSS JOIN member AS m2 WHERE m1.name > m2.name;Player_1 Player_2 0 Darrell Aucoin Billy L. Hunter 1 Darrell Aucoin Austin K. Gilliard 2 Darrell Aucoin Daniel J. Moore 3 Darrell Aucoin Bobbie D. Mathews 4 Darrell Aucoin Arnold J. Fuller 5 Darrell Aucoin Ann W. McLaughlin 6 Fred E. Finch Darrell Aucoin 7 Fred E. Finch Billy L. Hunter 8 Fred E. Finch Austin K. Gilliard 9 Fred E. Finch Elaine S. Ott 10 Fred E. Finch Daniel J. Moore 11 Fred E. Finch Frances A. Miller 12 Fred E. Finch Deborah D. Helfrich 13 Fred E. Finch Bobbie D. Mathews 14 Fred E. Finch Arnold J. Fuller 15 Fred E. Finch Ann W. McLaughlin 16 Fred E. Finch Dominick Byrd 17 Ryan T. Luby Darrell Aucoin 18 Ryan T. Luby Fred E. Finch 19 Ryan T. Luby Billy L. Hunter 20 Ryan T. Luby John J. Oquendo 21 Ryan T. Luby Robert B. Williams 22 Ryan T. Luby Austin K. Gilliard 23 Ryan T. Luby James M. Eddings 24 Ryan T. Luby Elaine S. Ott 25 Ryan T. Luby James A. Foxt 26 Ryan T. Luby Daniel J. Moore 27 Ryan T. Luby Kelly S. Ferguson 28 Ryan T. Luby Joseph L. Wood 29 Ryan T. Luby Frances A. Miller ... ... ... 531 Dominick Byrd Daniel J. Moore 532 Dominick Byrd Deborah D. Helfrich 533 Dominick Byrd Bobbie D. Mathews 534 Dominick Byrd Arnold J. Fuller 535 Dominick Byrd Ann W. McLaughlin 536 Patrick Robertson Darrell Aucoin 537 Patrick Robertson Fred E. Finch 538 Patrick Robertson Billy L. Hunter 539 Patrick Robertson John J. Oquendo 540 Patrick Robertson Austin K. Gilliard 541 Patrick Robertson James M. Eddings 542 Patrick Robertson Elaine S. Ott 543 Patrick Robertson James A. Foxt 544 Patrick Robertson Daniel J. Moore 545 Patrick Robertson Kelly S. Ferguson 546 Patrick Robertson Joseph L. Wood 547 Patrick Robertson Frances A. Miller 548 Patrick Robertson Mina W. Lawrence 549 Patrick Robertson Jeff M. Wright 550 Patrick Robertson Deborah D. Helfrich 551 Patrick Robertson Nancy P. Jackson 552 Patrick Robertson Bobbie D. Mathews 553 Patrick Robertson Arnold J. Fuller 554 Patrick Robertson Melvin O. Martin 555 Patrick Robertson Mildred F. Hottinger 556 Patrick Robertson Melissa R. Anderson 557 Patrick Robertson Janelle T. Smith 558 Patrick Robertson Ann W. McLaughlin 559 Patrick Robertson Judith B. Gibbons 560 Patrick Robertson Dominick Byrd 561 rows × 2 columns
INNER JOIN
INNER JOIN Joins two tables where the join condition returns true. Discarded when returning false or NULL.
SELECT col1, col2, ... FROM table1 INNER JOIN table2 ON condition;ON Clause
The ON clause specifies the join condition:
-
The ON clause can use a multiple set of conditions connected by AND, OR
-
USING(
) can also be used if both tables have the same column name and type -
Some SQL implementations constructs the ON clause from the WHERE clause (DB2)
- filtering by the WHERE clause gives the same result but in some implementations will product an intermediate cross product of tables (making the query slower)
Example: How many events does each member attend?
- Note that this query does not include members who attended no events
- Query is ordered by events_attended to show a comparison with a latter query
SELECT m.name, COUNT(a.event) AS events_attended FROM member AS m INNER JOIN attendance AS a ON m.quest_id = a.member GROUP BY m.name ORDER BY events_attended;name events_attended 0 John J. Oquendo 1 1 James M. Eddings 2 2 Melissa R. Anderson 2 3 Melvin O. Martin 2 4 Mina W. Lawrence 2 5 Ann W. McLaughlin 3 6 Bobbie D. Mathews 3 7 Janelle T. Smith 3 8 Mildred F. Hottinger 3 9 Phillip C. Mascarenas 3 10 Ryan T. Luby 3 11 Vivian R. Donley 3 12 Arnold J. Fuller 4 13 Austin K. Gilliard 4 14 Jeff M. Wright 4 15 Kelly S. Ferguson 4 16 Nancy P. Jackson 4 17 Ralph L. Waldrop 4 18 Ruben Lamb 4 19 Billy L. Hunter 5 20 Deborah D. Helfrich 5 21 Dominick Byrd 5 22 Frances A. Miller 5 23 Fred E. Finch 5 24 Joseph L. Wood 5 25 Judith B. Gibbons 5 26 Robert B. Williams 5 27 Stephanie R. Matthews 5 28 Tameika M. McMaster 5 29 Elaine S. Ott 6 30 Daniel J. Moore 7 31 Patrick Robertson 7 OUTER JOIN
OUTER JOIN A join that returns all rows for 1 or 2 tables, even when there is no corresponding value. In these cases, NULL values are entered for these corresponding rows.
There are 3 types of OUTER JOINs:
-
LEFT OUTER JOIN: An OUTER JOIN returning all rows of the table first mentioned.
-
RIGHT OUTER JOIN: An OUTER JOIN returning all rows of the table second mentioned.
-
FULL OUTER JOIN: An OUTER JOIN returning all rows of both tables.
- Only LEFT OUTER JOIN is implemented in SQLite
Example: What are the names of Stat Club members and how many events they attended?
SELECT m.name, COUNT(a.event) AS events_attended FROM member AS m LEFT OUTER JOIN attendance AS a ON m.quest_id = a.member GROUP BY m.name ORDER BY events_attended;name events_attended 0 Darrell Aucoin 0 1 James A. Foxt 0 2 John J. Oquendo 1 3 James M. Eddings 2 4 Melissa R. Anderson 2 5 Melvin O. Martin 2 6 Mina W. Lawrence 2 7 Ann W. McLaughlin 3 8 Bobbie D. Mathews 3 9 Janelle T. Smith 3 10 Mildred F. Hottinger 3 11 Phillip C. Mascarenas 3 12 Ryan T. Luby 3 13 Vivian R. Donley 3 14 Arnold J. Fuller 4 15 Austin K. Gilliard 4 16 Jeff M. Wright 4 17 Kelly S. Ferguson 4 18 Nancy P. Jackson 4 19 Ralph L. Waldrop 4 20 Ruben Lamb 4 21 Billy L. Hunter 5 22 Deborah D. Helfrich 5 23 Dominick Byrd 5 24 Frances A. Miller 5 25 Fred E. Finch 5 26 Joseph L. Wood 5 27 Judith B. Gibbons 5 28 Robert B. Williams 5 29 Stephanie R. Matthews 5 30 Tameika M. McMaster 5 31 Elaine S. Ott 6 32 Daniel J. Moore 7 33 Patrick Robertson 7 Natural Join
NATURAL JOIN A join condition that lets the server decide on the join conditions based on the same column names and types across columns for the tables.
Example: What are the position and duties of each Stats Club exec?
SELECT e.name, e.position, ep.duties FROM exec AS e NATURAL JOIN exec_position AS ep;name position duties 0 Darrell Aucoin President To be aware of MathSoc's Policies and Bylaws i... 1 Darrell Aucoin President To call and preside over general meetings. 2 Darrell Aucoin President To manage the executive team and the strategic... 3 Darrell Aucoin President To post announcements of all club meetings, an... 4 Judith B. Gibbons Events To assist the president and other vice-preside... 5 Judith B. Gibbons Events To chair the organization and promotion of lea... 6 Lamar Roy Finance To ensure membership fees are collected and ma... 7 Lamar Roy Finance To keep an up-to-date record of financial tran... 8 Lamar Roy Finance To prepare a summary of the financial records ... 9 Lamar Roy Finance To prepare the budget at the beginning of term. 10 Lamar Roy Finance To volunteer as president in the absence of th... 11 Gilberto Cross Events To assist the president and other vice-preside... 12 Gilberto Cross Events To chair the organization and promotion of lea... 13 Melba Lane President To be aware of MathSoc's Policies and Bylaws i... 14 Melba Lane President To call and preside over general meetings. 15 Melba Lane President To manage the executive team and the strategic... 16 Melba Lane President To post announcements of all club meetings, an... 17 Ruben Lamb Technology Maintain and update the club website. 18 Ruben Lamb Technology Maintain any hardware, software, or technology... 19 Ruben Lamb Technology Perform the duties of a Vice President - Event... 20 Patrick Robertson Events To assist the president and other vice-preside... 21 Patrick Robertson Events To chair the organization and promotion of lea... 22 Dominick Byrd Events To assist the president and other vice-preside... 23 Dominick Byrd Events To chair the organization and promotion of lea... Quiz: Joining Tables
Q: What are the email addresses and phone numbers of stats club execs who are in change or organizing at least one event?
 Solutions are here
Subqueries
Subqueries are queries contained in queries. These subqueries are contained in ‘(‘, ‘)’
There are two types of subqueries:
-
Non-Correlated Subqueries: Can be run independently of the larger query.
-
Correlated Subqueries: Must be run concurrently with the outer query. They are dependent on the outer query.
Non-Correlated Subqueries
Non-Correlated Subquery: Any valid query within query that if executed by itself will produce a result (including empty set). These are enclosed in ‘(‘, ‘)’ in FROM, WHERE, or HAVING clauses.
Example: What Stats Club execs are in charge of making posters?
SELECT e.name, e.position FROM exec AS e WHERE e.questid IN (SELECT poster FROM event);name position 0 Dominick Byrd Events 1 Gilberto Cross Events 2 Judith B. Gibbons Events 3 Patrick Robertson Events Correlated Subqueries
Correlated Subquery makes references to it’s containing query, executing it for every candidate row referenced. - Correlated subqueries can appear in the SELECT, WHERE, or HAVING clauses.
Example: What majors are the current Stats Club execs enrolled in? - The member table has the information on majors but exec has the information on execs
SELECT name, position, (SELECT faculty FROM member AS m WHERE m.quest_id = e.questid) AS faulty, (SELECT major FROM member AS m WHERE m.quest_id = e.questid) AS major FROM exec AS e;name position faulty major 0 Darrell Aucoin President Math Stats 1 Judith B. Gibbons Events Math Act Sci 2 Lamar Roy Finance None None 3 Gilberto Cross Events None None 4 Melba Lane President None None 5 Ruben Lamb Technology Math Act Sci 6 Hannah Mason SeniorAdvisor None None 7 Patrick Robertson Events Math Stats 8 Dominick Byrd Events Math Pure Math Correlated vs Non-Correlated
-
Correlated subquery is dependent on outer query, non-correlated is independent.
-
Correlated subquery is executed concurrently with outer query, non- correlated is executed before.
-
In general, for speed of execution:
Correlated subquery < Non-Correlated subquery < Joins Quiz: Subqueries
Q: Where can a Non-Correlated subquery can be placed?
Q: Where can a Correlated subquery can be placed?
Q: Using a non-correlated subquery, what are the names, locations, and descriptions of events that served pizza? 1. Break the problem into smaller pieces: What are the events that served pizza? 2. Only retrieve values from the table
eventthatevent.namematches those valuesSolutions are here
Set Operations
Set operations create a combination of rows from 2 tables into one result set. - The tables (or the projection of those tables) have to have the same number of columns and datatypes - if one column appears in a table but not in another, supply the value NULL for the missing column
- UNION: For tables A and B, combines the rows for A and B into one result set.
- INTERSECT: For tables A and B, returns the rows for A and B that they have in common.
- Difference (EXCEPT): For tables A and B, return only the rows in A that are not in common with B.
UNION
UNION operator: Addition of one result set to another result set with the same number of attributes and types.
SELECT ... FROM ... UNION [ALL] SELECT ... FROM ...- Just UNION removes duplicates, while UNION ALL keeps all rows from both result sets.
Example: Suppose are you need to contact everyone involved in Stats Club: members and execs. What are the names, email addresses, and phone numbers (if you have them) of all Stats Club members and execs?
SELECT name, email, NULL AS phone FROM member UNION SELECT name, email, phone FROM exec;name email phone 0 Ann W. McLaughlin ann@uwaterloo.ca None 1 Arnold J. Fuller arnold@uwaterloo.ca None 2 Austin K. Gilliard austin@uwaterloo.ca None 3 Billy L. Hunter billy@uwaterloo.ca None 4 Bobbie D. Mathews bobbie@uwaterloo.ca None 5 Daniel J. Moore daniel@uwaterloo.ca None 6 Darrell Aucoin darrell.aucoin@gmail.com None 7 Darrell Aucoin darrell.aucoin@gmail.com 519-555-1424 8 Deborah D. Helfrich deborah@uwaterloo.ca None 9 Dominick Byrd dominick@uwaterloo.ca None 10 Dominick Byrd dominick@uwaterloo.ca 519-555-2325 11 Elaine S. Ott elaine@uwaterloo.ca None 12 Frances A. Miller frances@uwaterloo.ca None 13 Fred E. Finch fred@uwaterloo.ca None 14 Gilberto Cross gilberto@uwaterloo.ca 519-555-3453 15 Hannah Mason hannah@uwaterloo.ca 519-555-2342 16 James A. Foxt james.fox@uwaterloo.ca None 17 James M. Eddings james@uwaterloo.ca None 18 Janelle T. Smith janelle@uwaterloo.ca None 19 Jeff M. Wright jeff@uwaterloo.ca None 20 John J. Oquendo john@uwaterloo.ca None 21 Joseph L. Wood joseph@uwaterloo.ca None 22 Judith B. Gibbons judith@uwaterloo.ca None 23 Judith B. Gibbons judith@uwaterloo.ca 519-555-2343 24 Kelly S. Ferguson kelly@uwaterloo.ca None 25 Lamar Roy lamar@uwaterloo.ca 519-555-3432 26 Melba Lane melba@uwaterloo.ca 519-555-2322 27 Melissa R. Anderson melissa@uwaterloo.ca None 28 Melvin O. Martin melvin@uwaterloo.ca None 29 Mildred F. Hottinger mildred@uwaterloo.ca None 30 Mina W. Lawrence mina@uwaterloo.ca None 31 Nancy P. Jackson nancy@uwaterloo.ca None 32 Patrick Robertson patrick@uwaterloo.ca None 33 Patrick Robertson patrick@uwaterloo.ca 519-555-2312 34 Phillip C. Mascarenas phillip@uwaterloo.ca None 35 Ralph L. Waldrop ralph@uwaterloo.ca None 36 Robert B. Williams robert@uwaterloo.ca None 37 Ruben Lamb ruben@uwaterloo.ca None 38 Ruben Lamb ruben@uwaterloo.ca 519-555-5232 39 Ryan T. Luby ryan@uwaterloo.ca None 40 Stephanie R. Matthews step@uwaterloo.ca None 41 Tameika M. McMaster tameika@uwaterloo.ca None 42 Vivian R. Donley vivian@uwaterloo.ca None Intersection (INTERSECT Operator)
INTERSECT operator: Returns only tuples that are in common between two result sets. Result sets must be equal in number and type of attributes.
SELECT ... FROM ... INTERSECT SELECT ... FROM ...;Example: What Stats Club execs have also signed up as Stats Club members?
SELECT name, quest_id FROM member INTERSECT SELECT name, questid FROM exec;name quest_id 0 Darrell Aucoin darrell 1 Dominick Byrd dominick 2 Judith B. Gibbons judith 3 Patrick Robertson patrick 4 Ruben Lamb ruben Difference (EXCEPT Operator)
EXCEPT operator: Returns the first result set minus anything it has in common with the second result set.
SELECT ... FROM ... EXCEPT [ALL] SELECT ... FROM ...-
Just EXCEPT uses set theory version of minus.
- If B has a row in common with A then all rows matching that row is removed
-
The optional ALL uses the bag semantics version.
- If B has a row in common with A then only the number of common rows in B rows matching that row is removed
Example: What Stats Club members are not execs?
SELECT name, quest_id FROM member EXCEPT SELECT name, questid FROM exec;name quest_id 0 Ann W. McLaughlin ann 1 Arnold J. Fuller arnold 2 Austin K. Gilliard austin 3 Billy L. Hunter billy 4 Bobbie D. Mathews bobbie 5 Daniel J. Moore daniel 6 Deborah D. Helfrich deborah 7 Elaine S. Ott elaine 8 Frances A. Miller frances 9 Fred E. Finch fred 10 James A. Foxt james.fox 11 James M. Eddings james 12 Janelle T. Smith janelle 13 Jeff M. Wright jeff 14 John J. Oquendo john 15 Joseph L. Wood joseph 16 Kelly S. Ferguson kelly 17 Melissa R. Anderson melissa 18 Melvin O. Martin melvin 19 Mildred F. Hottinger mildred 20 Mina W. Lawrence mina 21 Nancy P. Jackson nancy 22 Phillip C. Mascarenas phillip 23 Ralph L. Waldrop ralph 24 Robert B. Williams robert 25 Ryan T. Luby ryan 26 Stephanie R. Matthews step 27 Tameika M. McMaster tameika 28 Vivian R. Donley vivian WITH Clause
WITH clause: Makes a non-correlated subquery look like a table in the executed statement:
- Increases readability of the query as well as ensure that if it is used in several different places, it will only be executed once
WITH subquery_name [(colname1, ...)] AS (SELECT ...), subquery_name2 [(colname1, ...)] AS (SELECT ...) SELECT ...Example: Suppose you are doing a report for MathSoc detailing Stats Club events, budget, and expenses.
WITH cost (event, expenses) AS (SELECT event, SUM(price) FROM expenses GROUP BY event) SELECT e.name, e.type, e.budget, cost.expenses FROM event AS e INNER JOIN cost ON e.name = cost.event;name type budget expenses 0 BOT social 90.0 58.57 1 EOT social 160.0 160.65 2 Intro to Hadoop educational 90.0 96.81 3 Intro to SQL educational 90.0 102.77 4 Intro to SQL 2 educational 200 62.63 5 Prof Talk educational 90.0 82.87 6 Prof Talk 2 educational 90.0 77.21 7 Prof Talk 3 educational 90.0 75.68 Quiz: WITH Clause (HARD)
Q: MathSoc only provides a maximum cap on social events based on the formula below. What is the max cap for social expenses and is Stats Club over this limit? - Membership fee for Stats Club is 2 dollars
Social expenses = max{250, (MathSoc_Members) * (5 + (Member_fee))} Social expenses = max{250, (MathSoc_Members) * 7} Break the problem into smaller problems: - What are the total expenses for social events? - What is the max budget for social events?
Smaller Problems: - What are the total expenses for social events? - What events are social events?
- What is the max cap for social events?
- What is the result of the formula
(MathSoc Members) * 7 - What are the number of Stats Club members who are in the Math Faculty (aka MathSoc members)? - How do we find the max value between this number and 250?
#### Think about how to solve this for 5 mins
Solutions are here
CASE Expressions
CASE expressions: Similar to a series of if else statements executed for every entry in a table. A new value is returned for every row in the table.
CASE [column] WHEN condition1 THEN result1 WHEN condition2 THEN result2 ... WHEN condition_n THEN result_n [ELSE result] END-
The result can be of any datatype or the result of a correlated or non- correlated subquery (if the result is a single value)
-
CASE expressions are performed by themselves in the SELECT clause or within a function or aggregate function
- CASE expressions within aggregate functions allow us to do counts, sums, averages, etc. of particular occurrences
Example: Suppose like before we are preparing a report for MathSoc, but now we want to give a warning if the event is over budget or not.
WITH cost (event, expenses) AS (SELECT event, SUM(price) FROM expenses GROUP BY event) SELECT e.name, e.type, e.budget, cost.expenses, CASE WHEN e.budget - cost.expenses < 0 THEN 'Over budget' ELSE NULL END AS warning FROM event AS e INNER JOIN cost ON e.name = cost.event;name type budget expenses warning 0 BOT social 90 58.57 None 1 EOT social 160 160.65 Over budget 2 Intro to Hadoop educational 90 96.81 Over budget 3 Intro to SQL educational 90 102.77 Over budget 4 Intro to SQL 2 educational 200 62.63 None 5 Prof Talk educational 90 82.87 None 6 Prof Talk 2 educational 90 77.21 None 7 Prof Talk 3 educational 90 75.68 None Quiz: CASE Expressions
Q: Suppose we are interested in the healthiness of our food options at Stats Club events. A score of various foods was given below. What is the average ‘healthiness’ of Stats Club events?
Food Score donuts -2 pop -2 fries -2 pizza -1 cookies -1 coffee 0 water 2 meals 2 veggie platter 3 Solutions are here
ORDER BY Clause
ORDER BY Clause: Rearranges the rows of a result set according to a tuple of columns.
SELECT column_list FROM table_name ORDER BY column1, column2, .. columnN [ASC | DESC];ASCis ascending (default)DESCis descendingExample: What is the membership list ordered by name?
SELECT name FROM member ORDER BY name;name 0 Ann W. McLaughlin 1 Arnold J. Fuller 2 Austin K. Gilliard 3 Billy L. Hunter 4 Bobbie D. Mathews 5 Daniel J. Moore 6 Darrell Aucoin 7 Deborah D. Helfrich 8 Dominick Byrd 9 Elaine S. Ott 10 Frances A. Miller 11 Fred E. Finch 12 James A. Foxt 13 James M. Eddings 14 Janelle T. Smith 15 Jeff M. Wright 16 John J. Oquendo 17 Joseph L. Wood 18 Judith B. Gibbons 19 Kelly S. Ferguson 20 Melissa R. Anderson 21 Melvin O. Martin 22 Mildred F. Hottinger 23 Mina W. Lawrence 24 Nancy P. Jackson 25 Patrick Robertson 26 Phillip C. Mascarenas 27 Ralph L. Waldrop 28 Robert B. Williams 29 Ruben Lamb 30 Ryan T. Luby 31 Stephanie R. Matthews 32 Tameika M. McMaster 33 Vivian R. Donley LIMIT Clause
LIMIT Clause: Restrict the result set to the first n of rows.
SELECT column1, column2, columnN FROM table_name LIMIT no_of_rows;- We can also offset where the restriction begins
SELECT column1, column2, columnN FROM table_name LIMIT no_of_rows OFFSET row_num;Example: What is the first 10 members ordered by name?
SELECT name FROM member ORDER BY name LIMIT 10;name 0 Ann W. McLaughlin 1 Arnold J. Fuller 2 Austin K. Gilliard 3 Billy L. Hunter 4 Bobbie D. Mathews 5 Daniel J. Moore 6 Darrell Aucoin 7 Deborah D. Helfrich 8 Dominick Byrd 9 Elaine S. Ott Quiz: ORDER BY and LIMIT Clause
Q: What are the top 10 highest priced items in expenses?
Solutions are here
Further Practice Questions?
Quiz: Practice Questions
Q: What events have dates specified?
Q: What events don’t have dates specified?
Q: What Stats Club members are in Stats, Act Sci, or CS? - Recall the
INpredicate operatorQ: What are the Stats Club exec positions? - Avoid duplication of positions
Q: How many different Stats Club exec positions are there? - Note that we can use DISTINCT within aggregate functions
Topics Not Covered
- How to create a database
- Creating tables
- Creating constraints
- Window functions
- Indices
- Views
- How to insert, delete, alter, drop, etc. data in a table
-
R Programming Tutorial
This R programming tutorial was orignally created by the uWaterloo stats club and MSFA with the purpose of providing the basic information to quickly get students hands dirty using R. Fine the original here
Contents:
R Programming 101 (Beginner Tutorial): Introduction to R Presentation
Presentation in html / Presentation in pdf / Source (r markdown)R Programming Reference: complilation of useful information and code snippets
Reference in html / Reference in pdf / Source (r markdown) ## Useful Resources:Learn more R using swirl
R for Statisitical Computing
Download R from CRAN and install
Recommended supplement but not necessary: RStudio from http://www.rstudio.com/products/rstudio/download/
- R Studio: A (very matlab like) IDE for R
Comments
Comments are typed with hashtags ‘#’
# This is a comment cat("This is not a comment")No block comments. So sad. =(
Data Types
### Integers & Numerics Examples: 1,2.0,1.1,pi
c(1,2.0,1.1,pi)Infcan also be used in calculations
1/InfComplex Numbers
We can even use complex numbers.
complex(real = 1, imaginary = 2) 8+6iCharacters
Example: ‘One’, ‘1’, ‘pi’
c('One', '1', 'pi')Boolian (Logical) Values
Boolian values can take only two values:
TRUE(T) orFALSE(F).c(TRUE, FALSE, TRUE)Factors
A factor is a categorical variable that can take on only a finite set of values. i.e. Sex, Faculty in University
factor(c('Male','Female','Male','Male'))Everything is an object, including functions!
Vectors
Most common objects are called vectors.
Examples: vector of numbersa1 <- c(1,2,3) a1a2 <- c('one','two','three') a2a3 <- c('1','2','3') a3You can also create a range of values using
start:end4:10 4:-3 0.1:4Basic Numerical Operations: +, -, *, /, ^
Numerical operations are: +, -, *, /, ^
- These operate elementwise between vectors.Operator Description + Addition - Subtraction * Multiplication / Division ^ Power c(1,2,3) * c(4,5,6)Note: They don’t have to have the same length. If they don’t then the vector will recycle though the shorter vector. The longer has to be a multiple of the shorter vector.
c(1,2,3) ^ c(1,2,3,4,5,6)Logical Operators
- Return a boolan value of
TRUEorFALSE
Operator Description < Less than > Greater than <= Less than or equal to >= Greater than or equal to == Equal to != Not equal to | Elementwise Or & Elementwise And || Or && And c(TRUE, FALSE) | c(FALSE, FALSE)c(1,2,3) < c(2,1,4)Pro Tip: When interacting with number, boolians are converted to an integer: 0, or 1.
Type check
is.(typename)Example:
is.vector,is.integer,is.numeric,is.data.frame,is.matrix- Not sure which type? Use
typeof()!
is.numeric(a1) is.vector(a1) is.data.frame(a1)Assignment Operator
Assignment can come in 3 forms:
var_name <- evaluation
var_name = evaluation
evaluation -> var_namex <- 1 xBe careful: <- is not the same as < -
x < -1y = "string" y"This isn't used much" -> z zConcatenating Vectors
They are different vectors! To concatenate two vectors, use
c(vector.1, vector.2)b12 <- c(a1,a2) b12b23 <- c(a2,a3) b23 b13 <- c(a1,a3) b13b21 <- c(a2,a1) b21Notice that when combined with characters, numerics are changed into characters automatically. So
b23 == b21.b23 == b21b123 <- c(a1,a2,a3)Dot Product
To use dot product of two vectors (instead of elementwise) use
%*%a1 %*% a1 c(1,4,5) %*% c(6,7,2)##Exercise 1. What are the datatypes available in R? 2. What datatype would the vector
c(1,2,"three")be? 3. What is the vectorc(3,4,5,6)to the power of 4? 4. What elements ofc(3,4,5,6)greater than 4?##Answer 1. What are the datatypes available in R? - Numeric - Integer - Complex - Character - Boolian - Factor
- What datatype would the vector
c(1,2,"three")be?- Character
class(c(1,2,"three"))- What is the vector
c(3,4,5,6)to the power of 4?
c(3,4,5,6) ^ 4- What elements of
c(3,4,5,6)greater than 4?
c(3,4,5,6) > 4Lists
Different from vectors, they allow us to put multiple structures in a list.
- Useful when we need to store a list of objects with different datatypesl12 <- list(a1,a2) l12l23 <- list(a2,a3) l23 l13 <- list(a1,a3) l13Notice they are stored in two ‘different arrays’
as.vector,as.listcan interchange list to vectors and vectors to list via as.vector and as.listas.vector(l23) as.list(a1)Exercise
- Generate a vector of 1 to 10, a list of characters 2.1 to 2.5 separated by 0.1
- Add the list to the vector and return a vector
- Define 2 vectors, x1, x2, by using rnorm(7,mean = 13, sd = 5)
- Do the inner product of x1,x2
Answer
q1 = 1:10 #Question 1 q1c = as.list(as.character(seq(2.1,2.5,0.1))) q1 + as.numeric(q1c) # Question 2 x1 = rnorm(7,mean = 13, sd = 5) #Question 3 x2 = rnorm(7,mean = 13, sd = 5) x1 %*% x2 #Question 4Matrix
- Each column needs to contain same type.
- Like a high level vector.
M1 <- matrix(c(1,2,3,4,5,6,7,8,9),nrow=3,ncol=3) M1 M2 <- matrix(9:1 ,3 ,3) M2M3 <- matrix(c(a1,a2),2,3) M3Data Frames
- Generalised matrix. Now we can store different data types in different columns! =)
- Like high level list
df1 <- data.frame(a1,a2,a3) df1Attributes
Attribute Description namesNames of an object dimnamesNames of the dimensions of an object dimDimension of an object classClass of an object lengthLength of an object length(a1)names(a1) = c("a","b","c") a1names(df1) = c("var_1","var_2","var_3") df1dim(M1)Data Manipulation
Indices, just like linear algebra, for vectors, specify thy entry, and matrix row first then column.
a1[2] # Second entry M1[1,2] #First row second column df1[2,3] # Second row third columnM1[1,] # First row M1[,3] # Third columnYou can also Boolian values to get a subset of values:
a1[a1 <= 2]Accessing the elements of a list is slightly different. Use double
[[]]notation:l13[[1]]Assigning names to data.frame and matrices
rownames(M1) <- c('Ein','Zwei','Drei') colnames(M1) <- c('Un','Deux','Trois') M1rownames(df1) <- c('Uno','Dos','Tres') colnames(df1) <- c('yi','er','san') df1Adding new rows or columns into matrix or data.frame
rbind(): Add new row to rbind, cbindM1.rbind <- rbind(M1,M1) M1.rbindM2.rbind <- rbind(M1,M2) # Notice the names of columns and rows M2.rbindM1.cbind <- cbind(M1,M1) M1.cbindCalling by Column Names
df1$yi df1$er df1$sanReading csv/delim files
read.file_type(file = "Name.file_type", header = TRUE, sep = "")Useful functions
attach(iris) head(iris)summary(iris)print(iris)apply, sapply, lapply
- sapply, lapply takes in vectors/list
- sapply(lapply) returns a vector(list) of same length
WARNING: DO NOT USE ANY OF lapply OR sapply under normal circumstances
sapply(iris$Sepal.Width,floor)lapply(iris$Sepal.width,floor)floor(iris$Sepal.Width)Notice that this returns same thing as sapply, so there is no reason to use sapply under most of the cases.
applyis a function to apply a function to a matrix by row or column or both
apply(M2,1,min)# Minimum for each rowapply(M2,2,min)# Minimum for each columnapply(M2,c(1,2),min)# Minimum of all entries, same as min(M2)User define functions
Can predefine default value for argument(s) - Can take in vectors instead of scalars
random.walk <- function(n=1000,p=0.5, start = 0,min = 0, max = 1){ rand <- runif(n = n, min = min, max = max)/(max - min); steps <- sign(2*(rand - p)); out <- start + cumsum(steps); return(out) }plot(random.walk(),type = "l")Exercise
Use the iris dataset in R and build a matrix call iris.matrix with the followings:
1. Columns and rows of iris corresponds to columns and rows of iris.matrix
2. Change the Species column of iris.matrix into the following indicator variables
- 1 - setosa, 2 - versicolor, 3 - virginica
3. Get the mean of every column except for Species column
4. Take away respective mean from each column except for the Species column
5. Produce the summary of the new matrixFuther Notes
browser()is useful to help debugging, talk about this later?function_nameis useful to look up what a function does
Interesting reads:
ggplot2: Plot package based around “the grammer of graphics”data.table: Package showcasing a faster version of data.frameNext Steps:
R Programming Reference: http://rpubs.com/uwaterloodatateam/r-programming-reference
Contribute useful code snippets: https://github.com/uWaterlooDataTeam/r-programming-tutorial
-
How to Install the Python Data Science Stack on Linux or a Remote Linux Server
Beginners Tutorial for How to Get Started Doing Data Science using Servers provided us with a background of why using servers are useful for data scientists and how setup and connect to a server using SSH. In this section we will learn how to install python and the common packages data scientists use with python which we call the PyDataScience Stack. We will also learn how to setup and use Jupyter get started with data analysis with python. This guide should also work for people using Mac and Linux on their local machines.
Anaconda Distribution
Continuum Analytics has developed a Anaconda Distribution which provides an installer and package management for the PyDataScience stack. While being free to use (even for commercial), it is not fully open sourced and their script (.sh file) includes precompiled binary code. Precompiled binary means that there was original source code used to generate the code you would be running. It is not recommended to blindly use precompiled code since the content of the original source code is unknown and can create security flaws on your server. For this reason is better to install packages on our own or using a fully open sourced package manager. If you choose to take the simpler (but not better route) of using the Anaconda distribution the specific instructions for your system (Linux, Mac and Windows) can be found on the downloads page
Installing the PyDataScience Framework Manually
First let us install some common utilities which are useful for using servers:
sudo apt-get -y install git curl vim tmux htop rangerNext let us install python, python development and python-pip:
sudo apt-get -y install python2.7 python-dev python-pipWe an also install some optional python libraries which are popularly used:
sudo apt-get -y install python-serial python-setuptools python-smbusNext we need to set up virtual environments for python. A Virtual Environment is a tool to keep the dependencies required by different projects in separate places, by creating virtual Python environments for them. It solves the “Project X depends on version 1.x but, Project Y needs version 4.x” dilemma, and keeps your global site-packages directory clean and manageable. For example, you can work on a data science project which requires Django 1.3 while also maintaining a project which requires Django 1.0.
Let us get started by installing virtualenv using pip
pip install virtualenvIf that command gave you an error, then it might be necessary to run all pip commands as super user (
sudo pip install virtualenv) insteadNow lets create a folder in the home directory (~/) which will contain the Python executable files, and a copy of the pip library which you can use to install other packages. The name of the virtual environment (in this case, it is data-science) can be anything; omitting the name will place the files in the current directory instead.
cd ~/ mkdir venv pushd venv virtualenv data-science popdNow let us activate our virtual environment.
source ~/venv/data-science/bin/activateThe name of the current virtual environment will now appear on the left of the prompt (e.g. (venv)Your-Computer:your_project UserName$) to let you know that it’s active. From now on, any package that you install using pip will be placed in the venv folder, isolated from the global Python installation. This means that When the virtual environment is activated, when anything is installed using pip, it is installed in the virtual environment, not in your system’s python. This means you can have different version of libraries installed and if an installation breaks, you can simply delete the corresponding venv folder (data-science in this case) and start over without damaging the global Python installation.
If you want to deactivate the virtual environment, it is as simple as using the deactivate command:
deactivateInstalling the Required Python Packages
If the virtual environment is not active, we can activate it again:
source ~/venv/data-science/bin/activateNext let us upgrade our python setup tools and install compilation requirements in python:
pip install --upgrade setuptools pip install virtualenvwrapper pip install cython pip install noseNow that we have all of the requirements, let us begin by installing the SciPy stack
sudo apt-get -y install python-numpy python-scipy python-matplotlib ipython ipython-notebook python-pandas python-sympy python-noseIn the future you might also want to add the NeuroDebian repository for extra SciPy packages but for now let us move onto installing Jupyter notebook:
pip install jupyterJupyer notebook (or “notebooks”) are documents produced by the Jupyter Notebook App which contain both computer code (e.g. python) and rich text elements (paragraph, equations, figures, links, etc…). Notebook documents are both human-readable documents containing the analysis description and the results (figures, tables, etc..) as well as executable documents which can be run to perform data analysis.
Since some packages require matplotlib, we If you are on a Mac or Linux, and pip install matplotlib did not work, you are probably missing the supporting packages zlib, freetype2 and libpng. Let us install the requirements:
sudo apt-get -y install libfreetype6-dev libpng12-dev libjs-mathjax fonts-mathjax libgcrypt11-dev libxft-dev pip install matplotlibNext let us install the requirements for Seaborn, then install Seaborn itself, which is a very powerful statistical plotting library:
sudo apt-get install libatlas-base-dev gfortran pip install SeabornA very complimentary powerful statistics library is statsmodels
pip install statsmodelsLet us now install one of the most powerful and commonly use machine learning library scitKit-learn
pip install scikit-learnNow let us install some other python libraries which commonly used for data science:
pip install numexpr && pip install bottleneck && pip install pandas && pip install SQLAlchemy && pip install pyzmq && pip install jinja2 && pip install tornadoNext let us install two powerful packages for text processing: natural language toolkit and gensim: topic modelling for humans
pip install nltk pip install gensimWe have now installed the most popular python libraries used for data science. There are many more packages which can be installed if necessary, but we have installed enough to get started. If you would prefer to use a dark theme for Jupyter notebook, you can follow the next subsection or you can move onto install R and Rstudio.
Jupyter Notebook Custom Themes (Optional)
This step is optional. Just like any other development environment, with Jupyter notebook, you can change the theme, color scheme and syntax highlighting. I personally prefer dark themes such as Oceans16, you can follow the following steps to choose a different theme.
pip install git+https://github.com/dunovank/jupyter-themes.gitWe are going to install theme (-t) for ipython/jupyter version > 3.x (-J) with the toolbar (-T)
jupyter-theme -J -t oceans16 -TRunning Jupyter Notebook
Before we started running python code on our server, let us set some safety constraints to ensure that our code does not use all the CPU and memory resources. The first step is determining how much memory our system is using using the
freecommand:freeA sample output using the corn-syrup server from uWaterloo’s csclub is the following:
total used free shared buff/cache available Mem: 32947204 981132 201380 271260 31764692 31568324 Swap: 0 0 0Under the total column, the first number is the total memory available in kbytes. This means that there is 32947204 kbytes of RAM total or about 32 GB. It is generally suggested to not exceed 75% of memory to ensure the system does not hang or freeze, but you are free to set the limit to what ever you think is best. You can limit the memory using the following command
ulimit -m 20000000 ulimit -v 20000000
The
-mis for the total memory, and the-vis for the virtual memory. In this example, the limit is set to 20000000 kbytes, which is equivalent to around 20GB.You can see the limits by the following command:
ulimit -aA sample output is the following:
core file size (blocks, -c) 0 data seg size (kbytes, -d) unlimited scheduling priority (-e) 0 file size (blocks, -f) unlimited pending signals (-i) 13724 max locked memory (kbytes, -l) 64 max memory size (kbytes, -m) 20000000 open files (-n) 1024 pipe size (512 bytes, -p) 8 POSIX message queues (bytes, -q) 819200 real-time priority (-r) 0 stack size (kbytes, -s) 8192 cpu time (seconds, -t) unlimited max user processes (-u) 13724 virtual memory (kbytes, -v) 20000000 file locks (-x) unlimitedSpecifically we can see the memory limits by piping the output to the grep command and searching for the keyword memory:
ulimit -a | grep memoryThe output is:
max locked memory (kbytes, -l) 64 max memory size (kbytes, -m) 20000000 virtual memory (kbytes, -v) 20000000Next we can optionally run Jupyter using tmux so that is can run in the background, and not be terminated if you close terminal. Tmux is a very popular terminal multiplexer. What is a terminal multiplexer? It lets you switch easily between several programs in one terminal, detach them (they keep running in the background) and reattach them to a different terminal. This guide outlines how to install and use tmux, and this guide outlines how to configure tmux. We can how install tmux:
sudo apt-get update && sudo apt-get -y install tmuxYou automatically login a tmux session to your default shell with your user account using the following command:
tmuxThe default binding key to send commands to tmux is holding Ctrl and hitting b (Ctrl-b) You can detach by hitting
Ctrl-b dYou can reconnect by running the following command:
tmux attachThe two guides above outline more advanced things you can do with tmux such as creating multiple windows or panes. Once we have set the limits for the memory and are optionally running tmux, we can we can now run Jupyter notebook using the following command:
nice jupyter notebookWe use the nice command to lower the priority of the code running in Jupyter. This is important since if you are running very CPU intensive code, it will run at a lower priority. This means that not only will it not disrupt others using the server (if it is a shared resource) but it will also ensure that the intensive code has a lower priority than important system functions.
When you run Jupyter notebook, it runs on a specific port number. The first notebook you are running will run generally on port 8888 so you can simply navigate to localhost:8888 to connect to Jupyter notebook.
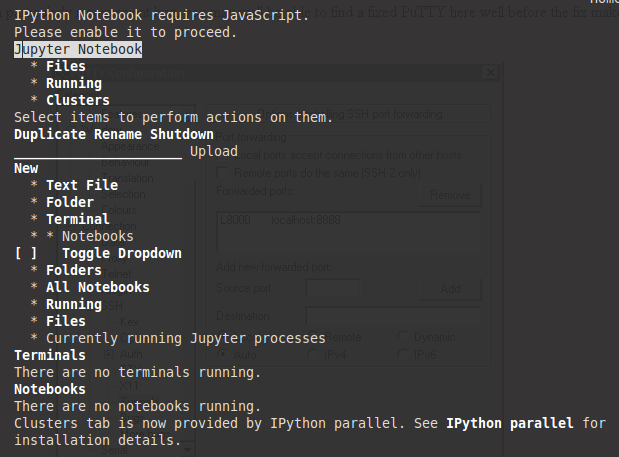
If you are running Jupyter on a a server without a web browser, it will still run but give you an error stating that Ipython notebook requires JavaScipt as shown below. This is expected since JavaScript is not necessary on a server without a web browser. You can type q and then enter on the keyboard and confirm by to closing w3m by hitting y and then enter which will remove the error message (and show you which port Jupyter is running on).
Since you are using tmux you can create a new pane or a new window and run the following command to monitor the system (and Jupyter):
htopIf you are not using tmux, you can open another ssh session to the server the run htop. Using htop, we can move around using the arrow keys, sort the processes by hitting F6, change the priority level using F8 and kill processes using F9. If you are using Mac and following these instructions on your local machine, you will need to run it using a super user (run
sudo htop). In the next section We will learn how to connect to the web browser and use Jupyter as if it was running on your local computer.Since Jupyter was run using nice, all python scripts run in Jupyter will appear in blue on htop indicating that they are running at a lower priority (compared to green and red).
Connecting to the server using SSH Tunneling
In this section we will learn how to connect to Jupyter notebook using SSH tunneling. While SSH tunneling might sound scary, the concept is very simple. Since Juptyer notebook is running on a specific port such as 8888, 8889 etc, SSH tunneling enables you to connect to the server’s port securely. Since we are used to running Jupyter notebook on a specific port number, we can create a secure tunnel which listens on the the server’s port (8888 for example) and securely forwards a port on our local computer on a specific port (8000 for example).
Mac or Linux
If using Linux of Mac, this can be done simply by running the following SSH command:
ssh -L 8888:localhost:8000 server_username@<server ip address>You should change 8888 to the port which Jupyter notebook is running on, and optionally change port 8000 to one of your choosing (if 8000 is used by another process). Your server_username is your username on the server and the
<server ip address>could be an actual IP address or a URL depending on who is providing your virtual machine. In the csclub example, the server_username is your csclub username (generally your quest ID) and the server ip would be for example corn-syrup.uwaterloo.ca. The command I would run if my username is andrew.andrade is:ssh -L 8888:localhost:8000 andrew.andrade@corn-syrup.uwaterloo.caIf no error shows up after running the
ssh -Lcommand and you tunneled the port to 8000 (for example), you can simply navigate to localhost:8000 in your favourite web browser to connect to Jupyer notebook running on the server!Windows
If you are using windows, you can also easily tunnel ssh using putty. As you may remember, you SSH into a server, you enter the server url into the host name as shown in the figure below (for connecting to corn-syrup from the uwaterloo csclub).
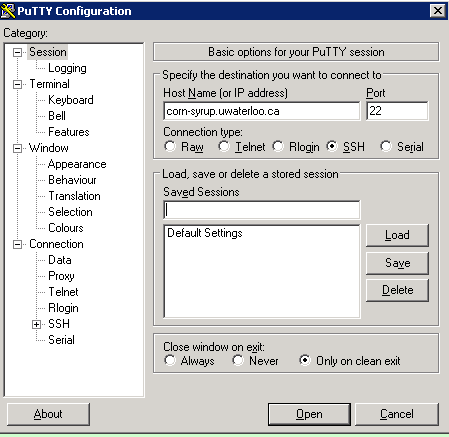
Next click the
+ SSHon the bottom left, and then click tunnels. You can now enter the port you want to access Jupyter on your local machine (for example 8000), and set the destination aslocalhost:8888where 8888 is the number of the port that Jupyter notebook is running on. Now click the add button and the ports should appear in the Forwarded ports: section.For the example of uWaterloo’s csclub, my Putty configuration screen looks like the following:
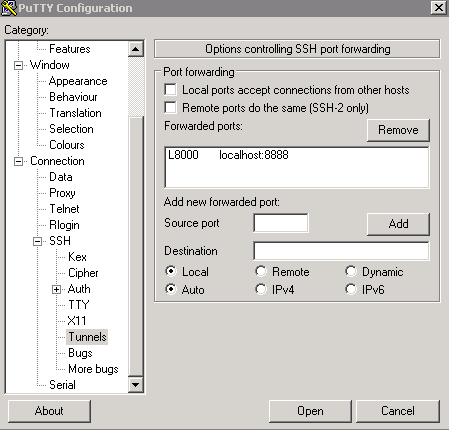
Finally you can hit open, and you will now both connect to the server via SSH and tunnel the desired ports. If no error shows up and you tunneled the port to 8000 (for example), you can simply navigate to localhost:8000 in our favourite web browser to connect to Jupyter notebook running on the server!
Using Jupyter notebook
Jupyter notebook will show all of the files and folders in the directory it is run from. We can now create a new notebook file by click new > python2 from the top right. This will open a notebook. We can now run python code in the cell or change the cell to markdown (by Cell > Cell Type > Markdown) and write notes and even put equations in by putting them between the
$$symbols. For example, to generate you can write the following$$ y = x^2$$You can also download Jupyter Notebooks off the internet and open them in Jupyer. For now let us make a simple plot from the Anscombe’s quartet using the seaborn library. We can do this by just typing the following into the first cell
import seaborn as sns sns.set(style="ticks") %matplotlib inline # Load the example dataset for Anscombe's quartet df = sns.load_dataset("anscombe") # Show the results of a linear regression within each dataset sns.lmplot(x="x", y="y", col="dataset", hue="dataset", data=df, col_wrap=2, ci=None, palette="muted", size=4, scatter_kws={"s": 50, "alpha": 1})Please note we use
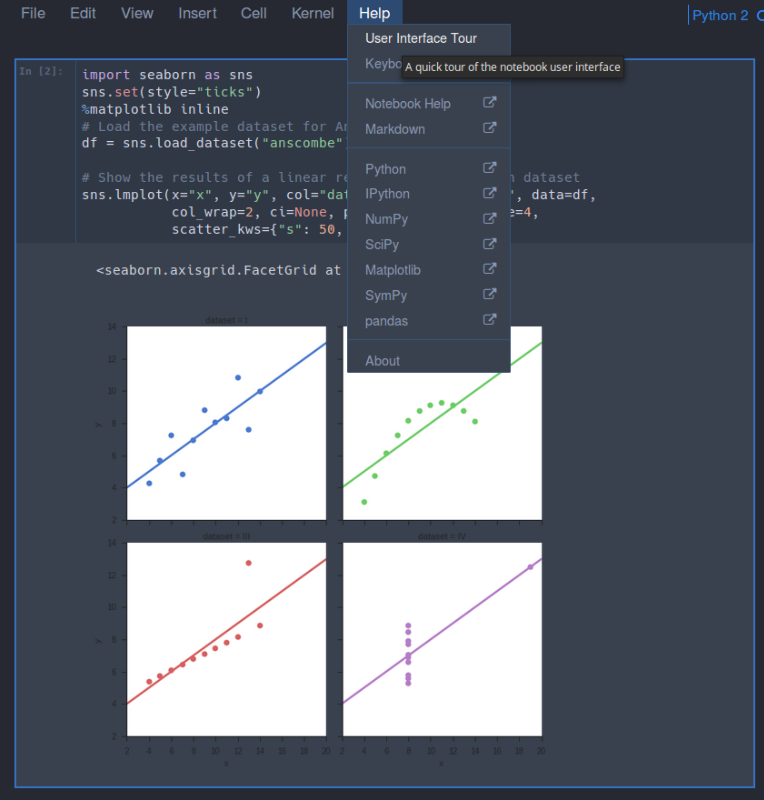
%matplotlib inlinefor the plots to appear inline in the notebook (instead of a pop-up). When using Jupyter Notebook, the easiest way to see a plot is in-line.To get a quick tour of Jupyter notebook, you can go to Help > User Interface Tour as show below:
Once you have installed everything and Jupyter is running you can move onto to installing R and RStudio by following the Absolute Beginners Tutorial for Getting Started Doing Data Science using Servers.
-
Hands on Hadoop tutorial
This tutorial was originally created by Darrell Aucoin for the Stats Club. Follow along with the orginal and additional files here.
In pioneer days they used oxen for heavy pulling, and when one ox couldn’t budge a log, they didn’t try to grow a larger ox. We shouldn’t be trying for bigger computers, but for more systems of computers. —Grace Hoppe
Motivation
Q: Why do we need Hadoop when we have SQL?
Our capability of storing data has outpaced our ability to read it
Harddrives speeds have not improved as fast as their capacity
Processing capacity have bottlenecked, increasing the need for parallelization of tasks
SQL servers do not scale very well in comparison to Hadoop SQL is best for Gigabytes of data, Hadoop for Terabyes/Petrabyes of data SQL skills are still useful in a Hadoop ecosystem (Hive, Spark SQL, Impala)
Q: Who uses Hadoop?
Q: Why learn Hadoop?
According to O’Reilly Data Science Survey,knowledge of Hadoop and related tools are correlated to the highest salaries in Data Science The highest salaries are correlated to joint knowledge of Hadoop and SQL
Hadoop vs RDBMS (SQL)
t SQL Hadoop Data Size Gigabytes Terabyte/Petrabytes Access Interactive and batch Batch Updates Read and write many times Write once, read many times Integrity High Low Scaling Nonlinear Linear Schema Write-on Schema Read-on Schema Data formating Normalized Optimally De-normalized Structure Static schema, highly structured Dynamic schema, Semi-structured When going from a RDBMS to Hadoop, the biggest trade off is the guanrantee of atomicity, consistency, isolation, and durability for scalability.
Write-on Schema: Information is inputted, transformed and written into the predefined schema: we can enforce consistency through this.
Read-on Schema: Bring in files without any predefined gatekeeping or consistency services. The schema is created when reading the files using a set of predefined rules. For instance, a comma seperated file could have it’s first entry interpretated as a string, the second as an integer, the third as a float, etc.
What is Hadoop?
Definition. Hadoop is a MapReduce framework built on top of a distributed file system (HDFS for Hadoop).
Hadoop is distributed system, meaning it’s an interconnected system of computers that looks to the user as just one single entity.
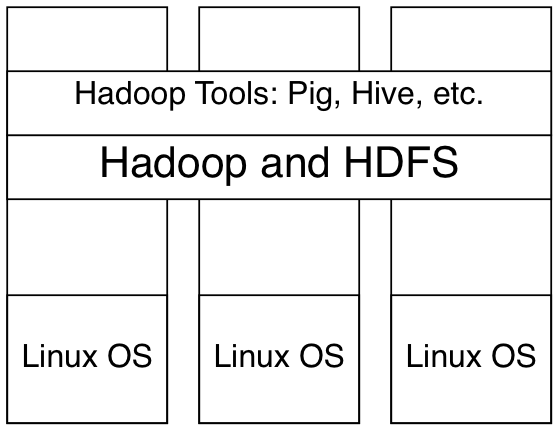
When a client submits a MapReduce Job, the job is split into several tasks and the nodes takes on a fixed number of tasks per node Written in mainly in Java, with some components written in C and bash Designed around processing high throughput of large data rather than response times Hadoop is highly configurable, both in it’s operations and job configurations
Note:
All components and modules have to be installed on every node in a cluster (i.e. to use a module in R, the module has to be installed on every node)
A single node may be running several tasks from several different jobs
Hadoop V1.x and V2.x
Due to compatiability breaking problems with V1.x, V2.x was created: 2.x allows Hadoop Streaming to stream binary data compared to just text with 1.x 2.x is more scalable, 1.x has a bottleneck in it’s design (a singular NameNode) Various Hadoop configuration options changed names
What is MapReduce?
Definition. MapReduce is a programming paradigm model of using parallel, distributed algorithims to process or generate data sets. MapRedeuce is composed of two main functions:
Map(k,v): Filters and sorts data.
Reduce(k,v): Aggregates data according to keys (k).
Hadoop MapReduce Components
###Hadoop 1.x JobTracker Coordinates jobs, scheduling task for tasktrackers and records progress for each job If a task fails, it’s rescheduled on different TaskTracker
TaskTracker Runs tasks and send progress reports to the jobtracker
###Hadoop 2.x ResourceManager: Arbitrates resources among all applications in the system.
ApplicationMaster: A per-application framework tasked with negotiating resources from the ResourceManager and working with the NodeManager(s) to execute and manitor tasks the component tasks.
MRAppMaster: per application
NodeManager: YARN’s per-node agent: Keeping up-to-date with ResourceManager Overseeing individual tasks life-cycle management Constructing a JVM, running the task, then deconstructing the JVM
Monitoring resource usage for each task: memory, CPU Tracking node-health Logging management and auxiliary services
What is HDFS?
Definition. HDFS (Hadoop Distributed File System) is a fault tolerant, distributed, scalable file-system accross multiple interconnected computer systems (nodes).
Fault tolerant means that a single node failure will not halt operations. It does this by replicating the data accross multiple nodes (usually 3).
Distributed means that data is shared accross multiple computer nodes. This means that one node can have data that another node does not. The data nodes can “talk” to each other to balance the data.
Scalable means that performance for clients/node are roughly linear. To increase performance, add new nodes which allows a greater number of clients.
HDFS Components
NameNode The master node: maintains the namespace of the directories and files and manages the blocks on each DataNode.
Usually the most RAM intensive component of HDFS (keeping all metadata of files/directories in memory) - Best to have input files at least a gigabyte in size - The greatest bottleneck for Hadoop 1.x, having only 1 NameNode: too many files requires more ram than the NameNode can provide. Hadoop 2.x uses HDFS Federation, a collection of independent NameNodes.
DataNode Provides the actual storage of the blocks of files.
Secondary NameNode Performs periodic checkpoints of the NameNode and in the event of NameNode failure, can restart the NameNode from last checkpoint (can take a while and a chance of data loss). Secondary Namespace lags behind primary, thus total failure of primary will likely result in data loss Otherwise, copy metadata to secondary and run that as the new primary
Various Hadoop Projects
Hive: Allows users to create SQL-like queries (HQL) and convert them to MapReduce jobs. (
INSERT, UPDATE, DELETEstatements are not allowed).Pig: An easy to learn hadoop-based language that is adept at very deep, very long data pipelines. Very commonly used with DataFu, LinkedIn assortment of User Defined Functions useful for data analysis.
Spark: Another implementation of MapReduce that is more effective for iterative algorithms (machine learning algorithms). Also has built in packages for Spark SQL, and machine learning.
HBase: Non-relational database allowing low- latency, quick lookups in Hadoop. Can do updates, inserts, and deletes.
Oozie: A workflow processing that lets users define a series of jobs written in multiple languages: Hadoop, Pig, and Hive and then link them to one another.
Avro: A data serialization system that allows for encoding the schema of Hadoop files. It is adept at parsing data and performing removed procedure calls.
Mahout: A data mining library using the most popular data mining algorithims for performing clustering, regression testing and statistical modeling and implements them using the Map Reduce model.
Sqoop: A conectivity tool for moving data from non-Hadoop databases (SQL, etc.) into Hadoop.
HCatalog: A centralized metadata mangagement and sharing service for Hadoop, allowing a unified view of all data in Hadoop clusters.
MapReduce Phases
MapReduce is broken down into several steps:
- Record Reader
- Map
- Combiner (Optional)
- Partitioner
- Shuffle and Sort
- Reduce
- Output Format
Record Reader
Record Reader Translates an input into records to be processed by the user- defined map function in the form of a key-value pair on each map cluster.
The key is positional information (the number of bytes from start of file) and the value is the chunk of data composing a single record.
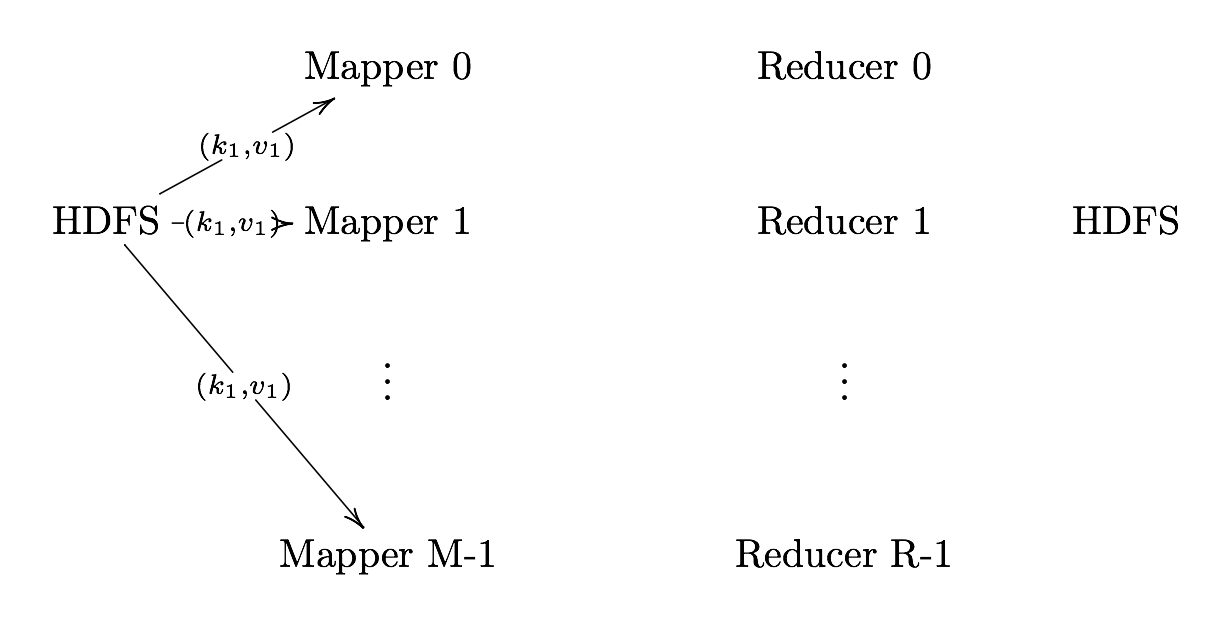
In hadoop, each map task’s is an input split which is usually simply a HDFS block - Hadoop tries scheduling map tasks on nodes where that block is stored (data locality) - If a file is broken mid-record in a block, hadoop requests the additional information from the next block in the series
Map
Map User defined function outputing intermediate key-value pairs for the reducers
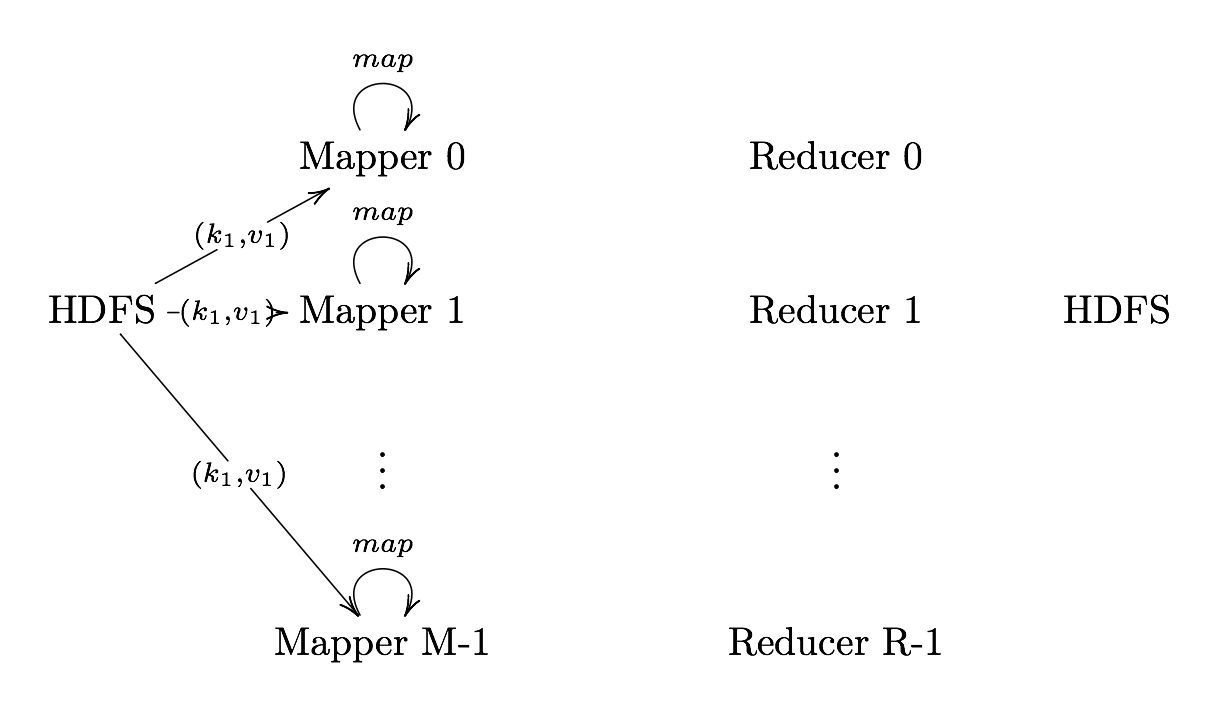
key ($k_{2}$): Later, MapReduce will group and possibly aggregate data according to these keys, choosing the right keys is here is important for a good MapReduce job.
value ($v_{2}$): The data to be grouped according to it’s keys.
Combiner (Optional)
Combiner User defined function that aggregates data according to intermediate keys on a mapper node
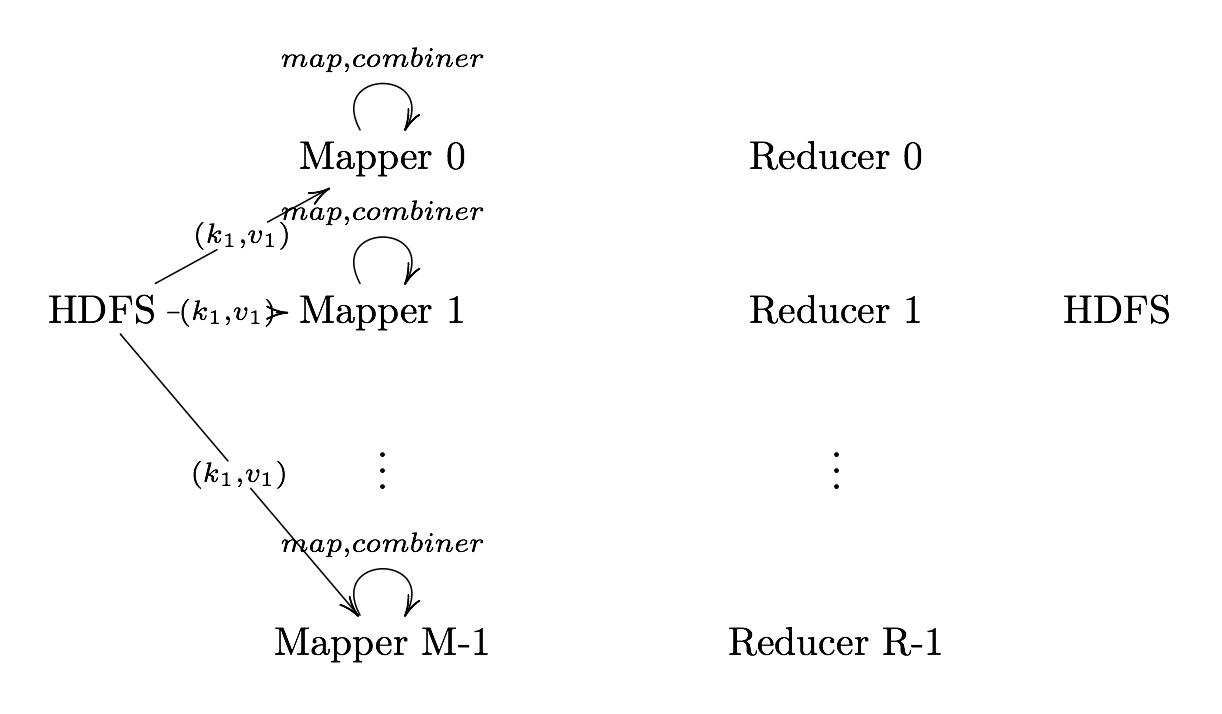
This can usually reduce the amount of data to be sent over the network increasing efficiency
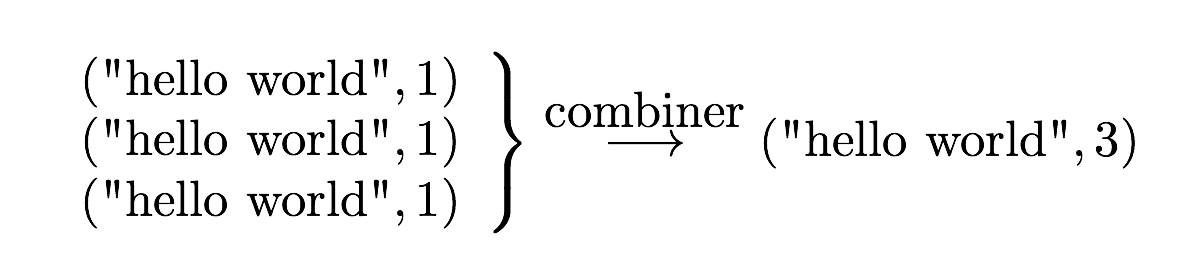
Combiner should be written with the idea that it is executed over most but not all map tasks. ie.
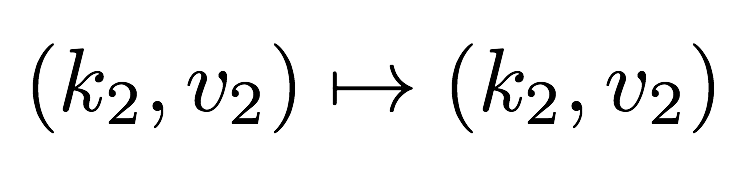
Usually very similar or the same code as the reduce method.
Partitioner
Partitioner Sends intermediate key-value pairs (k,v) to reducer by
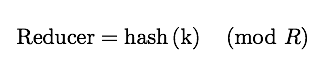
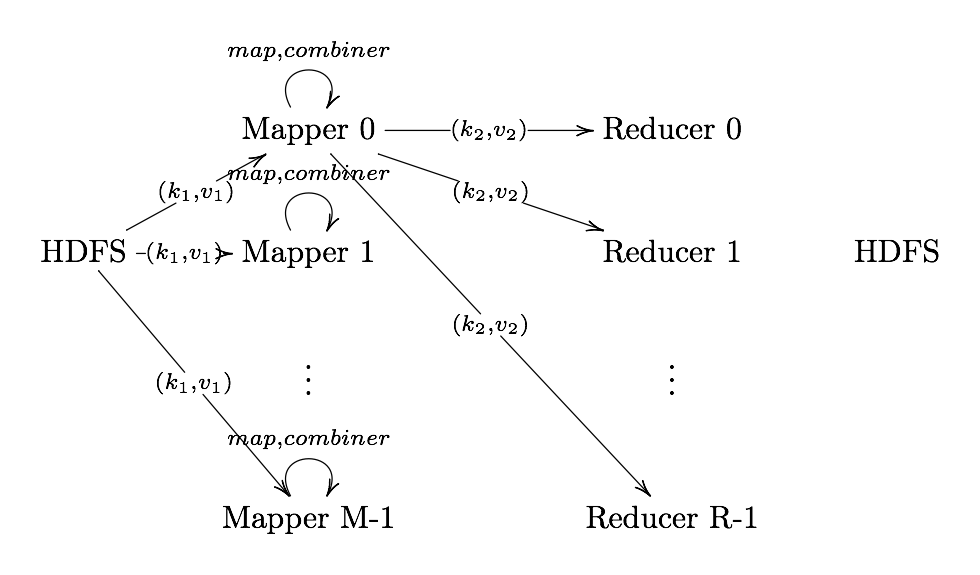
will usually result in a roughly balanced load accross the reducers while ensuring that all key-value pairs are grouped by their key on a single reducer. A balancer system is in place for the cases when the key-values are too unevenly distributed. In hadoop, the intermediate keys ($k_{2},v_{2}$) are written to the local harddrive and grouped by which reduce they will be sent to and their key.
Shuffle and Sort
Shuffle and Sort On reducer node, sorts by key to help group equivalent keys
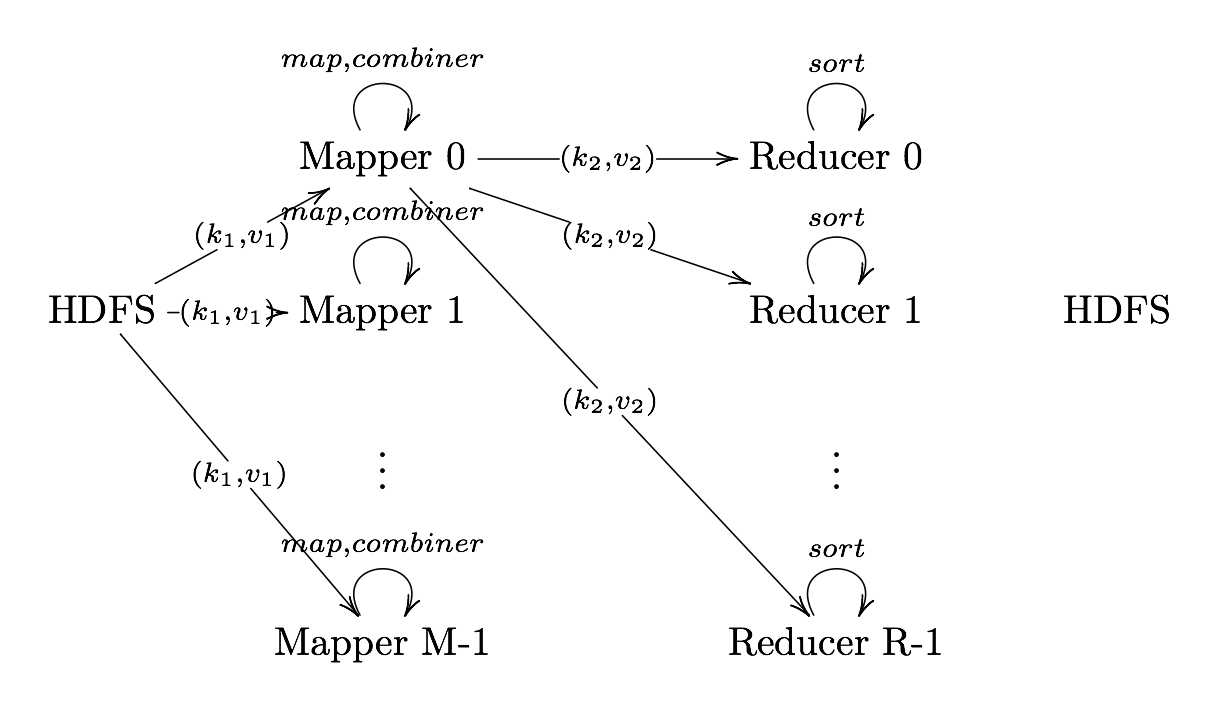
Reduce
Reduce User Defined Function that aggregates data (v) according to keys (k) to send key-value pairs to output
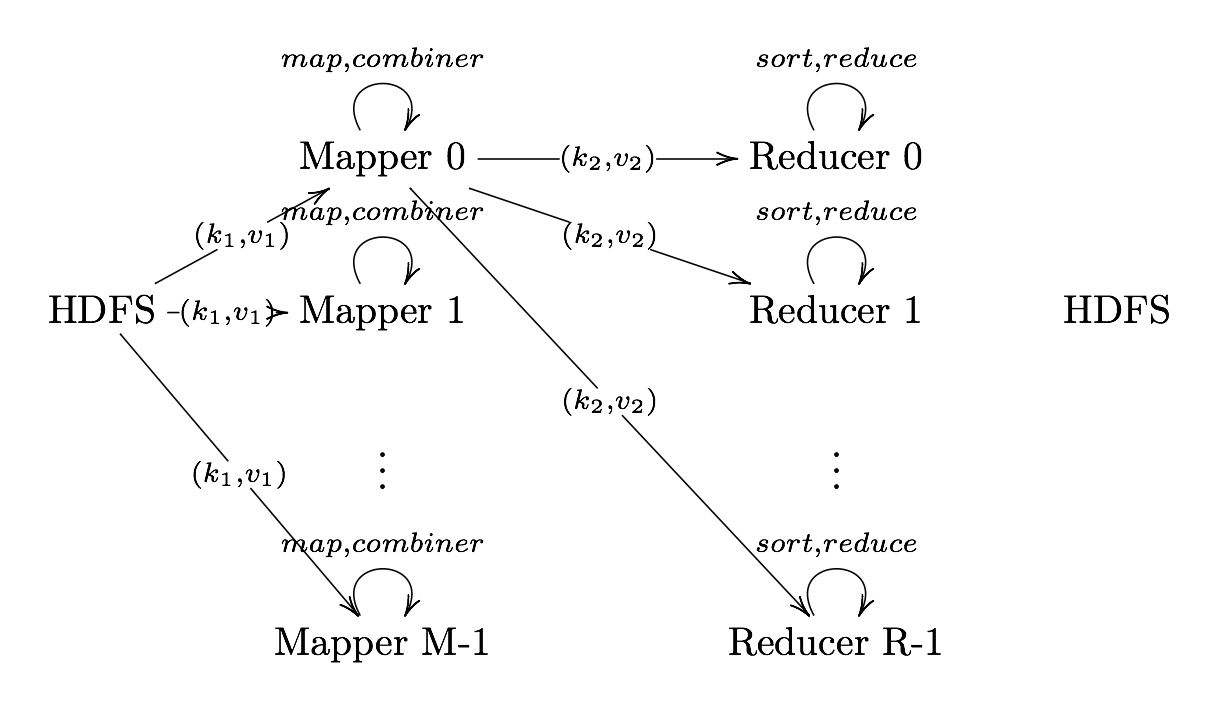
Output Format
Output Format Translates final key-value pairs to file format (tab-seperated by default).
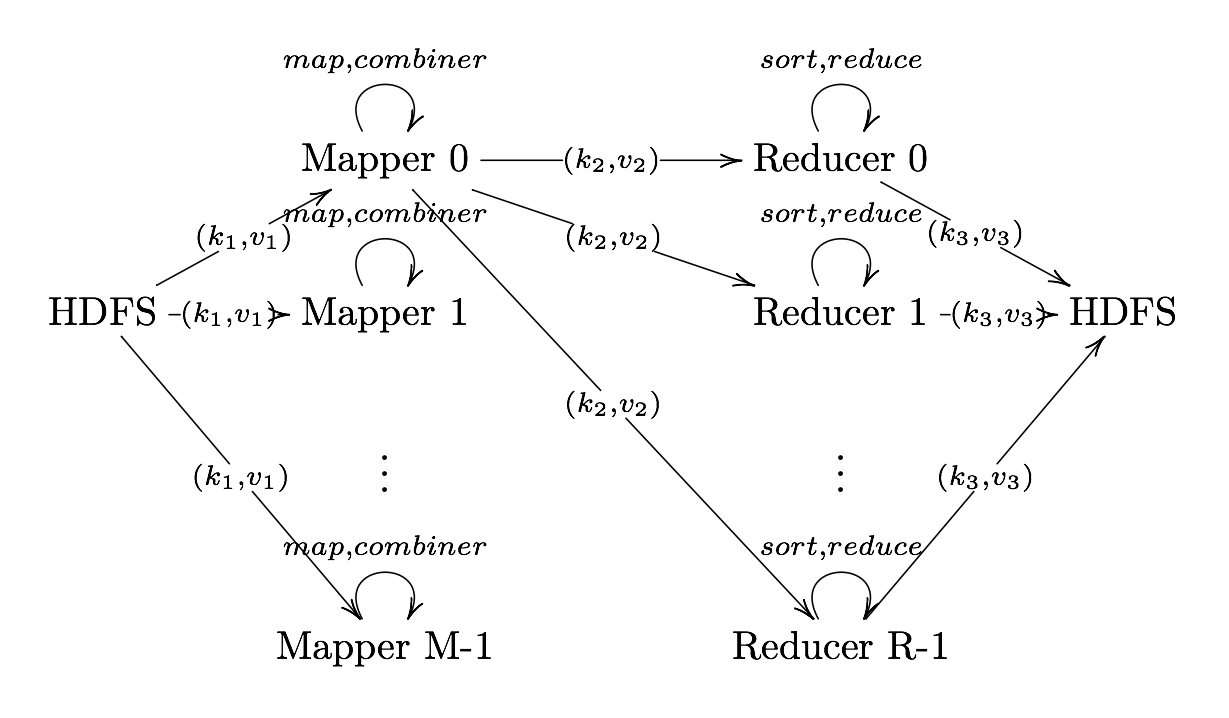
MapReduce Example: Word Count
 Image Source: Xiaochong Zhang’s Blog
Image Source: Xiaochong Zhang’s BlogHDFS Operation
HDFS (Hadoop File System): A distributed file system designed to store huge streamable files running on commodity hardware.
Distributed File System: A file system that manages and stores files across a network of computer allowing files to be parititioned and stored across multiple computer nodes.
Community Hardware: Commonly available hardware. i.e. the computer in front of you.
Huge Files: File sizes from 100MB to petabytes.
Streamable: Documents in HDFS must be able to be partitioned where each partition can be read independently.
A LaTeX document is NOT streamable as the begining of the document defines parameters that are used throught the whole document A comma seperated value (CSV) text document IS streamable as it is readable from any parition of the document
HDFS is not very good with:
-
Low-latency requirements: HDFS is designed with high throughput in mind, usually giving up low-latency access for higher throughput in the design decisions.
-
Lots of small files: The namenode holds the filesystem metadata in main memory, meaning more files in the system means more memory needed in the namenode. Too many files can slow down the cluster or create a system crash.
-
Best to either concatonate files together or compress the files into a compression format that is partitionable (each HDFS block is independently readable)
-
YARN (MapReduce 2) has less problems with lots of small files but is a problem
-
-
Arbitrary file modifications: Files in HDFS can only be written to by a single writer by appending to the end of the file. The file can only be changed at the end as otherwise it would have to shift all of the other bits in the file (including other blocks) around.
HDFS Concepts
HDFS Block: Data stored in HDFS is broken into chucks, 64 MB by default, but 128 MB or 256MB are commonly used, which are spread accross various nodes in HDFS. HDFS blocks are best utitilized by having them evenly distributed across the cluster and sufficiently large to justify creating a JVM for each map task.
The block size is a balance of reduction of head seeks on disk, RAM memory usage of bringing in blocks for map tasks, and distributing the blocks of the file across the cluster
A file smaller than the block will not occupy a full block’s worth of underlying storage
Filesystem maintaince tools fsck can be used to work on blocks
HDFS Federation: For YARN (Hadoop 2.x) allows a cluster to have multiple namenodes which manages mutually exclusive potions of the filesystem namespace.
One NameNode might manage files/directories under /user and another manage /share
Manages a namespace volume: metadata of namespace, block pool (all blocks for files in namespace).
They are independent: if one NameNode fails, the others will still work just fine.
Balancer: HDFS data is not always distributed evenly across the cluster, the balancer moves blocks across the cluster to create a rough balance.
Keep one of the replicas of a block on the same node that it is writing the block
One of the replicas is placed in the same rack as IO is preformed
Spread different replicas across racks to ensure no data loss with loss of a rack (one replica on a different rack)
Failure Recovery
There are several ways that a MapReduce job may fail. Failure recovery is thus built into Hadoop:
- A task failing.
- Exception is thrown. i.e. A corrupt block being read.
- Node running out of memory.
- A task operating too long without a status update.
- A node failing (going offline).
- A NameNode failing (the worst point of failure).
Task Failing
If a map or reduce throws a exeception and it isn’t caught in code, then the task fails.
By default, if a map task fails, then it is first rerun on the same node then tried one last time on a different node.
By default, if a task fails 3 times then the job fails.
Possible Causes of exceptions:
Reading a corrupt block Handle the exception in code (catch the exception) A bad record can be skipped by enabling skipping mode using
SkipBadRecordsclassBad formatting of the file Ensure correct formatting of the file Handle problems in code
Node running out of memory Write memory efficient code
Lack of Updates
After 10 mins, by default, of no updates from a task Hadoop tries to kill the task and rerun the task while running procedures to ensure consistency.
Ensure regular updates: either updating a counter, or writing to stderr (which is then sent to the client) - This is really important for monte carlo simulations on hadoop.
Node Failing
If a DataNode fails, Hadoop tries isolating the node from the system and reassigning tasks that DataNode was operating on.
NameNode Failing
If a NameNode fails then the whole system (or at least a partition of it for 2.x) is down. The system recovers by setting up a new NameNode via the information in the Secondary NameNode as well as the edit logs. However since there is a lag between the NameNode’s operation and edit logs there is almost always data loss after recovery.
- One cause of NameNode failure is too many files in the system:
- The NameNode keeps all metadata for HDFS files in memory, more files means more memory is needed and NameNode failing due to lack of memory.
- It is HIGHLY recommended to keep most if not all data for a MapReduce job in a single file
With Hadoop 1.x can take about 30 mins for a new NameNode to be setup while Hadoop 2.x usually takes a min or two.
Hadoop Operations
Running Hadoop Jobs
Three basic ways of runing MapReduce jobs:
- Java MapReduce MapReduce Job written in Java
- Most efficient method
- Running Hadoop Streaming with other languages: C++, Python, etc.
- Easiest to use but least efficient interface
- Hadoop Pipes: C++ interface using sockets between Java and C++
Java MapReduce
Hadoop is written in Java code, thus one of the main ways of running MapReduce jobs is with Java.
$ hadoop jar <java file> [mainClass] args...Hadoop Streaming
Hadoop Streaming allows Hadoop to use any programming languages with stdin, stdout: C++, Python, Perl, etc.
$ hadoop jar ${HADOOP_HOME}/share/hadoop/tools/lib/hadoop-streaming-*.jar \ -input <InputDirs> \ -output <OutputDir> \ [-file <MapperFileToBeSent>] \ -mapper <MapperFile> \ [-file <ReducerFileToBeSent>] \ -reducer <ReducerFile>Hadoop Cheatsheet gives an outline of how to use this
Remember any files to be used must be sent using -file option (the mapper and reducer nodes need a copy of the files)
Hadoop Streaming: Ver 1.x vs 2.x
Hadoop Streaming for version 1.x can only use text for stdin and stdout, while 2.x is not.
1.x This means that stdin takes in text and then break the text back into the datatypes needed for computations.stdout is a print statement with a tab character seperating keys (\t)
2.x Can do text as well as stream objects Python would use emit() function to pass along each key-value pair instead of printing like in 1.x
Hadoop Pipes
We can connect to Hadoop C++ via pipes operator. Pipes makes a socket connect from Java to C++.
We can run a pipes job by the command:
hadoop pipes \ -input inputPath \ -output outputPath \ -program path/to/C++/executableMapReduce Web UI
For Hadoop you can check on the Hadoop system using the systems web UI. For the local node cluster, the web site URL is:
http://localhost:50070/dfshealth.jsp
http://localhost:8088/cluster
Hadoop Commands
Common HDFS File Commands
Commands for HDFS is very similar to bash
$ hdfs [--config confdir] dfs <Cmd> <args>Cmd args Description args Description -ls-Rpath(s) List files in path(s) -R=including subdirs-catpath(s) Print files in path(s) -mkdir-ppath Create directory -p=including parents-rm-rfile(s)/dir Remove files -r=including subdirectories-putlocalFiles HDFSdir Copy localFiles to HDFSdir Cmd args Description args Description -getHDFSfiles localDir Copy HDFSfiles to localDest -getmergeHDFSfiles localDir Concatenate HDFSfiles to localDest More commands are on the cheatsheet attached
HDFS File Command Examples
$ hdfs dfs -ls15/02/28 14:02:33 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 2 items drwxr-xr-x - darrellaucoin supergroup 0 2015-01-20 16:33 input drwxr-xr-x - darrellaucoin supergroup 0 2015-02-15 16:31 out$ echo "Hello world!" > ~/example.txt$ hdfs dfs -put ~/example.txt /user/darrellaucoin15/02/28 14:02:38 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable$ hdfs dfs -ls15/02/28 14:02:44 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Found 3 items -rw-r--r-- 1 darrellaucoin supergroup 13 2015-02-28 14:02 example.txt drwxr-xr-x - darrellaucoin supergroup 0 2015-01-20 16:33 input drwxr-xr-x - darrellaucoin supergroup 0 2015-02-15 16:31 out$ hdfs dfs -cat example.txt15/02/28 14:02:50 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable Hello world!$ hdfs dfs -rm example.txt15/02/28 14:02:57 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable 15/02/28 14:03:00 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes. Deleted example.txtHadoop Streaming Command
$ hadoop [--config confdir] jar ${HADOOP_HOME}/share/hadoop/tools/lib/hadoop- streaming-*.jar \ [genericOptions] <streamingOptions>####streamingOptions
Cmd args Description -inputdir/filename Input location -outputdir Output location -mapperexecutable Mapper executable -reducerexecutable Reducer executable -filefilename File that needs to be sent to clusters (Mappers, reducer, combiners and other files they need) $ hadoop [--config confdir] jar ${HADOOP_HOME}/share/hadoop/tools/lib/hadoop- streaming-*.jar \ [genericOptions] <streamingOptions>Cmd Description -combinerexecutable Combiner executable -inputformatJavaClassName Java Class specifying format of key-value pairs of text class for input. TextInputFormat is default -outputformatJavaClassName Java Class specifying format of key-value pairs of text class for output. TextOutputFormat is default -numReduceTasksinteger The number of reducers to use $ hadoop [--config confdir] jar ${HADOOP_HOME}/share/hadoop/tools/lib/hadoop- streaming-*.jar \ [genericOptions] <streamingOptions>Be sure to place the generic options before the streaming options, otherwise the command will fail.
####Some genericOptions
Parameter Description -Dproperty=value Set hadoop property to value -filesfile1, file2, … Comma-separated files to be copied to the Map/Reduce cluster MapReduce Properties
Hadoop is highly configurable, both on the admin and MapReduce job side. Most options are for performance tuning but some can do significantly change a MapReduce job - i.e. change the input split to number of lines instead block size (useful for Monte Carlo simulations and web crawling multiple websites)
Debugging Hadoop
Hadoop can run in 3 different modes, 2 of which are are useful for debugging: 1. Local: Hadoop installed an a single machine, everything is run in a single JVM instance, thus making tracking down problems easier. 2. Pseudo-Distribution: Essentially a 1 node cluster. Useful for finding problems related to the distributed nature of Hadoop. 3. Full-Distribution: A hadoop system installed on a cluster.
Counters
Hadoop has various counters associated with a job (i.e. how many map, reduce tasks have run etc.).
Counters have the dual purpose of keeping the system informed that a task is still running as well as metrics on a jobs progress. Custom counters can also be written in Java.
Built-in Counters
For Hadoop 2.x
Group Name/Enum MapReduce Task Counters org.apache.hadoop.mapreduce.TaskCounter Job Counters org.apache.hadoop.mapreduce.JobCounter Filesystem Counters org.apache.hadoop.mapreduce.FileSystemCounter File Input Format Counters org.apache.hadoop.mapreduce.lib.input.FileInputFormatCounter File Output Format Counters org.apache.hadoop.mapreduce.lib.output.FileOutputFormatCounter Task Counters
Counter Description MAP_INPUT_RECORDS Number of input records consumed COMBINE_INPUT_RECORDS Number of input records consumed by combiners REDUCE_INPUT_GROUPS Number of distinct key groups consumed by reducers REDUCE_INPUT_RECORDS Number of input records consumed by reducers MAP_OUTPUT_RECORDS Number of output records by mappers COMBINE_OUTPUT_RECORDS Number of output records produced by combiners REDUCE_OUTPUT_RECORDS Number of output records produced by reducers Counter Description MAP_INPUT_RECORDS Number of input records consumed COMBINE_INPUT_RECORDS Number of input records consumed by combiners REDUCE_INPUT_GROUPS Number of distinct key groups consumed by reducers REDUCE_INPUT_RECORDS Number of input records consumed by reducers MAP_OUTPUT_RECORDS Number of output records by mappers COMBINE_OUTPUT_RECORDS Number of output records produced by combiners REDUCE_OUTPUT_RECORDS Number of output records produced by reducers MAP_SKIPPED_RECORDS Number of skipped input records MAP_INPUT_BYTES Number of uncompressed bytes consumed MAP_OUTPUT_BYTES Number of uncompressed bytes by mappers MAP_OUTPUT_MATERIALIZED_BYTES Number of bytes by mappers to HD REDUCE_SKIPPED_GROUPS Number of distinct keys skipped by reducers REDUCE_SKIPPED_RECORDS Number of input records skipped by reducers REDUCE_SHUFFLE_BYTES Number of map output bytes copied by shuffle to reducers SPILLED_RECORDS Number of records spilled to disk by mappers and reducers CPU_MILLISECONDS Cumulative CPU time for a task in miliseconds PHYSICAL_MEMORY_BYTES The physical memory being used by a task in bytes VIRTUAL_MEMORY_BYTES The virtual memory being used by a task in bytes COMMITTED_HEAP_BYTES Total amount of memory available in the JVM in bytes SHUFFLED_MAPS Number of files transferred from mappers to reducers by shuffle FAILED_SHUFFLE Number of failed file transfers to reducers by shuffle MERGED_MAP_OUTPUTS Number of map outputs that have been merged in reducer BYTES_READ Number of bytes read by mapper and reducers BYTES_WRITTEN Number of bytes written by mappers and reducers SPLIT_RAW_BYTES Bytes of input-split objects read by mappers GC_TIME_MILLIS Milliseconds for garbage collection in tasks File Input Format Counters
| Counter | Description | ||-| | BYTES_READ | Bytes read by mappers |
File Output Format
Counter Description BYTES_WRITTEN Bytes written reducers or (for map-only jobs) mappers Job Counters
Counter Description TOTAL_LAUNCHED_MAPS Number of map launched tasks TOTAL_LAUNCHED_REDUCES Number of launched reduce tasks TOTAL_LAUNCHED_UBERTASKS Number of uber tasks NUM_UBER_SUBMAPS Number of maps in uber tasks NUM_UBER_SUBREDUCES Number of reduces in uber tasks NUM_FAILED_MAPS Number of failed maps NUM_FAILED_REDUCES Number of failed reduces NUM_FAILED_UBERTASKS Number of failed uber tasks DATA_LOCAL_MAPS Number of data local mappers RACK_LOCAL_MAPS Number of rack local mappers OTHER_LOCAL_MAPS Number of non-local rack mappers SLOTS_MILLIS_MAPS Total time running mappers (milliseconds) SLOTS_MILLIS_REDUCES Total time running reducers (milliseconds) Hadoop Streaming and R
Setting Environment Settings for R
Either run the following code in R, each time you need to do a Hadoop job:
#The Hadoop installation directory Sys.setenv("HADOOP_PREFIX"="/usr/local/hadoop/2.*") #The location for Hadoop executable Sys.setenv("HADOOP_CMD"="/usr/local/hadoop/2.*/bin/hadoop") #The location of hadoop streaming jar file Sys.setenv("HADOOP_STREAMING"="/usr/local/hadoop/2.*/share/hadoop/tools/lib /hadoop-streaming-2.*.jar")or include the following into ~/.bashrc file
export HADOOP_PREFIX=${HADOOP_HOME} export HADOOP_CMD=${HADOOP_HOME}/bin/hadoop export HADOOP_STREAMING=${HADOOP_HOME}/share/hadoop/tools/lib/hadoop- streaming-*.jarrmr2: mapreduce
mapreduce Defines and executes a map reduce job. (Pkg rmr2)
mapreduce(input, output = NULL, map = to.map(identity), reduce = NULL, combine = NULL, input.format = "native", output.format = "native", vectorized.reduce = FALSE, in.memory.combine = FALSE, backend.parameters = list(), verbose = TRUE)input Can be:
A set of file paths in HDFS A Big Data Object (a stub of information on some data in HDFS) A list of a combination of both
output A path to the destination folder on HDFS; if missing, a Big Data Object is returned.
map An optional R map function that returns either NULL or a keyval object
reduce An optional R reduce function that returns either NULL or a keyval object
combine refers to:
A function with the same signature and possible return values as the reduce function, or
TRUE, which means use the reduce function as combiner.
NULL means no combiner is used.
input.format Input format specification, see make.input.format

output.format Output format specification, see make.output.format

rmr2: keyval
keyval(key, val) Function that returns key-value pair, only val can ever be NULL. This is what mapper, reducer and combiner functions return.
rmr2: from.dfs
from.dfs Read R objects from HDFS.
from.dfs(input, format = "native")input A valid path to HDFS or a big.data.object
format Either
A string naming the format, or
A value returned by the function make.input.format
rmr2: to.dfs
to.dfs Write R objects to HDFS and return a Big Data Object. (Useful for test purposes only)
to.dfs(kv, output = dfs.tempfile(), format = "native")input A valid path to HDFS or a big.data.object
format Either
A string naming the format, or
A value returned by the function make.input.format
rmr2: keys( ) and values( )
keys Get keys from a big data object or HDFS file path
keys(kv)values Get values from a big data object or HDFS file path
values(kv)rmr2: Preamble
For rmr2 to work, some variables need to be set in bash:
Sys.setenv("HADOOP_PREFIX"="/usr/local/hadoop/2.2.0") Sys.setenv("HADOOP_CMD"="/usr/local/hadoop/2.2.0/bin/hadoop") Sys.setenv("HADOOP_STREAMING"= "/usr/local/hadoop/2.2.0/share/hadoop/tools/lib/hadoop-streaming-2.2.0.jar")Some Useful R Functions
system
system Invokes OS command specified by the character string command. (Pkg base)
system(command, intern = FALSE, ignore.stdout = FALSE, ignore.stderr = FALSE, wait = TRUE, input = NULL, show.output.on.console = TRUE, minimized = FALSE, invisible = TRUE)command Character string to be invoked in terminal.
intern a logical (not NA) which indicates whether to capture the output of the command as an R character vector.
ignore.stdout, ignore.stderr a logical (not NA) indicating whether messages written to ‘stdout’ or ‘stderr’ should be ignored.
wait a logical (not NA) indicating whether the R interpreter should wait for the command to finish, or run it asynchronously. This will be ignored (and the interpreter will always wait) if intern = TRUE.
input if a character vector is supplied, this is copied one string per line to a temporary file, and the standard input of command is redirected to the file.
show.output.on.console, minimized, invisible arguments that are accepted on Windows but ignored on this platform, with a warning.
Example: Command for hadoop to remove previous contents of out
system("${HADOOP_CMD} fs -rm -r /user/darrellaucoin/out")file.path
file.path Construct a path from components to be easily translated accross different OS (Mac, Windows, Linux). (Pkg base)
file.path(...)… character vectors
Example: Command for hadoop to remove previous contents of out
hdfs.root <-'/user/darrellaucoin' input <- file.path(hdfs.root, 'input')strsplit
strsplit Split elements of a character vector x into substrings, split with matches to the regular expression in split argument. (Pkg base)
strsplit(x, split, fixed = FALSE, perl = FALSE, useBytes = FALSE)x character vector
split character vector containing regular expressions to tell when to break the substring. If split has length 0, x is split to individual characters.
perl logical. Should perl-compatible regular expressions be used?
useBytes logical. Should matching be done byte by byte?
Example:
str = 'this is a string' strsplit(str, split = ' ')list
list construct a list from the objects. A list is like a vector that can have different datatypes.
list(x, all.names = FALSE)… objects to coerced into a list
x object to coerced into a list
all.names logical. whether to copy all values or (default) only those whose names do not begin with a dot.
Example:
a.list = list(1,2,3,'string', 2.23, lm(y~x))unlist
unlist Simplifies a list structure x to a vector containing atomic components which occur in x. (Pkg base)
unlist(x, recursive = TRUE, use.names = TRUE)x a list or vector
recurvisve logical
use.names logical. Should names be preserved? Example:
vec = unlist(a.list)write
write
write(x, file = "data", ncolumns = if(is.character(x)) 1 else 5, append = FALSE, sep = " ")x the data to be written
file connection or character string naming the file to written to. For Hadoop, we want to write to standard error (
stderr()) for it to go to the client.ncolumns number of columns to write the data in
append if TRUE the data are appended to the connection.
sep string used to serparate the columns
Example:
write("prints to stderr", stderr())Debugging Hadoop within R
Debugging is essential to running a MapReduce job and ensuring everything is working correctly. As such, we have two functions to help us debugg code:
- rmr.options when we are running on hadoop (either in pseudo-distribution or full-distribution mode). When in hadoop mode, there are several options to collect information to help debug.
When trying to look for bugs it is usually best look in local mode to find potential problems within R, then failing that look in pseudo-distributed mode for any problems (connections problems between R and Hadoop etc.) Profiling works by writing out the call stack every interval seconds, to the file specified
- Rprof when we are running on local mode (using
rmr.options(backend = "local")). When local mode is turned on, hadoop is never run but a simulation of hadoop entirely within R is run, as such Rprof is used to collect any debugging information we might need.
rmr.options Set and get package options. (Pkg rmr2)
rmr.options(backend = c("hadoop", "local"), profile.nodes = c("off", "calls", "memory", "both"), hdfs.tempdir = "/tmp", exclude.objects = NULL, backend.parameters = list())… Names of options to get values of, as length of one character vectors.
backend Use either hadoop, or the current R interpreter, sequentially, for learning and debugging.

profile.nodes Collect profiling and memory information when running additional R interpreters (besides the current one) on the cluster. No effect on the local backend, use Rprof instead. For backward compatibility, “calls” is equivalent to TRUE and “off” to FALSE

Rprof when we are running on local mode (using
rmr.options(backend = "local")). When local mode is turned on, hadoop is never run but a simulation of hadoop entirely within R is run, as such Rprof is used to collect any debugging information we might need.summaryRprofFunctions will only be recorded in the profile log if they put a context on the call stackIndividual statements will be recorded in the profile log if line.profiling is set to TRUE, and if the code being executed was parsed with source references.
Hadoop Examples
Word Count
We want a word count in a text (or group of texts).
Sys.setenv("HADOOP_PREFIX"="/usr/local/hadoop/2.5.2") Sys.setenv("HADOOP_CMD"="/usr/local/hadoop/2.5.2/bin/hadoop") Sys.setenv("HADOOP_STREAMING"= "/usr/local/hadoop/2.5.2/share/hadoop/tools/lib/hadoop-streaming-2.5.2.jar") library(rmr2) library(data.table) system('${HADOOP_CMD} fs -rm -r /user/darrellaucoin/out/') map=function(k,lines) { words.list = strsplit(lines, ' ') words = unlist(words.list) return( keyval(words, 1) ) } reduce=function(word, counts) { keyval(word, sum(counts)) } mapreduce(input='/user/darrellaucoin/input/War_and_Peace.txt', output='/user/darrellaucoin/out', input.format="text", map=map, reduce=reduce ) count = from.dfs('/user/darrellaucoin/out') results = as.data.table(count) setnames(results, c('word', 'count')) results[order(results$count, decreasing=T), ]Linear Regression
To understand the MapReduce framework, lets solve a familar problem of Linear Regression. For Hadoop/MapReduce to work we MUST figure out how to parallelize our code, in other words how to use the hadoop system to only need to make a subset of our calculations on a subset of our data.
Assumption: The value of p, the number of explanatory variables is small enough for R to easily handle i.e.
We know from linear regression, that our estimate of $\hat{\beta}$:
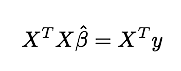
$\left(X^{T}X\right){p\times p}$ and $\left(X^{T}y\right){p\times1}$ is small enough for R to solve for $\hat{\beta}$, thus we only need $X^{T}X,X^{T}y$ to get $\hat{\beta}$.
To break up this calculation we break our matrix $X$ into submatricies $X_{i}$:
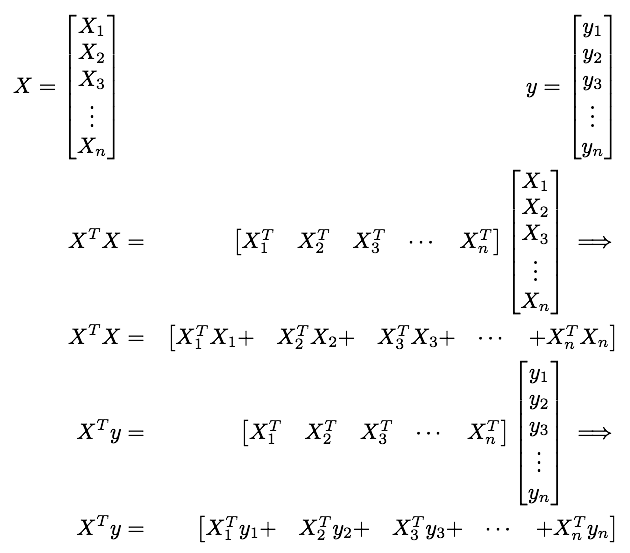
Sys.setenv("HADOOP_PREFIX"="/usr/local/hadoop/2.5.2") Sys.setenv("HADOOP_CMD"="/usr/local/hadoop/2.5.2/bin/hadoop") Sys.setenv("HADOOP_STREAMING"= "/usr/local/hadoop/2.5.2/share/hadoop/tools/lib/hadoop-streaming-2.5.2.jar") library(rmr2) library(data.table) #Setup variables p = 10 num.obs = 200 beta.true = 1:(p+1) X = cbind(rep(1,num.obs), matrix(rnorm(num.obs * p), ncol = p)) y = X %*% beta.true + rnorm(num.obs) X.index = to.dfs(cbind(y, X)) rm(X, y, num.obs, p) map.XtX = function(., Xi) { Xi = Xi[,-1] #Get rid of y values in Xi keyval(1, list(t(Xi) %*% Xi)) } map.Xty = function(., Xi) { yi = Xi[,1] # Retrieve the y values Xi = Xi[,-1] #Get rid of y values in Xi keyval(1, list(t(Xi) %*% yi)) } Sum = function(., YY) { keyval(1, list(Reduce('+', YY))) }The reason we are returning a list in the map function is because otherwise Reduce will only return a some of the elements of the matricies.
list prevents this by Reduce iterating though the elements of the list (the individual $X_{i}^{T}X_{i}$ matricies) and applying the binary function ‘+’ to each one.
list is used in the reduce function
Sumbecause we will also use this as a combiner function and if we didn’t use a list we would have the same problem as above.XtX = values(from.dfs( mapreduce(input = X.index, map = map.XtX, reduce = Sum, combine = TRUE)))[[1]] Xty = values(from.dfs( mapreduce( input = X.index, map = map.Xty, reduce = Sum, combine = TRUE)))[[1]] beta.hat = solve(XtX, Xty) print(beta.hat)15/02/28 16:58:19 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable packageJobJar: [/usr/local/hadoop/2.5.2/hdfs/tmp/hadoop- unjar2544978824408962002/] [] /var/folders/p3/jb65k2x55g1brywqlf6m10p00000gn/T/streamjob622039766772640798.jar tmpDir=null 15/02/28 16:58:20 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 15/02/28 16:58:20 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032 15/02/28 16:58:21 INFO mapred.FileInputFormat: Total input paths to process : 1 15/02/28 16:58:21 INFO mapreduce.JobSubmitter: number of splits:2 15/02/28 16:58:22 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1425160610091_0002 15/02/28 16:58:22 INFO impl.YarnClientImpl: Submitted application application_1425160610091_0002 15/02/28 16:58:22 INFO mapreduce.Job: The url to track the job: http://v1020-wn-6-180.campus- dynamic.uwaterloo.ca:8088/proxy/application_1425160610091_0002/ 15/02/28 16:58:22 INFO mapreduce.Job: Running job: job_1425160610091_0002 15/02/28 16:58:30 INFO mapreduce.Job: Job job_1425160610091_0002 running in uber mode : false 15/02/28 16:58:30 INFO mapreduce.Job: map 0% reduce 0% 15/02/28 16:58:39 INFO mapreduce.Job: map 50% reduce 0% 15/02/28 16:58:47 INFO mapreduce.Job: map 100% reduce 0% 15/02/28 16:58:54 INFO mapreduce.Job: map 100% reduce 100% 15/02/28 16:58:54 INFO mapreduce.Job: Job job_1425160610091_0002 completed successfully 15/02/28 16:58:54 INFO mapreduce.Job: Counters: 50 File System Counters FILE: Number of bytes read=413 FILE: Number of bytes written=311808 FILE: Number of read operations=0 FILE: Number of large read operations=0 FILE: Number of write operations=0 HDFS: Number of bytes read=26712 HDFS: Number of bytes written=546 HDFS: Number of read operations=13 HDFS: Number of large read operations=0 HDFS: Number of write operations=2 Job Counters Launched map tasks=2 Launched reduce tasks=1 Data-local map tasks=2 Total time spent by all maps in occupied slots (ms)=51344 Total time spent by all reduces in occupied slots (ms)=20704 Total time spent by all map tasks (ms)=12836 Total time spent by all reduce tasks (ms)=5176 Total vcore-seconds taken by all map tasks=12836 Total vcore-seconds taken by all reduce tasks=5176 Total megabyte-seconds taken by all map tasks=52576256 Total megabyte-seconds taken by all reduce tasks=21200896 Map-Reduce Framework Map input records=3 Map output records=3 Map output bytes=400 Map output materialized bytes=419 Input split bytes=186 Combine input records=3 Combine output records=3 Reduce input groups=1 Reduce shuffle bytes=419 Reduce input records=3 Reduce output records=3 Spilled Records=6 Shuffled Maps =2 Failed Shuffles=0 Merged Map outputs=2 GC time elapsed (ms)=348 CPU time spent (ms)=0 Physical memory (bytes) snapshot=0 Virtual memory (bytes) snapshot=0 Total committed heap usage (bytes)=531628032 Shuffle Errors BAD_ID=0 CONNECTION=0 IO_ERROR=0 WRONG_LENGTH=0 WRONG_MAP=0 WRONG_REDUCE=0 File Input Format Counters Bytes Read=26526 File Output Format Counters Bytes Written=546 rmr reduce calls=2 15/02/28 16:58:54 INFO streaming.StreamJob: Output directory: /tmp/file72e60803cf9 15/02/28 16:58:55 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable 15/02/28 16:58:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable 15/02/28 16:58:59 INFO fs.TrashPolicyDefault: Namenode trash configuration: Deletion interval = 0 minutes, Emptier interval = 0 minutes. Deleted /tmp/file72e243880be 15/02/28 16:59:01 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable 15/02/28 16:59:03 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable 15/02/28 16:59:05 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable
[,1] [1,] 1.045835 [2,] 1.980511 [3,] 2.993829 [4,] 4.011599 [5,] 5.074755 [6,] 6.008534 [7,] 6.947164 [8,] 8.024570 [9,] 9.024757 [10,] 9.888609 [11,] 10.893023Your Data isn’t THAT BIG
Hadoop has several difficulties and limitations:
Paradigm shift of MapReduce: re-vision (and recoding) algorithms into the paradigm of MapReduce
Debugging code is more difficult than just regular code
Data security isn’t as well defined as most SQL engines
Alternatives
Q: Is there a way of fitting the data in memory?
A gigabyte csv file can be loaded into memory on most computers
Q: Can the process be done reading lines from a file?
R and Python have functions like
readLinesthat can read a file line by lineQ: Can a SQL server handle the information/calculation?
SQL doesn’t require all data to be loaded into memory to execute it’s queries SQL can handle queries over many Gigabytes of data
SQL tables can be indexed (unlike Hadoop) making for faster processing time
R packages like
dplyrcan translate some R-code into SQL queries and can execute said code with a SQL backend Can also execute SQL queries from R, importing the results into a dataframePostgreSQL has an extension (MADlib) allowing Machine Learning algorithms to run over large datasets on PostgreSQL
Q: What if the data isn’t structured for SQL tables? i.e. JSON file, binary blobs
PostgreSQL does have a JSON datatype
Can process the file using a script, reading line by line and then write to file as needed
-
Beginners Tutorial for How to Get Started Doing Data Science using Servers
In this tutorial we will learn how to install and python and R along with the popular packages. By the end of the tutorial we will be able to upload data to the server and do analysis running on a server and yet still have the interfaces data scientists are used to using on their desktops or laptops. We will do this by uploading a sample data (.csv) file to a server and making visualizations in both R and python. Along the way we will learn how to install custom packages, use virtual environments in python, and finally learn how to run and maintain servers running R and Python. We begin by learning why servers are important and useful for data scientists.
Introduction
When a data scientist is working with a larger set of data which requires more computational resources than their desktop or laptop, they use a more powerful computer called a server. A server is generally a very powerful computer which is dedicated to a specific task (for example running a file system, running a database, doing data analysis, running a web application or even all of the above!).
A server with multiple fast processors and large memory allows you to do analysis which is otherwise not possible on a laptop or desktop. For example if you are dealing with a set of data which is 30 GB, one option for a computer with not enough RAM would be to load the data in a database and database analytics. A faster (and arguably better) option would be use a server with enough ram (more than 30 Gb) and all of the analytics in RAM like is done with smaller sets of data.
Before moving on, lets understand idea of the “the virtual cloud” or a group of virtual private servers. A virtual private server (VPS) is a server which you can rent as a service. Being “virtual” means getting full access and control over the server, but you physically never see the server in person or struggle with managing the hardware. Instead of paying thousands of dollars to buy your own server and having to manage and pay upkeep costs, a virtual machine is running in a data center, but you interact with an emulation though command-line or web tools. Being a service means you can use it when you need it and only pay for when you use the resources. What this means is that when your data gets larger you can temporarily use a VPS to quickly do the analysis required without having ever to purchase a server. This is very powerful since you are able to work with larger and larger sets of data in RAM, without ever having to deal with slower database analysis and overhead. While using servers and VMs can be scary at first we will soon learn how fun, useful and simple they are to use!
There are many options for using using a VPS and companies have specialized options for specific applications. For this guide, we are going to use an example of running a VPS from Digital Ocean, but any instructions should be similar for almost any VPS service provider. Digital Ocean provide a solid state drive only based cloud services. Digital Ocean is highly recommend for new users because it has very simple an intuitive control panel, one click Linux installations, and a very active develop community which have updated tutorials. Digital Ocean has one of one of the lowest costs for hosting. Using this link you can get $10 in credit. Since they have spot pricing, if you pause the server when you are not using it, the credit can last you a very long time! If you are a university student, your school might offer free server access. For University of Waterloo Students, for $2 a term, you can become a member of the computer science club and get access to their servers.
The two most common (open sourced) programming languages for doing data science are python (using the PyDataScience stack) and R. Python is a very easy to learn yet powerful programming language. Many data scientists who also work on production systems or applications use python primarily for analysis. The PyDataScience stack includes SciPy, NumPy, Pandas, Scikitlearn and many more open sourced software libraries. We are soon going to learn that all of these libraries are easy to install using
pipor Python Package Index. This means that the development of the packages are contributed and reviewed by hundreds and thousands of people around the world. R is a very powerful mathematical and statistical programming language. Many data scientists who work on the analysis of data use R and is has many statistical packages. R also has its own application development environment which can also be used to build data tools. Similarly topip, the libraries for the R programming language are packages and maintained in The Comprehensive R Archive Network or CRAN.The most common IDE/development tool for doing data science in python is Jupyter notebook. Jupyter Notebook is a web application that allows you to create and share documents that contain live code, equations, visualizations and explanatory text. It is very useful as it enables rapid prototyping and reproducible code. Similarly Rstudio is the most common IDE/development tool for doing data science in R, and it offers the ability for notebook like documents using Rmarkdown and even custom web applications using RShiny. Since Jupyter Notebook and Rstudio are web applications using servers, data scientists can use the same tools they are used to using on their desktops with the added computational power of servers.
Goals:
- Connect to a remote server using SSH
- Install python, virtual environments and packages related to data science
- Connect to Jupyter notebook (a python IDE) using a SSH tunnel and do basic data analysis
- Install R and Rstudio
- Connect to Rstudio and do basic data analysis
- Transfer files between and local server and local machine using SSH
- Transfer a data file and plot in Rstudio and Jupyter notebook
Prerequisites:
You must have access to a simple ubuntu linux server with at 1 GB RAM (the more is better). If using digital ocean, you can follow their guide on how to create your first digital ocean virtual server.
How to SSH
In this section we will learn how to connect to a server using SSH. For Linux and Mac we will learn how to use terminal, and for windows we will learn how to use putty.
SSH or Secure Shell is a cryptographic (encrypted) network protocol to allow remote login and other network services to operate securely over an unsecured network. It enables you access your server for log in, file uploading and even conencting to Jupyter notebook or Rstudio.
If you are using a Linux or Mac computer, you can open terminal and follow this guide for setting up ssh for setting up your ssh key and connecting to the server. If you are using Windows you can follow this guide for setting up ssh on windows where you learn how to download and install putty.
As the guide mentioned, it is highly recommended to use an SSH key, but it is also possible to secure shell using a username and password. In general, once SSH is setup, on Mac and Linux you can connect using
ssh server_username@[server.ip.address.here]For example, with a username of
andrew.andradeI can ssh into uWaterloo’s csclub corn-syrup server (located at corn-syrup.uwaterloo.a) by the following command:ssh andrew.andrade@corn-syrup.uwaterloo.caAnd on Windows you can connect using Putty. As the guide mentioned, you can download the latest version of Putty from here After double clicking to run Putty, you can enter the host name and click open.
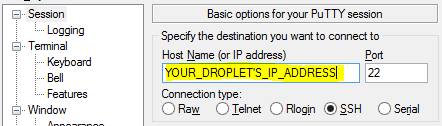
Back to our example, we can connect to corn-syrup by simply entering the URL into putty under the host name and clicking open.
Once you have successfully connected to your server, you should be able to type commands either in the command using terminal (or putty for windows users). Let us first make sure our apt repository index is up to date by typing the following and hitting enter:
sudo apt-get -y updateThe following step is optional, but is is recommended to update the system.
sudo apt-get -y upgradeNext let us install some two build requirements:
sudo apt-get -y install build-essential gfortranThe following are additional build tools which are not required, but are useful when trying to install more libraries in the future.
sudo apt-get -y install build-essential gfortran gcc-multilib g++-multilib libffi-dev libffi6 libffi6-dbg python-crypto python-mox3 python-pil python-ply libssl-dev zlib1g-dev libbz2-dev libexpat1-dev libbluetooth-dev libgdbm-dev dpkg-dev quilt autotools-dev libreadline-dev libtinfo-dev libncursesw5-dev tk-dev blt-dev libssl-dev zlib1g-dev libbz2-dev libexpat1-dev libbluetooth-dev libsqlite3-dev libgpm2 mime-support netbase net-tools bzip2We are now ready to move onto to install python, R and their corresponding common data science framework.
Python and the Python Data Science Stack
Now that we have our system read we can learn how to install the python data science stack on a remote server. Since the process in involved, we create the guided in its own page. You can follow along the guide then return here once you have completed the instructions.
R and Rstudio
In this section we will learn how install and update R along with installing and managing Rstudio sever.
First we must install R. This guide on digital ocean provides very good instructions on how to install R, but I will just include the highlights here.
Since the default location to install R usually includes older versions, we first need to add an updated version to the advanced package tool’s (APT) list located here:
/etc/apt/sources.list. The exact command to use depends on your version of ubuntu but for 14.04 the follow command will work:sudo sh -c 'echo "deb http://cran.rstudio.com/bin/linux/ubuntu trusty/" >> /etc/apt/sources.list'Next we need to add the public key of the authencate package
gpg --keyserver keyserver.ubuntu.com --recv-key E084DAB9Now we can add the key to apt:
gpg -a --export E084DAB9 | sudo apt-key add -Finally we can update apt and install the R base package:
sudo apt-get update sudo apt-get -y install r-baseOnce R has been installed, we can now install Rstudio. First download and install the correct package for your architecture.
Run the following command to see your servers architecture:
archYour system is 32-bit if the output is “i686” or “i386” or it is 64-bit if the output is “x86_64”.
If you are using 64-bit Ubuntu, so execute the following commands:
wget https://download2.rstudio.org/rstudio-server-0.99.491-amd64.deb sudo gdebi rstudio-server-0.99.491-amd64.debIf you are on 32-bit Ubuntu, execute the following commands:
wget https://download2.rstudio.org/rstudio-server-0.99.491-i386.deb sudo gdebi rstudio-server-0.99.491-i386.debSince the wget command downloaded an installation (.deb) file you can delete the file using the rm since we are done using it
rm rstudio-server-*You can now verify the installation by running the following command:
sudo rstudio-server verify-installationIf the commands is successful and there is no output, then you have installed Rstudio, and we can move onto connecting to the Rstudio server (and jupyter notebook) using SSH Tunneling.
Connecting to the Server
Rstudio is generally running on port
8787. This means if you install the server on your local computer (running Linux), you would access it at localhost:8787 in your favourite web browser. Similarly to connect to the server you can connect to it directly navigating tohttp://<server-ip>:8787in your favourite web browser. You can then log into RStudio using the your username and password for the server (or local computer).Installing Packages and Getting Started Doing Analysis using Rstudio
Once Rstudio is running, you can easily install packages by going to Tools > Install Packages… or using the command line at the bottom. We can install one of the most powerful plotting library called Grammar of Graphics or ggplot by typing the following command at the bottom and hitting enter
install.packages("ggplot2")It might ask you to confirm the installation, so type
yto confirm the prompts. Once the library has installed, we can now create our first R script. Go to File > New File > R script. Now type the following:# load the plotting library library(ggplot2) # load the ansombe data into a dataframe anscombe_m <- data.frame() # for each ansombe dataset, reshape the data and plot with linear regression for(i in 1:4) anscombe_m <- rbind(anscombe_m, data.frame(set=i, x=anscombe[,i], y=anscombe[,i+4])) ggplot(anscombe_m, aes(x, y)) + geom_point(size=5, shape=21) + geom_smooth(method="lm", fill=NA, fullrange=TRUE) + facet_wrap(~set, ncol=2)Now you can click Run and you have officially made your first series of plots and analysis in R! The output should look like the following
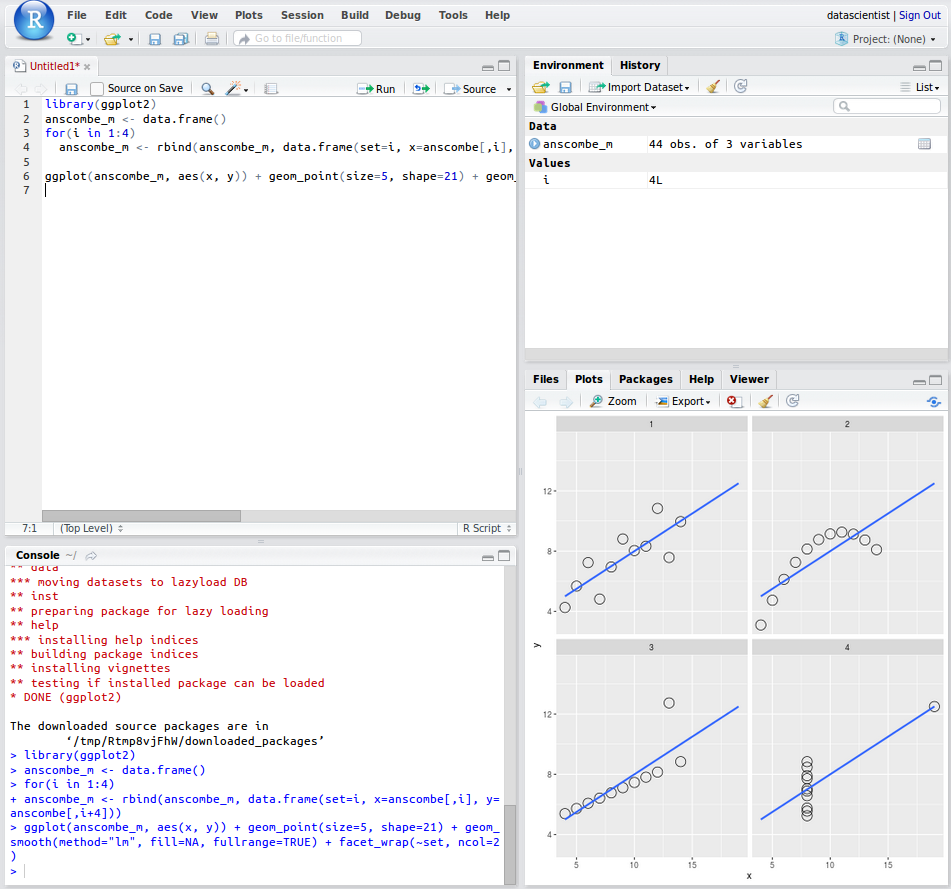
Next let us learn how to transfer data between your local computer and the server.
Securely Transferring Files with a Remote Server
In this section we will learn how to transfer files using SSH. First we will send a data file from our local computer to the server, next we will build a simple model and output the results into a new data file and transfer it back to our local computer.
Using Filezilla (Windows, Linux and Mac)
The Digital Ocean Community page has a great guide with the theory behind on how to How To Use Filezilla to Transfer and Manage Files Securely Filezilla is an opensourced graphical user interface which enables you to send files using different network protocols.
After you download and install the filezilla client, you can connect to it by typing in
sftp://<server-ip>:8787into the Host on the top right, and then the username and password on the server and port22. 22 is the default port for SSH. Once you have entered the details, you can click quickconnect, and it will connect to the server. One the left hand side you will access to your local files, and on right hand side you will access to the servers. You can now drag and drop files between your local computer and the server.Note, if you are using the csclub server, since they have a shared file system you have to transfer files by connecting to csclub.uwaterloo.ca. An example of a connection between the csclub server and my local computer using Filezilla is shown below:
The host name is
sftp://csclub.uwaterloo.caand the username and password is my csclub account. If you are use an SSH key, you can follow the Digital Ocean guide on How To Use Filezilla to Transfer and Manage Files SecurelyLinux and Mac Only
The Digital Ocean Community page has a great guide with the theory behind how to securely transfer files with a remote server, this guide will just summarize the sets and show an example of sending a file from your local computer to a server, doing analysis on the server and then sending the updated file back to your local computer.
First let us download one dataset from the ansombe quartet. We should save the file to a known location such as our downloads folder (
~/Downloads)Now let us connect to the server using sftp:
sftp username@remote_hostname_or_IPFile Transfer Protocol (FTP) is a very popular method for transferring files but can be unsecure. SSH File Transfer Protocol, or Secure File Transfer Protocol (SFTP) is a separate protocol packaged with SSH that works in a similar way over a secure connection. In our example with the csclub corn-syrup server, with andrew.andrade as the username, we can connect using the following command in Linux:
sftp andrew.andrade@corn-syrup.uwaterloo.caWe can now send files from our local computer to the remote server using the
putcommandput Downloads/anscombe_i.csvThe file has now been successfully transfered to the server!
We can also transfer the file back to our local computer using the
getcommandget anscombe_i.csvNotice how the
anscombe_i.csvnow appears in the home directory of our local machine. We now were successfully able to transfer files between the server and the our local computer!You can now start doing your own analysis using the server in both Python and R.
-
Required Background
What background knowledge would be helpful to know as a datascientist? Know of any good (and free) resources? The following list is not complete, so please consider contributing via a pull request or sending me an email with suggestions or edits.
In the previous lesson on What is Data Science? we learnt that it is multifacted and requiers strong scientific analysis to create meaningful results. For this reason, to be a good data scientist, one requires a strong background in math: statistics and computer science as well as linear algebra and multivariable caluclus. Why? Not understanding the fundamentals will lead to incorrect analysis and result is poor decision making.
Most people give more emphasis on statistics (or computer science) over linear algebra and calculus since many of the machine learning algorithms are already implemented (so why learn the math?). While it is true that it is recommended to use already implemented algorithms, it is important to have a fundamental undestranding of how the algorithms are implemented. This way you understand the assumptions in using the algorithm both quickly and correctly.
The required knowledge is broken down into the following sections:
Math
Calculus, Staticstics, Linear Algebra
Computer Science
Basics, Data Structures, Algorithms
Databasing
Relational Algebra, SQL
Important Concepts
Regular expressions, Entropy, Distance measurements, OLAP, ETL, BI VS BA and CAP
Tools
WEKA, Python, R tutorial, SQL Tutorial
Bigdata Tools
Hadoop, Hive, Pig, and many more!
-
Required Computer Science/ Software Engineering Background
Better explanations coming soon! Please consider contributing through a pull request or send edits or suggestions to Andrew
Programming Fundamentals
Basics
Arrays, loops, functions, reading/writing data, objects, vectors, lists, variables, expressions, factors
Udacity’s Intro to Computer Science and Programming Foundations with Python are great resources to both learn programming and python. You can view and learn the course material for free or you can take the course and get extra help.
Data structures
Specifically focus on understanding graphs, trees (binary trees), hash functions, algorithm complexity & big O notation
TODO: find good resource
Algorithms
Searching and manupilating graphs and trees, sorting Algorithms, and searching algorithms.
TODO: find good free resource
Numerical methods
Understand how rounding errors affect calculations.
Next Steps
Once you think you have the required programming background, go can go back to the required background and complete the rest of the modules.
-
Required Background in Math
What background knowledge would be helpful to know as a datascientist? Know of any good (and free) resources? The following list is not complete, so please consider contributing via a pull request or sending me an email with suggestions or edits.
In the previous lesson on What is Data Science? we learnt that it is multifacted and requiers strong scientific analysis to create meaningful results. For this reason, to be a good data scientist, one requires a strong background in math: statistics and computer science as well as linear algebra and multivariable caluclus. Why? Not understanding the fundamentals will lead to incorrect analysis and result is poor decision making.
Most people give more emphasis on statistics (or computer science) over linear algebra and calculus since many of the machine learning algorithms are already implemented (so why learn the math?). While it is true that it is recommended to use already implemented algorithms, it is important to have a fundamental undestranding of how the algorithms are implemented. This way you understand the assumptions in using the algorithm both quickly and correctly.
The required knowledge is broken down into the following sections:
- Precalculus and Mathematical Thinking
- Statistics
- Linear Algebra
- Calculus
Precalculus and Mathematical Thinking
Data is fundamentally represented by numbers, so having a strong foundation in mathematics is very important. The following are links to good resources to provide a background:
Precalculus Mathematical Thinking Introductiuon to Logic Better Explained Math Concepts
When I am learning a new math concept, I usually search it on BetterExplained first to get a more intuitive explanation.
Statistics
Stats is arguably the most important background knowledge required since machine learning is applied statistics. I highly recommend reading StatsBookOnline and going through all the modules. It will provide a very comprehensive foundation the the frequentist approach to statistics. After reading the modules you should have a good understanding of the following topics:
Data basics:
Nominal, ordinal, interval, ratio scales and how to compare
Discriptive Statistics
mean, median, range, standard deviation, variance, and exploratory data analysis
Inferenial Statistics
Probability Theory Random variables Distribution functions (normal, poisson, gaussian) Percentiles and Outliers Skewness Analysis of Variance Prob Desnsity Function Central Limit theorem Monte carlo Hypothesis testing p-value chi^2 estimation confidence interval maximum-likelihood estimation Kernel density estimate regression co-variance corellation pearson coeff causation least squares Factor analysis
Bayesian vs Frequentist Approach
In addition, a data scientist should know the bayesian vs Frequentist approach to statistics and should be familiary with bayes theory and Bayesian Statistics. The notes go into Bayes Theorem.
Further Reading for Stats
Bayesian Statistics
Bayesian Methods for Hackers Monte carlo markov chain
Linear Algebra
What concepts are important?
From here
A lot of machine learning (ML) or applied statistics concepts are tied to linear algebra concepts. Some basic examples, PCA - eigenvalue, regression - matrix multiplication… As most ML techniques deal with high dimensional data, they are often times represented as matrices. Concepts such as singular value decomposition, projections, principal components, eigenvalue, eigenvectors, regression, matrix multiplication, matrix operations, matrix, inverse, solving differential equations using matrices are all important.
For Mathematical Modeling: for example, if you want to capture behaviors (sales, engagement, etc.) in a mathematical model, you can use matrix to breakdown the samples into their own subgroups, and each has its own parameter instead of using a global value. This requires some basic matrix manipulation. Matrix inversion, derivation, solving partial differential or first order differential equations with matrices, for example.For Understanding High Dimensional Distribution: multinomial as the basic example and there are many more.
Good resources:
Matrix Cookbook Khan Academy’s Linear Algebra Videos If you are really having difficulty, you can buy Linear Algebra Done Right which is both a comprehensive guide and provides great intuition. Hands on Linear Algebra for Data Scientists
Calculus
Khan Academy provides a great overview of many of the necessary concepts:
Calculus Integral Calculus MultiVariable Calculus Differential Equations
Calculus and differential equations is very important for methematic modeling of systems and used in optimization.
Once you feel you have the required mathematrical background, you can move onto the other parts of the required background
-
Databases Introduction
Content Coming Soon!
Relational algebra and DB basics
SQL
SQL on Khan Academy is a great resource for learning (and practicing SQL)
Hands on SQL Tutorial with SQLite is guide created by us, in conjuction with Darell Aucoin and uWaterloo’s stats club.
Once you think you understand databases and SQL well enough, you go can go back to the required background and complete the rest of the modules.
-
Information Entropy
Information entropy (more specifically, Shannon entropy is the expected value (average) of the information contained in each message. The following video outlines the concept very well.
Let X be a random variable that takes on n possible values, through . Suppose the probability that is , i.e., , for i = 1 to n. We define the (shannon) entropy of X, call it H(X), as follows:
Where is a specific probability of the event and b is the base. Base 2 is mostly used in information theory and is determined by the unit of information (base 2 = bits, base 3 = trits, base 10 = Hartleys etc.). When used in decision trees, base 2 is usually used since most decision trees are binary trees.
Examples
Complete Certainty (No Uncertainty)
The lowest possible value of H(X) is zero, and this occurs when there is no uncertainty in the probability distribution of X. That is, X can take on only one value, say, , meaning that P(X = ) = 1. Therefore, , … = 0
In this case:
We have have 100% certainty (or no uncertainty), the information entropy is 0.
Equal Uncertainty
The highest possible value of H(X) occurs when there is complete uncertainty about the value of X, i.e., when every possible outcome is equally likely.
50:50
Suppose X is a random variable with two possible outcomes: and , such that . In this case:
Given: and
25:25:25:25
Suppose X is a random variable with four equally likely outcomes. In this case:
Given: p1 = p2 = p3 = p4 = 1/4 = 0.25
Thus, as we increase the number of possible outcomes, the maximum possible value of H(X) increases.
Digital Circuit Example
is the probability of character number i showing up in a stream of characters of the given a simple digital circuit which has a two-bit input (X,Y) and a two-bit output (X and Y, X or Y). Assuming that the two input bits X and Y have mutually independent chances of 50% of being HIGH, then the input combinations (0,0), (0,1), (1,0), and (1,1) each have a 1/4 chance of occurring, so the circuit’s Shannon entropy on the input side is
Now lets say the possible output combinations are (0,0), (0,1), and (1,1) with respective chances of 1/4, 1/2, and 1/4 of occurring. The circuit’s Shannon entropy on the output side is
The circuit reduces (or orders) the information going through it by half a bit of Shannon entropy (due to its logical irreversibility).
Further Reading
-
Important Concepts
What important concepts are critical to know datascientist? Know of any good (and free) resources? The following list is not complete, so please consider contributing via a pull request or sending me an email with suggestions or edits.
In the previous lesson on Required background we listed a long list of required subjects which are related to learning data science. In this lesson we outline very important concepts which are critical to know and understand when doing data science. Please do not skip this section!
We cover the following topics: 1. Regular Expressions 2. Information Entropy 3. Distance measurements 4. OLAP 5. ETL 6. Business Analytics vs Business Intelligence 7. CAP theorem
Regular Expressions
Regual Expressions are extremely useful! They are a sequence of characters that define a search pattern, mainly for use in pattern matching with strings, or string matching, i.e. “find and replace”-like operations. They are very powerful and are used commonly in data cleaning (other wise known as data munging or wrangling). They are also used in text editors, and Unix utilities such as ed, grep and filter.
For example if you wanted so search for an email address in a text the following regular expression ca be used: \b[A-Z0-9._%+-]+@[A-Z0-9.-]+.[A-Z]{2,}\b
Yes, regular expressions initially are uninterpretable, but luckily there are useful free online tools such as Regexpal or Regexr to help you. I usually just search the web or search for common for a specific regular expression I am interested in, but reading online introduction to regex guides helped me to learn to write my own. Next time you are searching for something in your text editor, try using regular expressions (even for simple searches) and getting practice will help with complicated searchs with dirty data.
Information Entropy
Since information entropy is a very important topics and is used in decision trees, we created its own page not to crowd this page.
Distance measurements
Since distance measurements is a very important topics and is used in clustering and k nearest neighbor, we created its own page not to crowd this page.
OLAP
OLAP is an acronym for online analytical processing, which is a computer-based technique of analyzing data to look for insights. The term cube here refers to a multi-dimensional dataset, which is also sometimes called a hypercube if the number of dimensions is greater than 3. The wikipedia article has a great outline about the concept.
ETL
ETL or Extract, Transform and Load refers to a process in database usage and especially in data warehousing that:
- Extracts data from homogeneous or heterogeneous data sources
- Transforms the data for storing it in the proper format or structure for the purposes of querying and analysis
- Loads it into the final target (database, more specifically, operational data store, data mart, or data warehouse)
Business Analytics vs Business Intelligence
Business Analytics vs Business Intelligence
CAP theorem
Before learning “big data” or distributed systesm, one must understand CAP theorem. In short, CAP theorem also known as Brewer’s theorem, states that it is impossible for a distributed computer system to simultaneously provide all three of the following guarantees: 1. Consistency (all nodes see the same data at the same time) 2. Availability (a guarantee that every request receives a response about whether it succeeded or failed) 3, Partition tolerance (the system continues to operate despite arbitrary partitioning due to network failures)
Here is a plain english explation which explains it better than I could.
Once you have read through the topics, you can move onto learning differents tools for data science.
-
Distance Measurements
Distance measurements are very important since they are used in clustering and nearest neibour algorithms. The Scipy library has an implemention of common distance computations. The common ones are outlined below:
Better figures, formulas and examples coming soon!
1. Numeric Attributes
Euclidean Distance: ordinary straight line distance between two points.
Given two points p and q:
Manhatten Distance: Distance a cab would drive (on a city grid)
2. Discrete
1 if the same, 0 if different
3. Itemsets (binary attributes)
Jaccard similarity
4. Text data/vector angles
Cosine similarity
-
Open Source Tools for Data Science
Many tools for datascience exist. One can start with excel since it is the most basic for dealing with tabular data, later we focus on open source tools: first with workbenches/ interfaces and then programming frameworks.
I personally recommend python if you are interesting in doing analysis and build production systems. Python is easy to learn and in high demand in industry. If you want to focus on analysis and want access to more statistical packages (instead of a general programming language) I recommend R. If you do not want to code, WEKA might have the functionality you are looking for.
Why open source?
Open sourced tools are recommended since they based upon open innovation and collaboration of many people. Many of the world’s best companies contribute to open source projects and work on building amazing tools. With open sourced tools you can view the soruce code, contribute without being not tied down or expensive licenses (or have to deal with license issues). Most open sourced tools worked cross platforms (windows, mac and linux).
Running servers
While dealing with small data is managable on your personal computers, as data gets larger or more complex, there is more an more a need to run analysis on more powerful dedicated machines called servers. We recommend to use your personal machines to get started with small sets of data, learning how to run servers, being familiar with the commandline and using a server to do your data analysis is recommended. This is because servers generally have more RAM than your local computers and are able to deal with medium to large data. Learning how to use servers will also help when you are dealing with big data when you need a distributed network of computers.
For this reason we recommend using python or R since both of them can run on servers in the same way they run on your local computers (using Rstudio, ipython notebook for example).
Excel / Open Office
Pros: 1. most basic tool you can use and simple to use for easy tasks 2. Commonly found on most windows/ mac computers 3. Visually see the data
Cons: 1. Slow and uses lots of RAM 2. Lack of standard packages and functionality 3. Crashes with small/medium sized data 4. Costs money
I personally recommend staying away from Excel and get the in the habit of writing code (as we will outline why later).
WEKA
Java based data mining workbench made by the University of Waikato.
Pros:
- graphical user interface (click to do things)
- great functionality and many data mining packages
- cross platform (windows, mac, linux)
- Great out of the box visualizations and functionality
Cons:
- stores all of data in RAM (can crash/run slow with medium data)
- Advanced tools are lacking (compared to R or Python)
- Industry does not use WEKA, Python and R have become standards for many jobs
- Difficult to run on a remote server
WEKA is great for quick analysis and for if you do not want to learn how to code. The issue with using a GUI is that the results are not reproducable and you manually have to do analysis. By writing code the results are reproducable and it scales better. This means that it works for larger sets of data and it involves small amount of work to do the analysis for a new set of data. There are also a number of other java based machine learning tools which I have not used. This link outlines other options than WEKA.
How to install and getting started:
You can download Weka here
Python + datastack (Scipy + Scikitlearn + other packages)
Pros:
- Extensive, full featured popular programming language
- Easy to learn and get started
- Many packages, guides, tutorials
- Full customability
- Have to write code (analysis is reproducable)
Cons:
- Not as fast performance as other languages
- Have to learn to write code
- Have to install many packages
- Fewer statistical functions compared to R
I personally recommend Python since it is a good skill to have. Python is used more on the engineering side of data science. This means python is more commonly used to build data products compared to just doing analysis.
How to install and getting started:
The simpliest and arguagable best way to install python and the requicked packages for data science is through the Anaconda Python distribution created by Continuum. Their GUI will save you a lot of time and the modules it doesn’t provide out of the box can easily be installed via a GUI. The distribution is also available for all major platforms (windows, linux mac). To save time and headache please use the Python 2.7 installer. I also wrote a guide for how to install the data science stack in python here if you perfer to install it manually.
Python 2 also has many (free) tutorials and courses online: http://docs.python-guide.org/en/latest/intro/learning/ My favourite resources: https://docs.python.org/2/tutorial/introduction.html https://docs.python.org/2/tutorial/ http://learnpythonthehardway.org/book/ https://www.udacity.com/wiki/cs101/%3A-python-reference http://rosettacode.org/wiki/Category:Python
Once you are familar with python, the first part of this guide is useful in learning some of the libraries we will be using:
http://cs231n.github.io/python-numpy-tutorial/
[R]
Pros: 1. Many statistical packages 2. Easy to learn and get started 3. Many packages, guides, tutorials 4. Full customability 5. Have to write code (analysis is reproducable)
Cons: 1. Loads data into memory 2. Have to learn to write code 3. Have to install many packages 4. Programming paradigm is different than python or java (more similar to matlab since everything is represented as a vector)
If you are more focused on doing analysis then R is usually a better option. Many data scientits have told me that they can do anlaysis faster in [R] but use python to implement products.
How to install and getting started:
You can download [R] from the offical website or follow the guide here. I also recommend installing and using Rstudio and MATLAB like environment for R. You can also find my guide here to installing R and RStudio for Linux or a Linux server.
With the stats club at uWaterloo, I presented a getting started with R tutorial which can found here and a reference guide here. There are also many other data science tutorials you can find on the web.
Paid Alternatives:
Matlab, Azure ML, SAS Enterprise Miner, IBM SPSS, and many others.
Pros: - Lots of features - Includes all packages required - Large scientific community (used by many universities and large companies)
Cons: - Algorithms are proprietary (trust that they were implemented correctly) - Expensive (used by people with sufficient funds to buy a license) - Portability (the ability to run your code on someone elses computer) - Few third party extensions (compared to open source)
Database tools
There are many database tools which exist with many in the works. The big data tools page outlines other database tools, but the most basic tool is a relational database. Three popular opensourced relational databases are SQLlite, MySQL and PostgreSQL (postgres). They are very similar in their SQL language, but SQLlite offers are more limited number of features (and is great for beginners) compared to MySQL or PosgreSQL. MySQL is commonly used in industry and PosgreSQL is also commonly used in industry for geographical data (due to additional packages)
Big data tools and Next Steps
We created a section for big data tools which outline popular opensource tools for big data. This section is optional for now (until you get to big data). If you want to move on, you can go to the DataScience Framework.
Further reading:
-
Big Data Tools
Popular Hadoop Projects
Hadoop: A distributed file system and MapReduce engine YARN.
Spark: An in-memory based alternative to Hadoop’s MapReduce which is better for machine learning algorithms.
Spark SQL, MLlib (machine learning), GraphX (graph-parallel computation), and Spark Streaming.
Storm: Distributed tool for processing fast, large streams of data.
Cassandra: NoSQL system implemented on Hadoop.
Hive: Allows users to create SQL-like queries (HQL) and convert them to MapReduce.
HCatalog: A centralized metadata management and sharing service for Hadoop, allowing a unified view of all data in Hadoop clusters.
Pig: An easy to learn hadoop-based language that is adept at very deep, very long data pipelines.
Mahout: A data mining library using the most popular data mining algorithms using the Map Reduce model.
Non-Hadoop Projects
NoSQL (Not Only SQL): A database that is not based storage and retrieval of tabular relations used in relational databases. Some can provide a distributed database.
Examples: MongoDB, CouchDB, Accumulo, and some NoSQL databases are implemented on Hadoop: Cassandra, HBase.
SQL: Can spill to disk allowing datasets to be larger than memory size.
MADlib: Machine learning library extension for PostgreSQL.
Hadoop Ecosystem
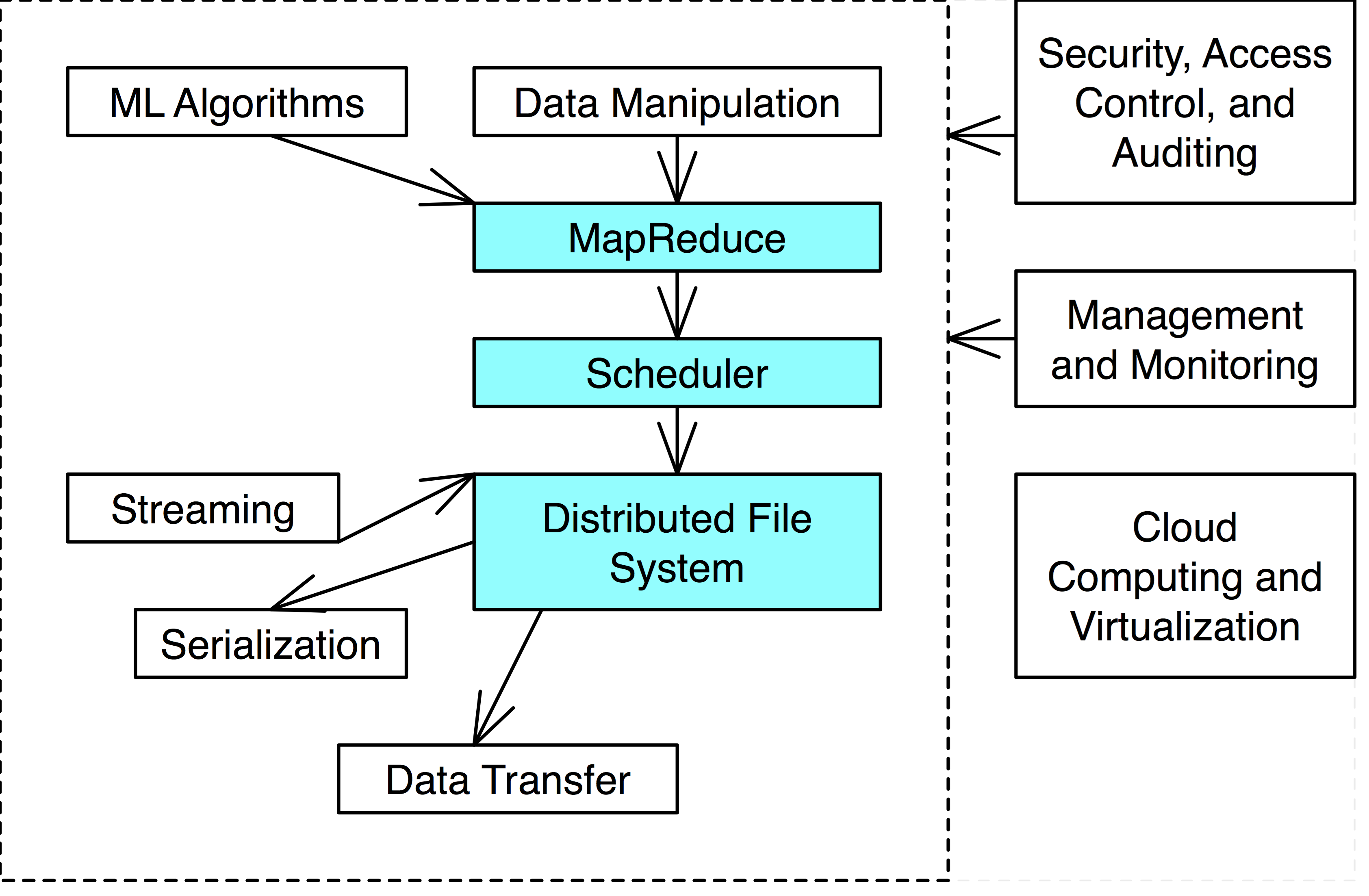
- The blue is the necessary components of a Hadoop Ecosystem
- Some tools provide several functionalities.
- i.e. Hadoop is a distributed file system with MapReduce engine and scheduler.
Distributed File System
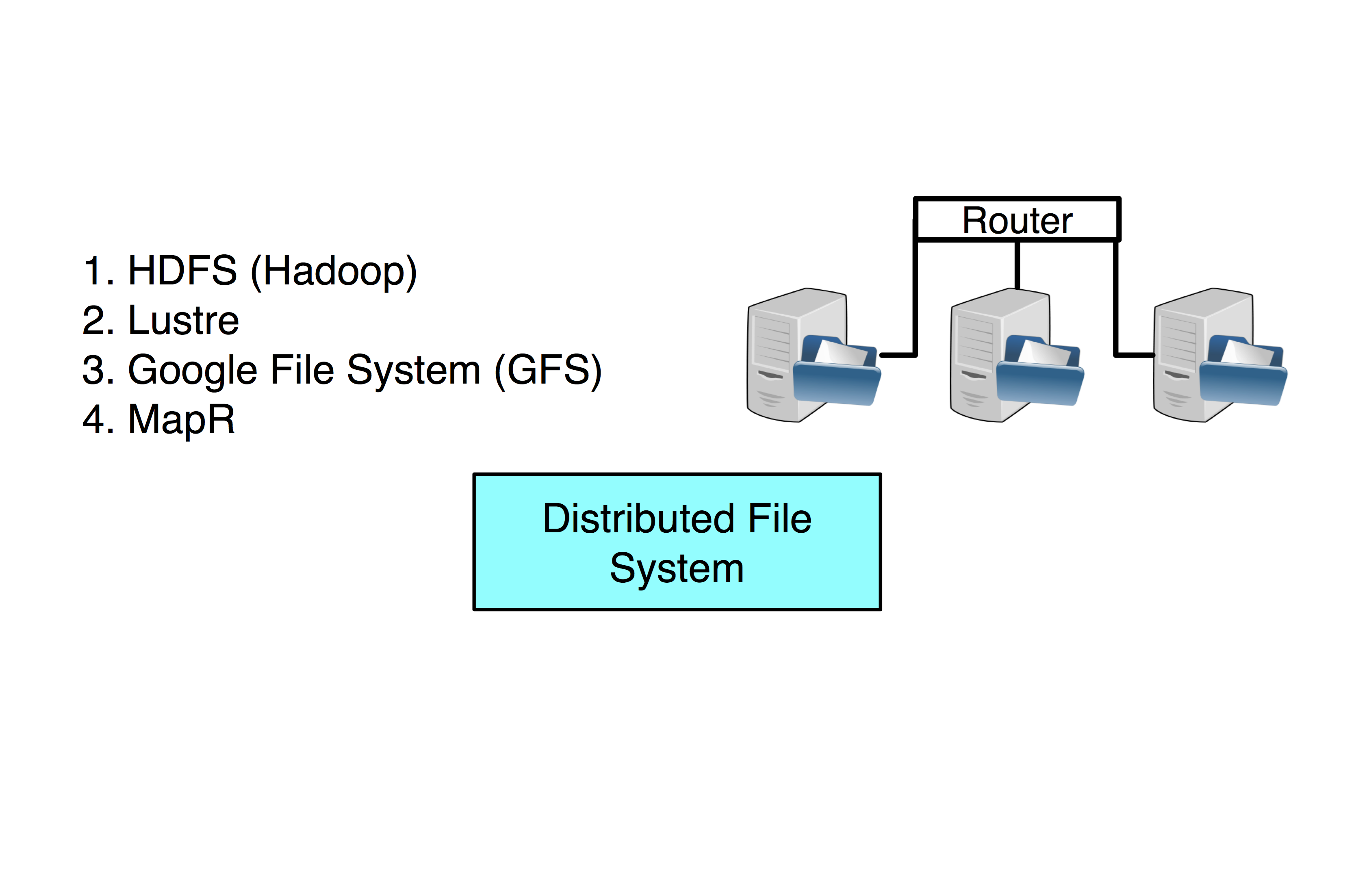
HDFS (Hadoop Distributed File System) is a distributed file-system across multiple interconnected computer systems (nodes).
- Data is stored across multiple hard drives.
Lustre: DFS used by most enterprise High Performance Clusters (HPC). Usually uses a shared networked drive.
Google File System (GFS): Google propriety distributed file system.
MapR: DFS inspired by HDFS but written in C++ instead of Java.
MapReduce
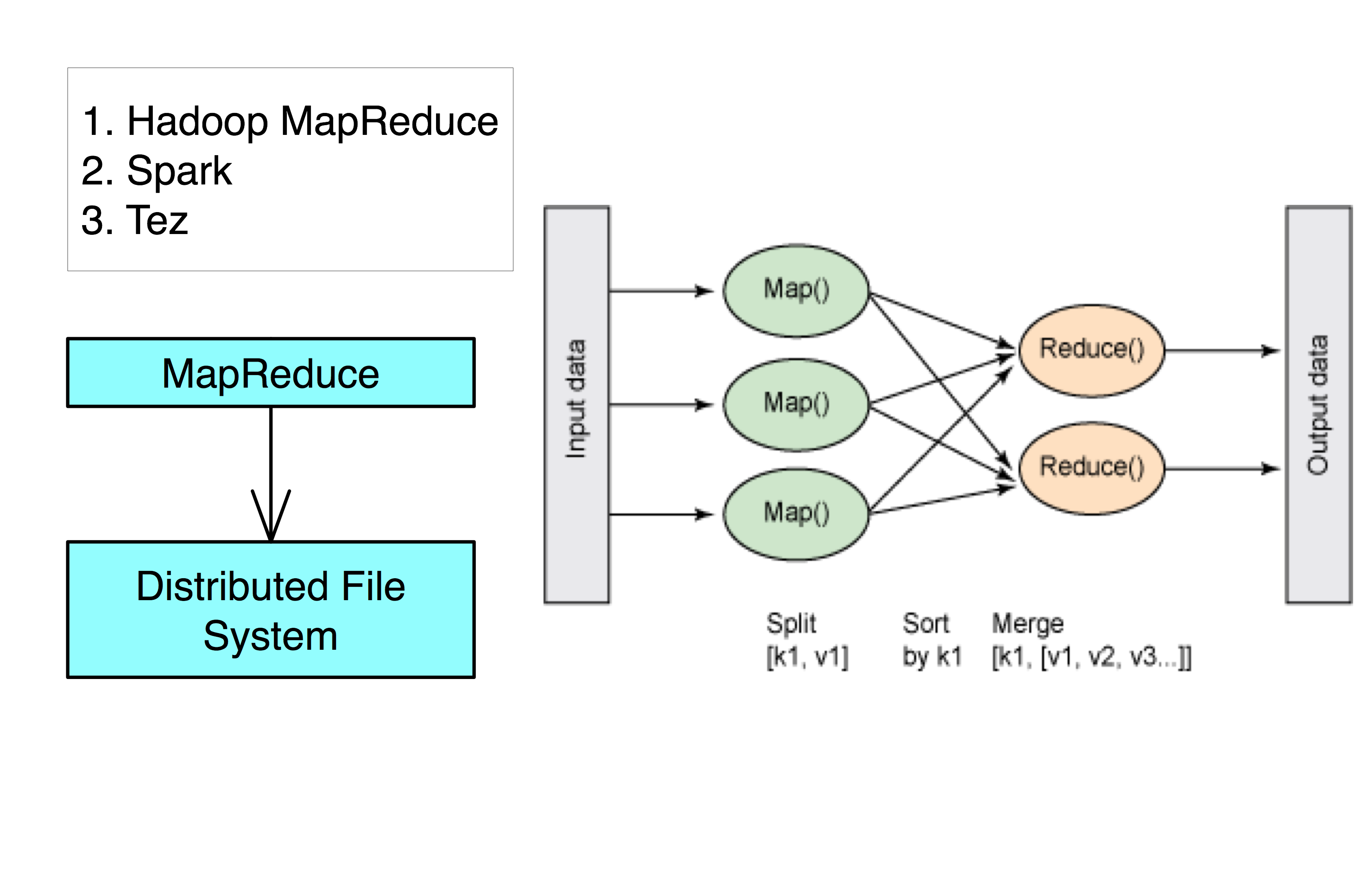
- MapReduce is the engine that processes data in a Hadoop Ecosystem.
- Spark and Tez uses a more flexiable in memory model of MapReduce which is better for Machine Learning algorithms.
Scheduler
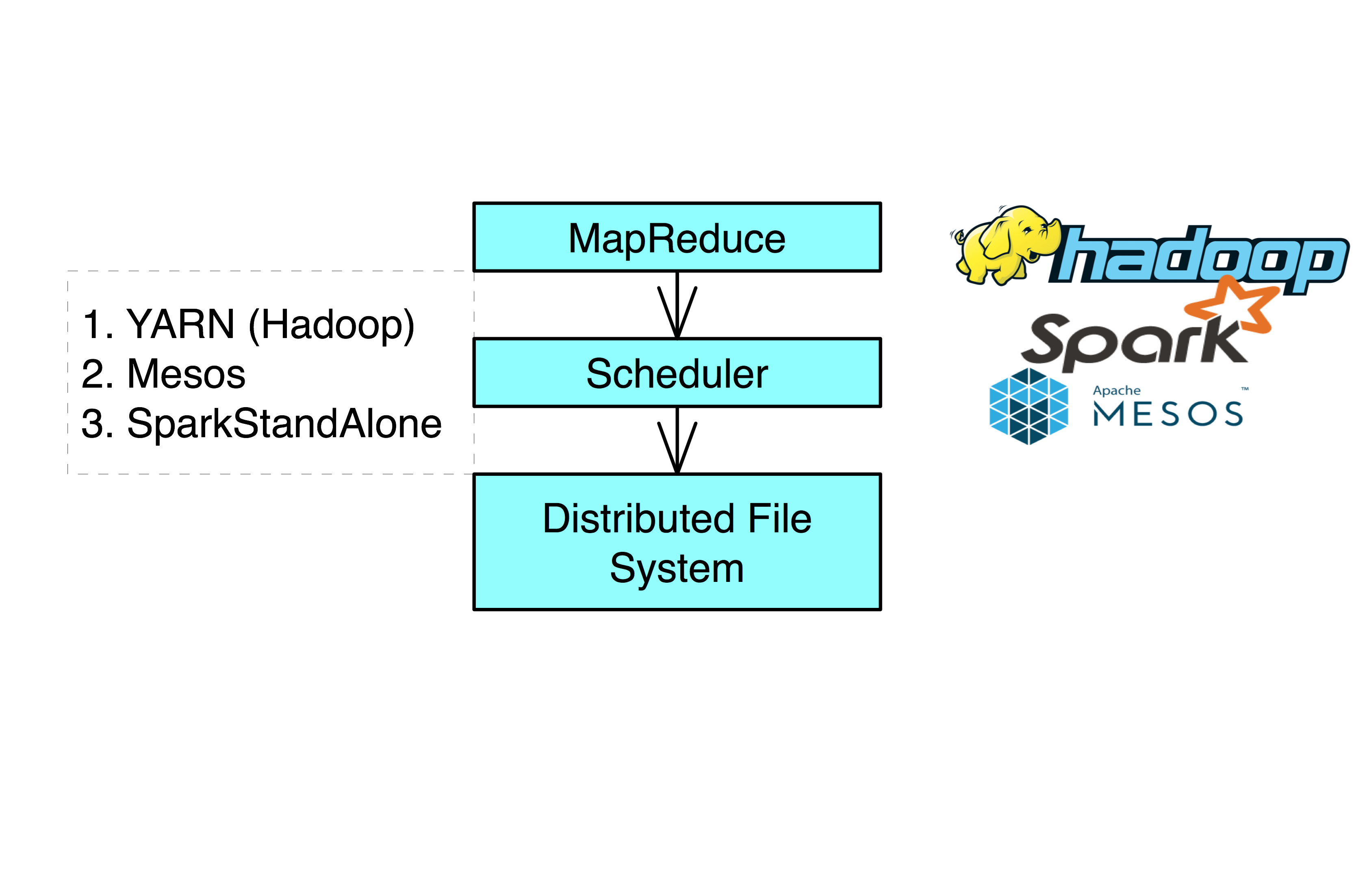
In order for multiple people to run on the same cluster, a scheduler is needed.
Data Manipulation
These are the tools to help parse, transform, and combine various datasets.
- Hive, Spark SQL, Impala, Cassandra, and HBase all use a SQL-like language to help manipulate data.
- Hive can be implemented using the Spark MapReduce Engine (significantly speeding it it’s processes).
Data Analysis
There are several Machine Learning algorithms already in place for the Hadoop Ecosystem.
- Mahout can be implemented on Spark, Tez, and Hadoop
- Spark also has GraphX, which uses graphs to perform analytics (PageRank, etc.)
There is also specialized tools:
Hadoop Image Processing Interface (HIPI): Image processing package helping to determine image similarity.
SpatialHadoop: Extension to process datasets of spatial data in Hadoop.
Serialization
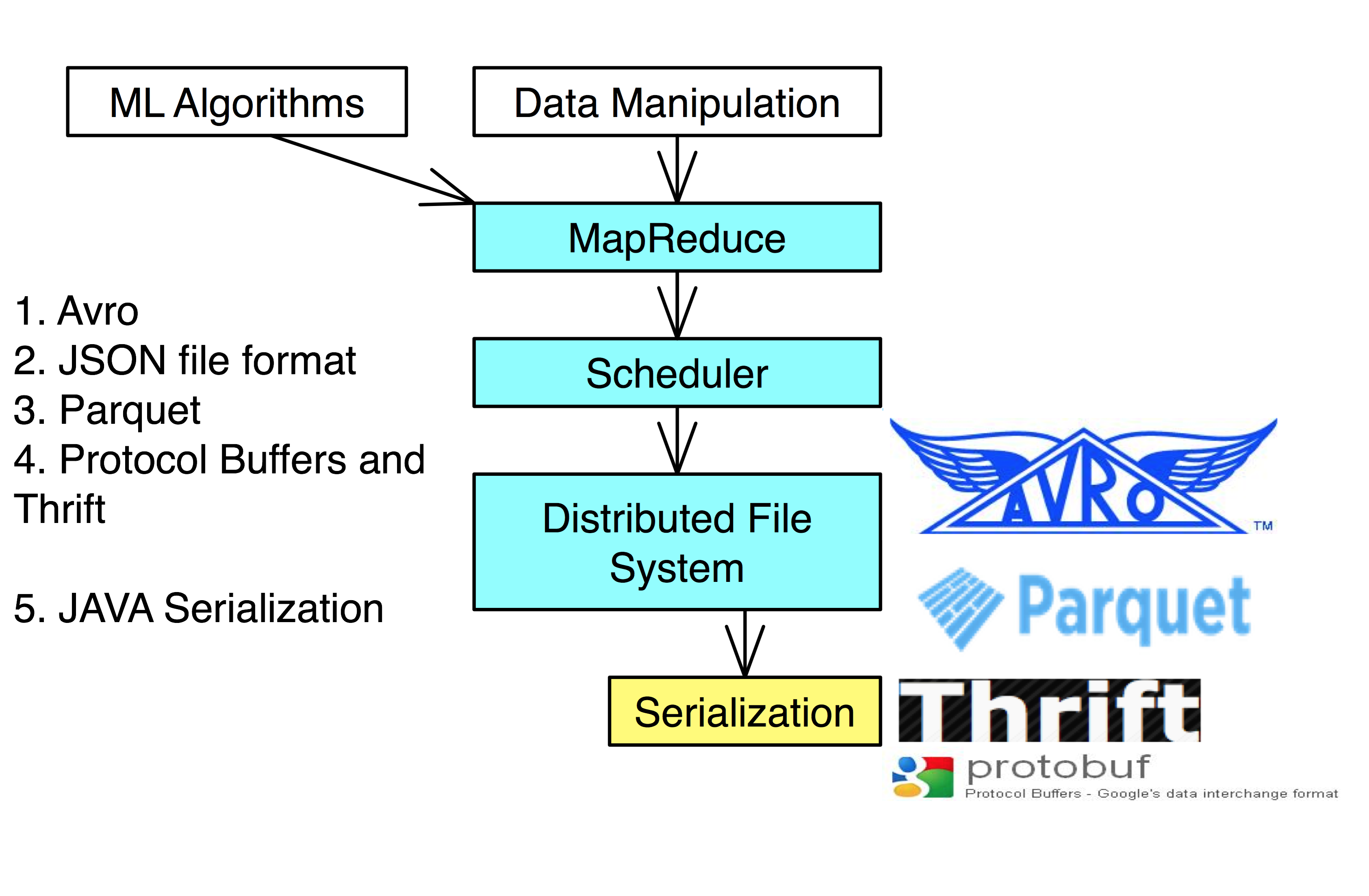
Parsing, transforming and combining the data into a useable dataset can be time consuming. Thus, once a suitable amount of work is done to create a useable dataset it is best to save it for future work.
Serialization saves the state of the data, allowing it to be recreated at a later date.
- JAVA Serialization is the worst of the above and should only be used for legacy reasons
Avro: Serialization made for Hadoop.
JSON: Java Script Object Notation is a convenient way of describing, serializing, and transferring data.
Protocol Buffers: More optimal serialization that requires the precise structure of the data when job is being run. Has less support for programming languages.
Parquet: A columnar data storage format, allowing it perform well for structured data with a fair amount of repetition.
Data Transfer
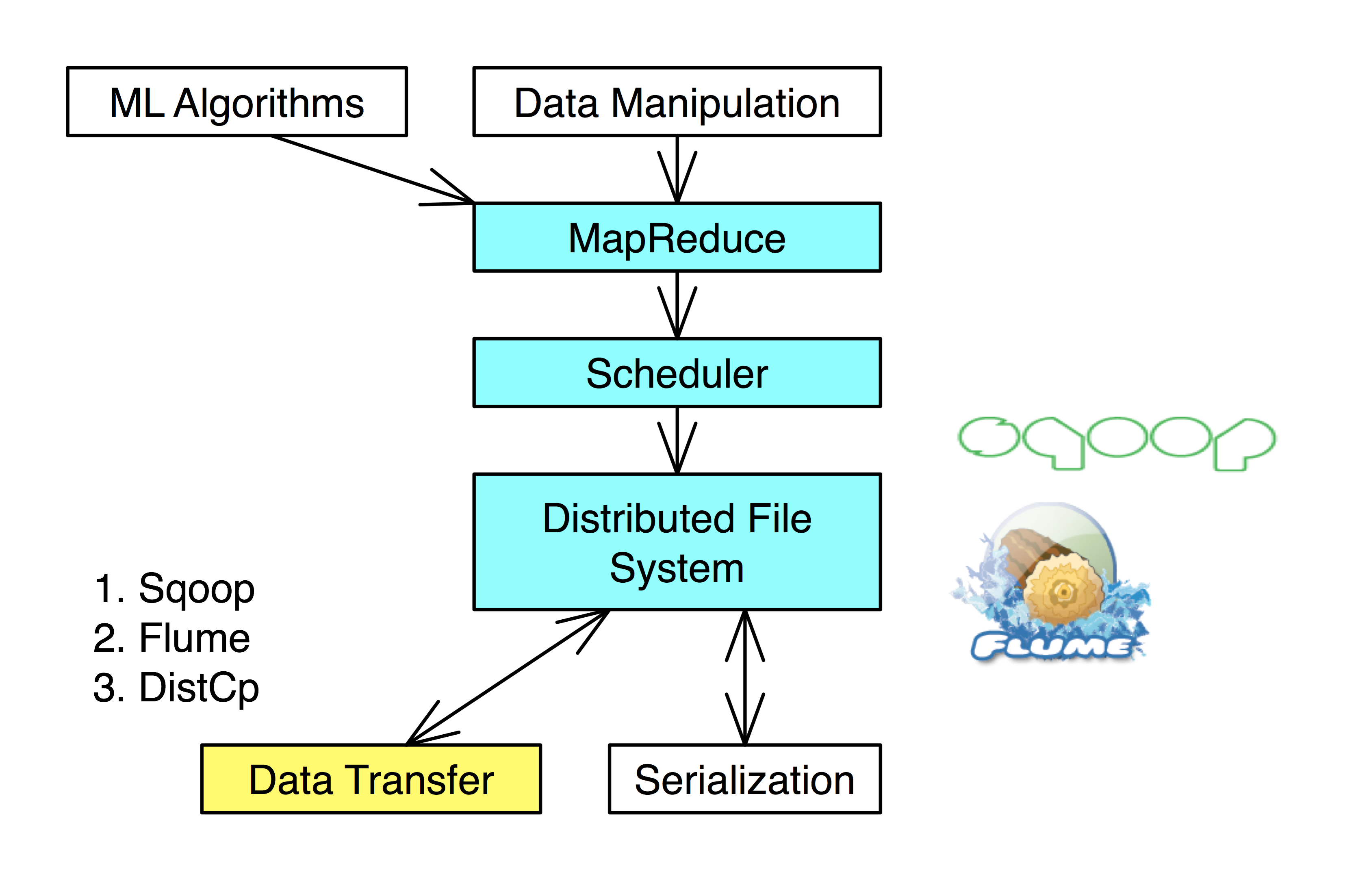
Data transfer of large amounts of data to and from dfs.
Flume, DistCp: Move files and flat text into Hadoop.
Sqoop: Move data between Hadoop and SQL.
Streaming
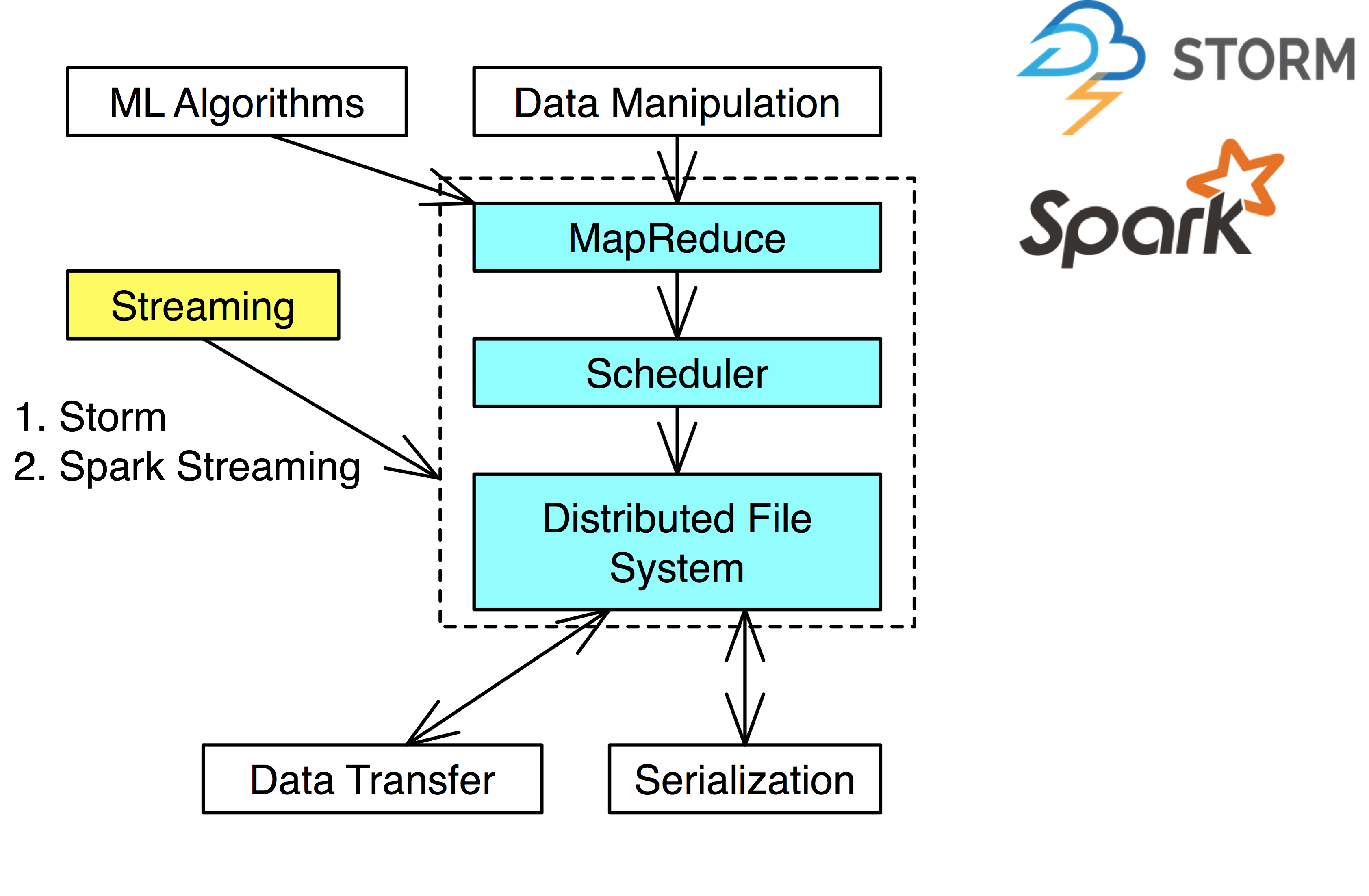
Streaming provides new calculations based on incoming data.
Example: Netflix ‘Trending Now’ feature. Possibly with personalized medicine to use medical devices to detect heart attacks before they happen.
Spark Streaming: Uses a micro-batch model that checks updates every 0.5-10 seconds and updates it’s model.
Storm: Uses either streaming or micro-batch updates to update model.
Management and Monitoring
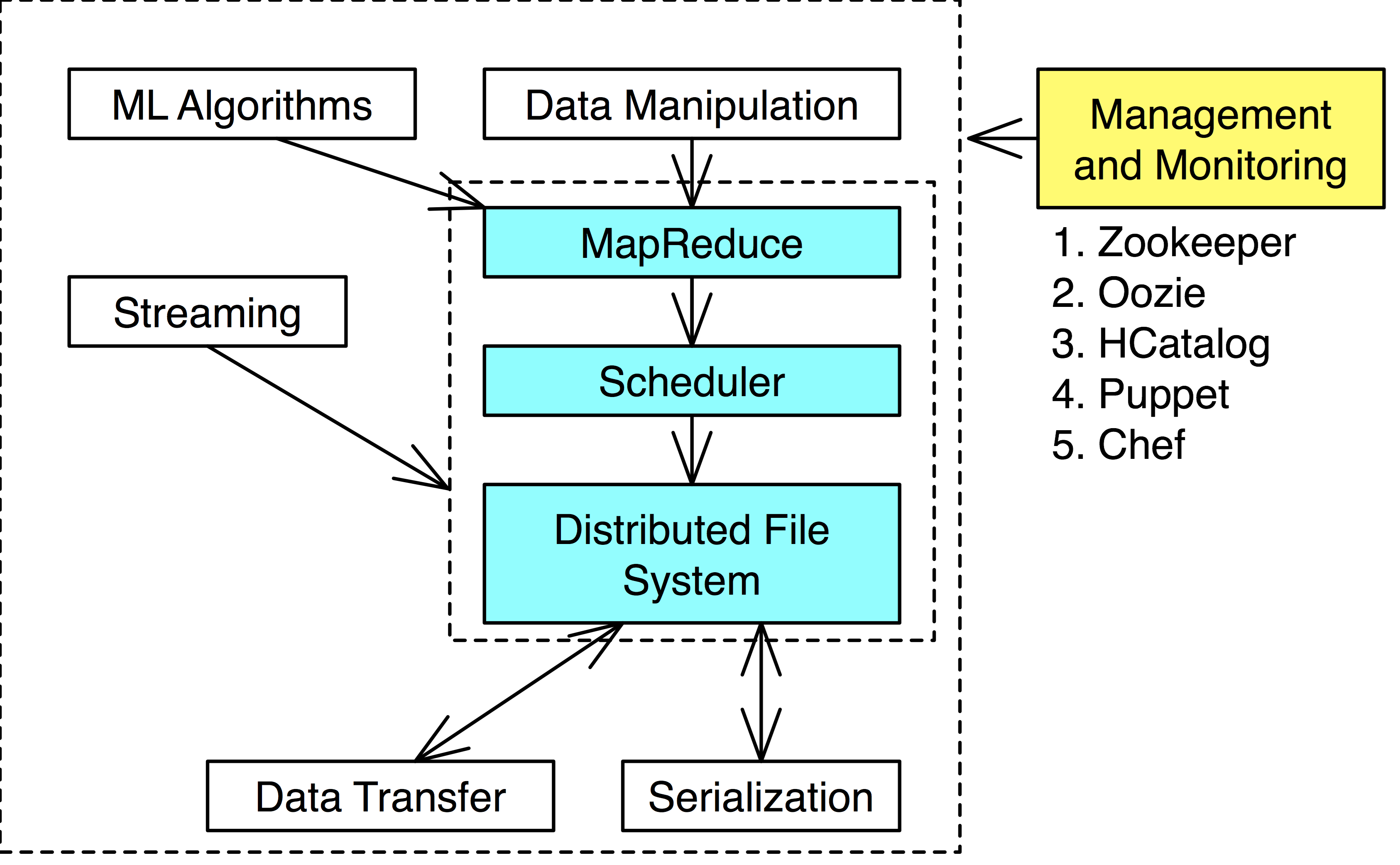
Node configuration management: Puppet, Chef. Change operating system parameters and install software.
Resource Tracking: Monitor the performance of many tools.
Coordination: Helps synchronize many tools in a single application: Zookeeper.
Ambari: Tool to help install, starting, stopping, and reconfiguring Hadoop cluster.
HCatalog: Central catalog of file formats and locations of data. Data looks like a table-like to user.
Nagios: Alert failures and problems through a graphical interface and alert administration though email of problems.
Puppet, Chef: Manager for configuration of a large number of machines.
Zookeeper: Helps coordination of tools.
Oozie: Workflow scheduler to start, stop, suspend and restart jobs, controlling the workflow so that no task is performed before it is ready.
Ganglia: Visualize how systems are being used and keeping track of general health of cluster.
Security, Access Control, and Auditing
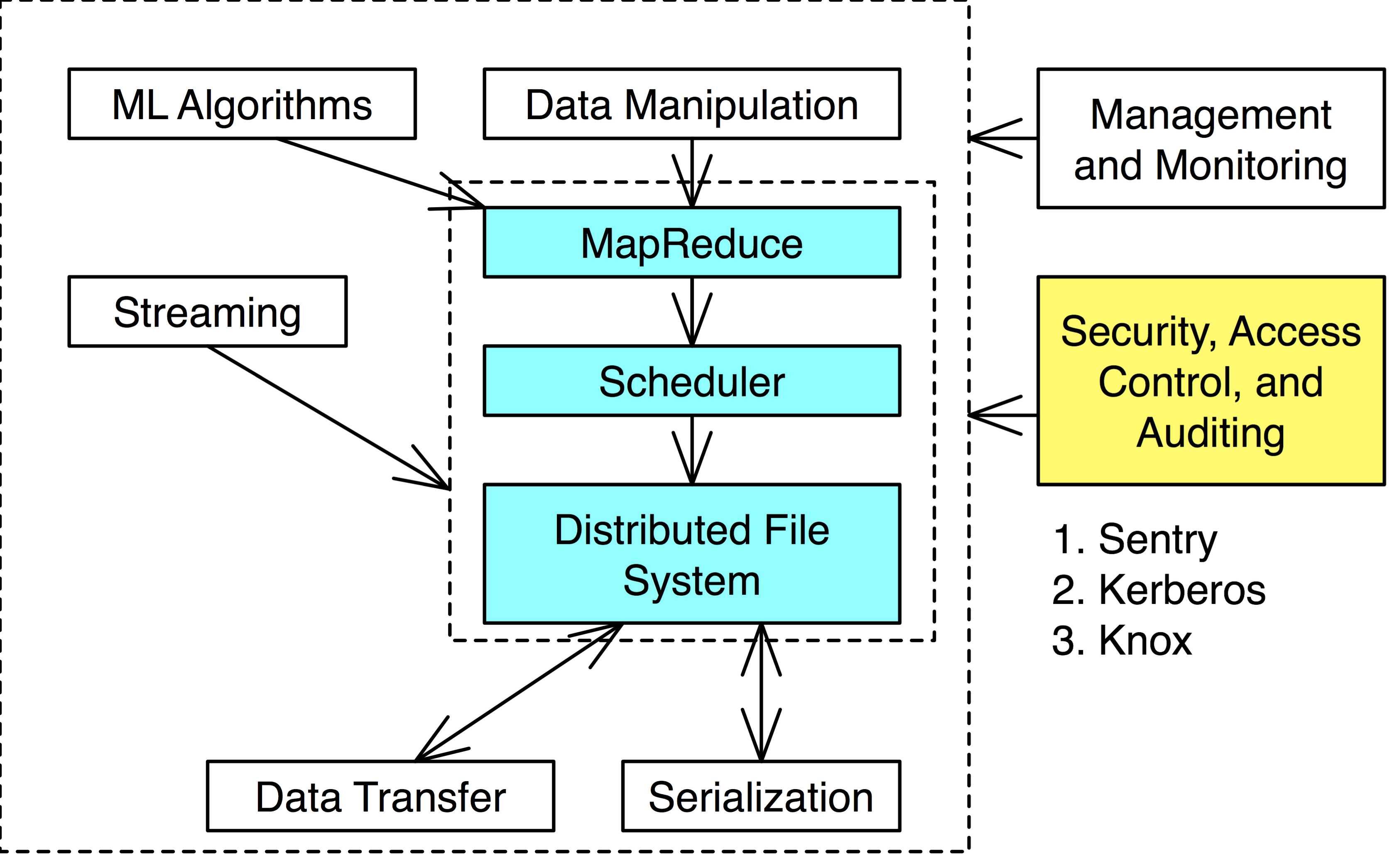
Hadoop in itself doesn’t provide much security. As Hadoop increased in popularity, so has security projects.
Kerberos, Sentry, Knox are such projects.
Cloud Computing and Virtualization
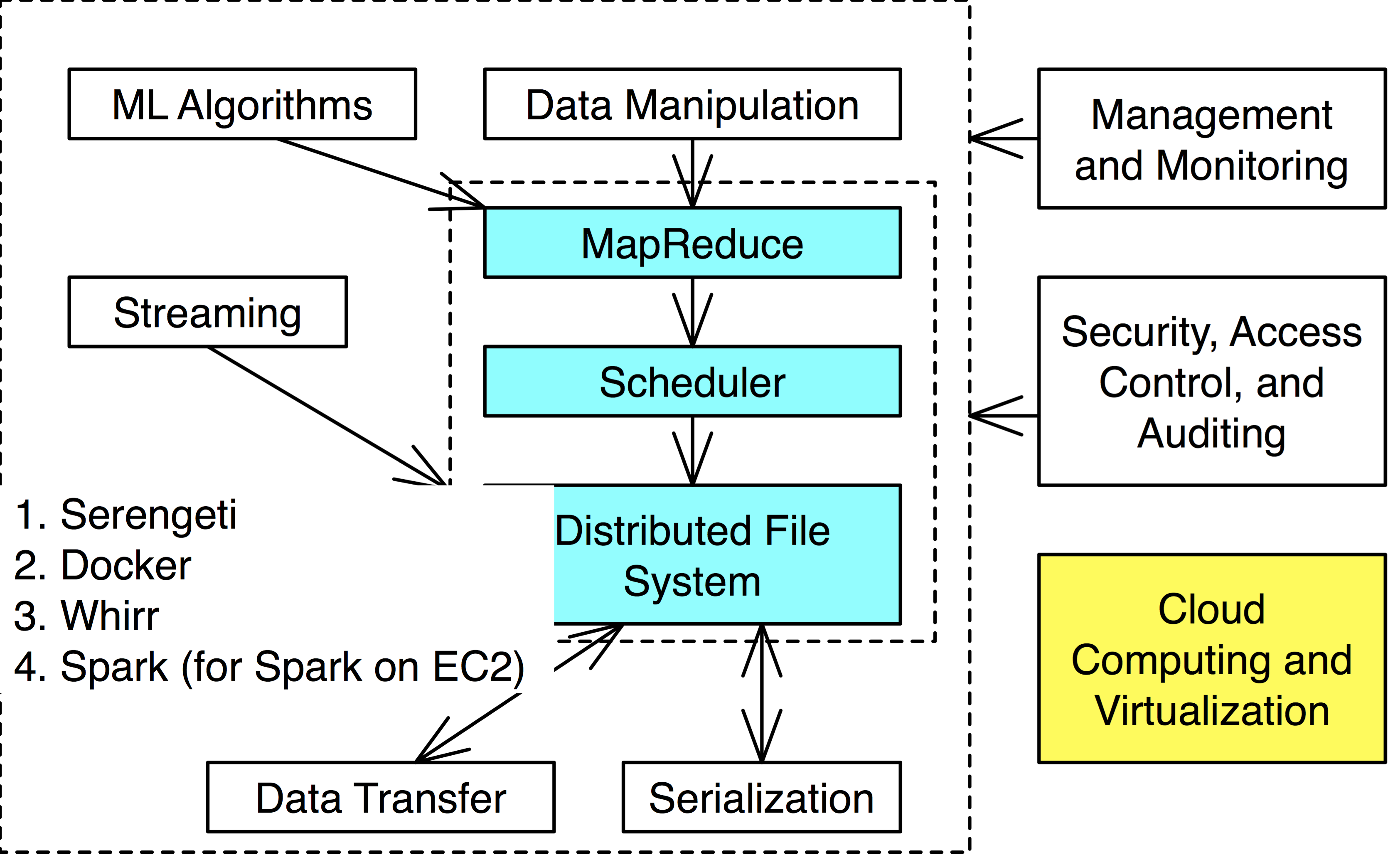
Sometimes you only need intermediate use of a cluster and creating/maintaining one of your own is prohibitively expensive.
Cloud computing and virtualization tools provide easy construction of Hadoop environments with relative ease on cloud computering environments like AWS.
Distribution Platforms
Distribution platforms help (for a cost) easy installation and software maintaince of a Hadoop cluster.
- Tool versions are checked for compatability, usually meaning that they are not the newest versions
Some of these are: Cloudera, MapR, and Hortonworks.
Next Steps: Data Science Framework
Now that you have been introduced to the tools, start on the next module and learn the data science framework.
-
Recommendation
Content coming soon!
Content based Filtering
Colaborative Filtering
-
Naive Bayes Classifier
The Bayesian approach offers an alternative method to statistics, and is actually quite intuitive once you wrap your head around it. Statistics can be daunting, but I will attempt to explain Bayes theorem intuitively and leave the mathematical proofs for textbooks.
The foundation for the Bayesian approach is Bayes theorem. I recommend you read this primer on an intuitive (and short) explanation of Bayes’ theroem and understanding bayes’ theorem with ratios.
Bayes’ Theorem
Let’s say we have event A and event B. We are trying to determine the probability of event A when B is observed.
The idea is that the probability of event B times the probability of B when A is observed is equal to the probability of A times the probability of B when A is observed. In equation:
Now, we are usually concerned with the probability of event A when event B is observed P(A|B). If we rearrange the equation above we get:
In words:
Probability of event A when event B is observed is equal to the product of the probability of event B when event A is observed and the product of event A all divided by the probability of event B
Terminology: P(A|B): posterior probability P(A): prior probability P(B|A): likelihood P(B): Predictor prior probability
Now lets look at an example of a statistics problem, and see if we can apply Bayes theorem.
Dishonest Casino Problem: Identifying a loaded dice
Question 1: Rolling 3 numbers in a row
A dishonest casino has a 99% fair dice and 1% loaded dice, where:
fair dice: P (1) = P (2) = P (3) = P (4) = P(5) = P(6) = 1/6
loaded dice: P (1) = 0.1, P(2) = 0.1, P(3) = 0.1, P(4) = 0.1, P(5) = 0.1
P(6) = 0.5 = 1/2We are asked to find the probability of the dice being loaded given the number 6 was rolled three times consecutivly. In equation form:
P(loaded dice | rolling 6 three consecutive times)
First to save typing, lets just use 666 as the notation for rolling 6 three consecutive times: p(loaded | 666) = P(dice | rolling 6 three consecutive times) In the same way I use the following notation (to save typing): p(rolling 6 once) = p(6)
Now lets apply Bayes theorem: P(A|B) = P(B | A) P(A) / P(B)
Now lets break each part of the equation down.
We know right away that: P(loaded) = 1/100 P(fair) = 99/100 This is because a dishonest casino has a 99% fair dice and 1% loaded dice.
We also know what rolling a dice is independent of each other (see the gamblers fallacy). For this reason:
We know from the question that:
P(6 | loaded) = 0.5
therefore :
Now we lets calculate the probability of rolling 6 three times. We know that either the dice is loaded or not loaded. This means that the probability is disjointedor we have to take the weighted sum of rolling 666 for loaded and not loaded. This means it will be the probability of rolling 666 for a loaded dice times the probability the dice is loaded plus the probability of rolling 666 for a loaded dice plus times the probability the dice is fair. In equation form:
Now lets sub all of this back into bayes theorem equation:
The answer to the question is that we believe that there is a 21% probability that the dice is loaded based on the observation of rolling 6 three times consecutively. Our prior belief (based on the information in the question) was that there is a 1% chance the dice was loaded, and our new posterior belief is that there is a 21% chance the dice was loaded.
Question 2: Rolling 6 only once
Now what if you only rolled the dice once and got a 6. What is the posterior probability of the dice being loaded?
Naive Bayes Classifier
Now let us generalize bayes theorem so it can be used to solve classification problems. The key “naive” assumption here is that independent for bayes theorem to be true. The question we are asking is the following: What is the probability of value of a class variable (C) given the values of specific feature variables (). Again we are going to assume that the specific feature variables are independent of each other (which is sometimes not true!).
Income tax example
For example, lets build a classifier to determine the likelihood if someone is cheating on their income tax. In this example we are trying to determine a class (Yes or No for cheating) given a set for features (got refund, and marital status). In this case, the feature for got refund is yes (y) or no (n) and for martial status is divorced (d), married (m) and single (s).
Here is the data we are given:
Refund marital status cheat y s n n m n n s n y m n n d y n m n y d n n s y n m n n s y Now lets say we are asked to look at an example where refund = no and and marital status (M.S.) = single. Using naive bayes (given the naive assumption that getting a refund and MS are independent) determine the probability what the person cheated on their taxes:
By independance:
Now by counting the data provided:
Based on the data, our assumptions of independence, we predict that with 7/11 (63.63%) probability the person cheated on their taxes. The posterior probability is 7/11 compared to the 3/10 (33.33%) prior probability.
Numerical Predictors
Naive Bayes can also work with numerical features, but they must first be transformed into categorical values. One option is to use binning described in Preparing Data and the other option (and common practice) is to assume a (usually normal) distribution and probability density function based on the mean ()and standard deviation of the dataset. This assumption can be done by plotting a histogram of the data in addition to computing the mean and standard deviation.
The following is the equation for a normal distribution:
Where:
Example: Predict playing golf based on temperature
A typeset version of this example will be coming soon! Now you can see the example below.
# Closing thoughts ## Pros: 1. Fast and easy to predict class, and works well with multi class problems 2. Performs very well (compared to logistic regression and other algorithms) when imdependence assumption is held (you need less training data) 3. Works very well for categorical inputs ## Cons: 1. For numeric features must assume a distribution such as a Gaussian (which might not be true) 2. If a variable has a category in the test data, but not in the training data, the model will assign a "zero frequency" or zero probability. One must apply a smoothing technique such as Laplace estimation or additive smoothing (smoothing algorithms content is coming soon!) 3. Since occurances (and probabilities) can be very small (with a large number of features and observations), there can be floating-point underflow. This means the probability is so small that rounding errors will cause issues. One solution is to use a log function and convert the decimals into negative numbers (a property of logarithms) and use those 4. Performance can be very poor if assumptions are incorrect, for this reason is it not wise to use the probability (`predict_proba in python`) 5. Some expert call Naive Bayes, idiot's Bayes since in real life if it almost impossible to have a set of predictors which are completely independent ## When to use: ___Real time prediction___ of streaming data: naive bayes is simple and fast, great to use for predictions in real time with stream data __Multiclass prediction___ by definition naive bayes can work on multi-class problems since it is able to predict the probability of multiple classes __Natural Language Processing__ naive bayes is great for text classification, spam filtering, sentiment analysis since it naturally works with multi-class problem. The simplest implementation is using a bag of words approach or by splitting the text corpus in to words or n-gram and using the occurrences. Tutorial on this coming soon! Combining the three points, naive bayes is great for streaming text data such as tweets, news or email.Further reading
Naive Bayes
NaiveBayes and NLP
Nomograms for Visualizing Naive Bayes
Bayesian Statistics
Bayesian Statistics on Wikipedia
-
Decision Tree
While many decision tree algorithms exist, we will learn a decision tree construction algorithm (ID3 by J. R. Quinlan) that relies on the information-theoretic concept of entropy and information gain. Before discussing the algorithm, please fully read the background information on entropy here.
Now, on to the decision tree algorithm. Decision tree builds classification or regression models in the form of a tree structure. It breaks down the dataset into smaller and smaller subsets as the tree is incrementally developed. The final result is a tree with decision nodes and leaf nodes.
For an example, we will use the same labeled data set as in the naive Bayes classification. The two features are refund and marital status, and the class attribute (to be predicted) is cheat. The objective is to predict if someone will cheat on their income tax return based on their marital status and whether they are due a tax refund.
Here is the dataset:
Refund marital status cheat y s n n m n n s n y m n n d y n m n y d n n s y n m n n s y A decision node (e.g. refund) has two or more branches (e.g., yes or no) and the leaf node (e.g., cheat) represents a classification or decision. The topmost decision node in a tree which corresponds to the best predictor called root node. Decision trees can handle both categorical and numerical data.
The first step is to decide on the root node of the decision tree. There are as many choices as features. In our example, the root node can be refund or marital status.
Option 1:
If we choose refund at the top, there will be two edges out of this node: refund=yes and refund=no. For refund = yes, we have 3 data points, of which all three have cheat=no. For refund = no, we have 7 data points, of which four have cheat=no and 3 have cheat=yes. Now we will calculate the entropies of these two distributions (of the class variable cheat, assuming that refund = yes or no, respectively).
For refund = yes, we have a distribution of cheat where cheat=no is the only possible outcome, so the entropy is zero.
For refund = no, we have a distribution of cheat where P(cheat=no) = 4/7 and P(cheat=yes) = 3/7. The entropy = .
Finally, we compute the weighted average entropy for refund. We take the entropy for refund = yes and weigh it by the proportion of data points that have refund = yes (3 out of 10), and add the entropy for refund = no, weighted by the proportion of data points that have refund = no (7 out of 10). We get:
weighted average entropy for refund = .
Option 2:
If we choose marital status at the top, there will be three edges out of this node: marital status = single, marital status = married and marital status = divorced. For marital status = single, we have 4 data points, two of which have cheat = no and two have cheat = yes. For marital status = married, we have 4 data points, all of which have refund = no. For marital status = divorced, we have 2 data points, one with refund = no and one with refund = yes. We need to calculate the entropies of these three distributions.
For marital status = single, we get entropy = .
For marital status = married, we get zero.
For marital status = divorced, we get .
Now we compute the weighted entropy for marital status: .
Finally, we choose the option with the lowest weighted average entropy. In our example, marital status will be the root node.
The algorithm then completes the tree by choosing nodes with the lowest weighted average entropy, as above.
Information Gain
Another method for decision trees is the use of information gain or the decrease in entropy after a dataset is split on an attribute. Constructing a decision tree is all about finding attribute that returns the highest information gain. The example on this site provides an additional example of both an entropy based and information gain based decision tree.
Closing thoughts
Pros:
- Results are human interpretable: you can explain the classification rules based on the decision tree
- Variations of the algorithm can work with both categorical or numerical
- When paired with boosting and ensembling (Random forests and XGboost), decision trees are one of the most commonly used classification technique
Cons:
- Decision trees alone are very prone to overfitting as a greedy search is performed based on entropy. As such, many additional algorithms were created such as C4.5, Random Forest, XGboost
Further reading:
-
Rule Based Learning
Rule based learning is a related technique to decision trees as trees can be converted to rules and rules can be converted to trees. In this section we will learn three concepts: the 1R algorithm, the PRISM algorithm, and converting rules to trees and vice versa.
1R Algorithm
The 1R algorithm stands for One Rule and it is simply a 1-level decision tree. Why would you use only 1 rule? The answer is for simplicity and to be used as a baseline.
Pseudo-code for 1R:
For each attribute: For each value of the attribute, make a rule as follows: count how often each class appears find the most frequent class make the rule assign that class to this attribute-value Calculate the error rate of the rules Choose the rules with the smallest error rateTo see a worked example, please read the first 10 slides of Chapter 4 from Data Mining by I. Witten and E. Frank.
Prism
Prism is another rule based learning algorithm. Here is a worked example:
Trees and Rules
It is also important to understand that rule-based and tree-based classification models are similar. We can always covert a decision tree to an equivalent set of rules that make the same prediction. There will be one rule per leaf node in the tree. On the other hand, it can be harder to convert a set of if-then rules to an equivalent tree. For more details and an example, see Witten and Frank’s first 14 slides in chapter 3.
Further reading
-
Support Vector Machines
Linear models for classification
In addition to logistic regression, linear models for classification (e.g., Support Vector Machines (SVM)) are designed for problems with a binary class label and numeric feature variables. Suppose we have the following labeled dataset, with two numeric features - credit score and credit limit - and a binary class label loan, denoting whether the given customer was able to pay off his/her loan:
credit score credit limit loan 100 500 n 200 500 n 100 1000 n 400 500 y 500 500 y 300 1000 y 400 1000 y 500 1000 y Now draw a scatter plot with credit score on the x axis and credit limit on the y axis. Notice that the following line divides the points with loan=yes from those with loan=no
15/4 x + y - 1500 = 0
This is the linear model that we can use for classification. To predict the class label of a new data point, we plug in the x and y values (i.e., the credit score and credit limit) to the above equation and see if we get a value below or above zero. If below zero, then the new data point lies below the dividing line, and we predict loan=no. Otherwise, we predict loan=yes.
For example, for (x,y)=(credit score,credit limit)=(500,500), we get 15/4 * 500 + 500 - 1500= 875 > 0, so predict loan = yes. For (x,y)=(credit score,credit limit)=(100,500), we get 15/4 * 100 + 500 -1500 = -625 < 0, so predict loan = no.
An interesting question is how to select the best line that divides the two class values.
Further Reading
Support Vector Machines and Margins simplified
Support Vector Machine Full
Support Vector Machines -
Logistic Regression
Logistic regression is a popular classifier for problems where the class label is binary and the feature variables are numeric. In linear regression, we were predicting y based on the values of . The model was: . The coefficients and were computed by minimizing the residual sum of squares. Now suppose that y is a binary class label instead of a numeric variable, and the ’s are numeric feature variables. We might be tempted to fit a least-squares linear regression model, but there are several problems. For example, our predictions for y may be below zero or above one, but in the new problem, y is a binary class label whose value can only be 0 or 1. So, it would be difficult to interpret the results.
Instead, we can use logistic regression. Here, the model is: . We can interpret z as the probability that y=1. Note that z can ranges between 0 and 1.
See the following Wikipedia article for more info: Logistic Regression Logistic Regression.
Maximum Likelihood Estimation of Logistic Regression
Logistic Regression -
K Nearest Neighbor and Lazy Learning
The nearest neighbour classifier works as follows. Given a new data point whose class label is unknown, we identify the k nearest neighbours of the new data point that exist in the labeled dataset (using some distance function). We then check the class labels of these k nearest neighbours and select the most frequently occurring one (just within the k nearest neighbours, not in the entire dataset). This is the prediction for the class label of the new data point.
For example, consider the following dataset, where income is a numeric feature variable and loan is a binary class label, denoting whether a particular customer with a particular income was able to pay off his/her loan:
income loan 30 n 32 n 35 y 35 n 40 y 42 n 43 y 44 y 50 y Question: Using Euclidean distance, what prediction will 1-nn and 3-nn give for a new data point with income=39.5?
Answer: 1nn = one nearest neighbour. The closest point to 39.5 is the one with income=40 and loan=yes, so predict loan=yes. 3nn = 3 nearest neighbours. The three closest points to 39.5 are those with income=40, 42 and 43. Two of them have loan=yes, one has loan=no, so take the majority vote and predict loan=yes.
Notes about the nearest neighbour classifier: - It is often called “lazy learning”. It does not build any “model”. Instead, all the work (i.e., finding the nearest neighbours) is done at prediction time. - How to choose a good value of k for a particular dataset/application? Try several different values and compute the error rate using cross-validation.
-
Bayesian Network
-
Hidden Markov Model
Content coming soon!
-
Artificial Neural Networks
-
Model Evaluation
Model Evaluation is one of the most important parts of the model development process. The purpose is to find the best model which represents the data based on how well the chosen model will work in the future. The model evaluation involves the following concepts:
- Metrics for evaluation (this post)
- Cross Validation
- Bias vs Variance and Learning Curves
- Parameter Tuning and Grid Search
- Ensembling and combining models
- Boosting and building models on sampled data
The first concept to understand evaluation is metrics for evaluation. The idea behind a metric is a measure to determine “how good” the model is performing. In this post, we will cover the metrics for evaluation of classification, regression and clustering (in this order).
Classification
The basic visualization of the performance of an classification algorithm is the confusion matrix, also known as a contingency table or an error matrix. It shows the number of correct and incorrect predictions made by the classification model compared to the actual outcomes (target value) in the data. The matrix is NxN, where N is the number of target values (classes). Performance of such models is commonly evaluated using the data in the matrix.
The following table displays the most basic 2x2 confusion matrix for two classes (Positive and Negative) and related metrics.
Model/ Target Positive Negative Position a b Negative c d Accuracy : the proportion of the total number of predictions that were correct.
Positive Predictive Value or Precision () : the proportion of positive cases that were correctly identified.
Negative Predictive Value () : the proportion of negative cases that were correctly identified.
Sensitivity or Recall : the proportion of actual positive cases which are correctly identified.
Specificity : the proportion of actual negative cases which are correctly identified.
While this is the most basic metrics you can use for classification, I highly recommend you read the Wikipedia article on the confusion matrix and related classification metrics.
Further Reading:
-
Cross Validation
Recall that building a prediction or classification model requires a labeled data set. One might be tempted to say that performance of the model on the labeled data set (performance = accuracy/error rate or residual sum of squares) it was given is a good indication of performance on future data. However, this may not be true. A good model needs to generalize beyond the given data set to be useful for predicting/classifying future data.
One way to validate a model is to split the labeled data set into two subsets: a training data set and a testing data set. The training data set will be used to build the model. The testing data set will be used to test the model. However, it’s not clear how to dived the labeled dataset. We want as much training data as possible to build a good model, but we also want as much testing data as possible to come up with an accurate estimate of its performance.
K-fold cross-validation is a solution to the above dilemma. It randomly divides the labeled dataset into k subsets, called folds. Then, it works as follows:
- for i = 1 to k
- Build a model using all but the k-th fold
- Test the model on the k-th fold and record the error rate or residual sum of squares
- end for
- Return the average of the error rates or residual sum of squares obtained in line 3
Special case: if k=the size of the labeled dataset, we get Leave-one-out cross-validation. Every iteration of the for-loop in line 1 “leaves one data point out” for testing.
Note: ultimately, we can use the entire labeled data set to build the model. Cross-validation is only used to calculate the goodness of the model.
-
Learning Curves
Content coming soon!
-
Parameter Turning
Content coming soon!
-
Boosting
-
Ensembling
-
Regression
Regression is fitting a line or curve to do numeric prediction or to do predicted causility analysis (in some cases).
Generalized linear models
Linear regression
Fit a line to a set of data, for example think Scatter plot of Grade vs. Hours of Study
Hours of study Grade data1 data1 … … Simple linear regressoin (with one feature (or attribute)):
Input:
id x y ŷ y-ŷ p1 1 2 1 1 p2 1 1 1 0 p3 3 2 3 -1 Where x is a feature, y is the true output, ŷ is the predicted output and y-ŷ is called residual (observed - predicted)
Suppose we obtain in the following linear model:
y = xSum of the squares residuals (SSQ) =
Ordinary least squares (OLS) or linear least squares computes the least squares solution using a singular value decomposition of X. This means the algorithm attempts to minimize the sum of squares of residuals. If X is a matrix of size (n, p) this method has a cost of , assuming that . This means that for small number of features, the algorithm scales very well, but for a large number of features (p), it is more efficient (in terms of run time) to use a gradient descent approach after feature scaling. You can read more about the theory here and in more detail here
Other related metrics:
Mean Squared Error (MSE) = Root Mean Squared Error (RMSE) =In example:
SSQ = MSE = 2/5
RMSE =More complicated Example
Now let’s take a look at one of the datasets from Anscombe’s quartet. The full analysis and code to generate the figures are outlined in the simple linear regression tutorial
x y 0 10 8.04 1 8 6.95 2 13 7.58 3 9 8.81 4 11 8.33 5 14 9.96 6 6 7.24 7 4 4.26 8 12 10.84 9 7 4.82 10 5 5.68 The scatter plot looks like:
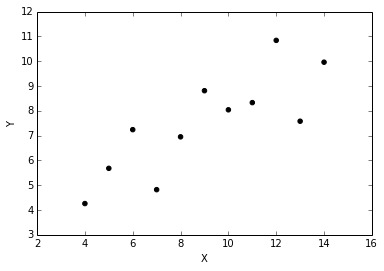
We can now use simple least squares linear regression to fit a line:
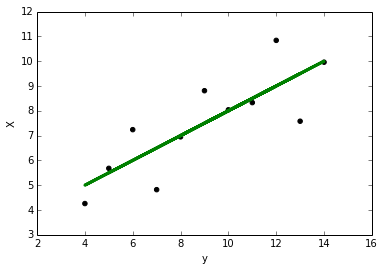
The residual (difference between y and y predicted (ŷ)) can then be calculated. The residuals looks like:
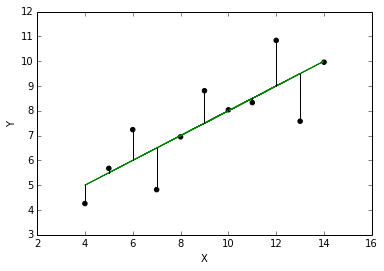
y - ŷ vs x can now be plotted:
We can now plot the residual distribution:
As seen the the histogram, the residual error should be (somewhat) normally distributed and centered around zero. This post explains why.
Vertical vs Horizontal vs Orthogonal Residuals

Usually we calculate the (vertical) residual, or the difference in the observed and predicted in the y. This is because “the use of the least squares method to calculate the best-fitting line through a two-dimensional scatter plot typically requires the user to assume that one of the variables depends on the other. (We caculate the difference in the y) However, in many cases the relationship between the two variables is more complex, and it is not valid to say that one variable is independent and the other is dependent. When analysing such data researchers should consider plotting the three regression lines that can be calculated for any two-dimensional scatter plot.
Plotting all three regression lines gives a fuller picture of the data, and comparing their slopes provides a simple graphical assessment of the correlation coefficient. Plotting the orthogonal regression line (red) provides additional information because it makes no assumptions about the dependence or independence of the variables; as such, it appears to more accurately describe the trend in the data compared to either of the ordinary least squares regression lines.” You can read the full paper here
Simple linear regression tutorial covers a complete example with all three types of regression lines.
- create residual plot for each feature and if x and y are indeed linearly related, the distribution of residuals should be normal and centered around zero
- if poor fit, consider applying a transform (such as log transform) or non-linear regression
- residual plot should not have any patterns (under/over estimation bias)
- residual plot is a great visualization of fit, but should be used in combination of other statiscal methods (see tutorial 2 and 3)
- After an initial model is created, it can be modified by doing a data transform, changing the features (called feature engineering) or model selection.
Data transforms
It linearizes the model so linear regression can be used on some non-linear relationships.
For example, if x is expoential compared to y apply log transform:
There are other methods for transforming variables to achieve linearity outlined [here](http://stattrek.com/regression/linear-transformation.aspx?Tutorial=AP:
Method Transformation(s) Regression equation Predicted value (ŷ) Standard linear regression None Exponential model Dependent variable = log(y) Quadratic model Dependent variable = sqrt(y) Reciprocal model Dependent variable = 1/y Logarithmic model Independent variable = log(x) Power model Dependent variable = log(y) Independent variable = log(x) Transforming a data set to enhance linearity is a multi-step, trial-and-error process.
- Conduct a standard regression analysis on the raw data.
- Construct a residual plot.
- If the plot pattern is random, do not transform data.
- If the plot pattern is not random, continue.
- Compute the coefficient of determination (R2).
- Choose a transformation method (see above table).
- Transform the independent variable, dependent variable, or both.
- Conduct a regression analysis, using the transformed variables.
- Compute the coefficient of determination (R2), based on the transformed variables.
- If the tranformed R2 is greater than the raw-score R2, the transformation was successful. Congratulations!
- If not, try a different transformation method.
Generalized and Non-linear regression tutorial outlines an example of linear regression after a log transformation.
Feature Transformations
- Forward Selection
Try each variable one by one and find the one the lowest sum of squares error
- not used in practice
- Backward Selection (more practical than FS)
- Try with all the variables and remove the worse one (greedy algorithm) (bad variable = highest impact on SSQ)
- Shrinkage
- LASSO: uses matrix algebra to shrink coefficient to help with eliminating variables
The techniques are used in preparing data section and are outlined in the Scikit-learn documentation
Linear and Non-linear Regression using Generalized Linear Models
Piece-wise regression, polynomial regression, ridge regression, bayesian regression and many more generalized linear models are all valid methods of applying regression depending on the application. The Scikit Learn documentation has a very good outline and examples of many different techniques and when to use them. In addition the statsmodels library in python also provides an even more powerful implemention of regression with additional statistical properties as we saw in the tutorial.
Advanced Regression Techniques
In addition, we learn later in the course about classification methods which can also be used for regression. These include decision trees, nearest neighbour, support vector regression, isotonic regression.
For now, understand that these methods exist, and by applying the principles of model selection, evaluation and parameter tuning, you can identify which algorithm and method to use.
Multi-Regression
After regression with 1 single feature, the intuition can be extended to deal with multiple features called multi-regresion In simple linear regression, a criterion variable is predicted from one predictor variable. In multiple regression, the criterion is predicted by two or more variables. The basic idea is to find a linear combination of each of the features to predict the output. The problem is to find the values of and b in the equation shown below that give the best predictions. As in the case of simple linear regression, we define the best predictions as the predictions that minimize the squared errors of prediction.

Instead of a line for one features and an output, with more than one feature, the result is a plane. Tutorial 4 covers examples of multi-regression with real world data.
Futher reading
-
Classification
Content coming soon!
-
What is Data Science?
Booz Allen Hamilton’s (BAH)Field Guide to Data Science tries to answer the question perfectly:
“Describing Data Science is like trying to describe a sunset – it should be easy, but somehow capturing the words is impossible.”
Some say a data scientist is a data analyst from Silicon Valley, others say it is a person who knows more programming than a statistician and knows more statistician than a software developer. Others have described it with a variation of the famous Venn Diagram:

Jokes aside, data science is really about actionable insights. “Data Science is the art of turning data into actions, or performing Data Science requires the extraction of timely, actionable information from diverse data sources to drive data decisions and products.” The study and the role is multi-facted and has many different meanings for different companies (or even within a company).
Data engineering vs Data science?
Udacity has a great post outlining common roles and different skills required to be a Data Scientist, summarized in the figure below:

As you can see, the role is very integrated from people who build data integration systems (sometimes called data engineering), to people doing data analytics, to people working on specific tasks in the data science framework. The latter are sometimes called hadoop monkey (who write map reduce code on demand), ETL drones (who extract transfer and load data daily but never get to do analysis) or other names of people who dislike their current position.
While this guide can be used as the foundation to learn a variety of topics, our focus is providing the background for people working at “Reasonably sized non-data companies who are data-driven” and providing links which outline the details for the difficult mathemical proofs. In this way, we hope the guide will provide the fundamentals theough a hands on approach to data science.
Fusion of Top Down/Bottom Up, Inductive/Deductive Thinking
BAH goes on to state that “Data Science supports and encourages shifting between deductive (hypothesis-based) and inductive (pattern-based) reasoning. This is a fundamental change from traditional analytic approaches. Inductive reasoning and exploratory data analysis provide a means to form or refine hypotheses and discover new analytic paths.”
The way I like to think about it is the traditional scientific approach is top down, where phenomenon is determined by scientific first principles, and then validated through experiment. In the bottom up or inductive based approach, phenomenon is determined by experimentation and then is check for intuition based on first principles. Data science is the function of both approaches by using an iterative approach to the analysis.
Causality Analysis
It is well known that Correlation does not imply causation

There even very funny spurious correlations to drive the point. Yet some argue that data science is about causality analysis and answering the question “Why?”. The only way that this can be done is harmonizing the inductive and deductive ways of thinking.
What is a “big data scientist”
First of all, the term “big data” makes many people cringe since it is become such a cliche. So much so that calling big data a cliche has also become a cliche bringing birth to the term “medium data” and the following question:
How big is big?
According to me, big data is data which it too large to fit reasonbly in an avaliable comptuer/server’s memory (RAM). If the data fits reasonbably in RAM, then I consider it “medium data”, and with mordern servers which have Gigabytes (and even Terabytes of RAM), medium data can be quite large.
Big data got it’s name due to the “4 V’s of big data”:
Volume: size of data generated. Velocity: speed of data generation Variety: different types of data Veracity: messiness or trustworthiness of the data
For this reason, there exists specialized tools which allows people to “get value” from big data. But before learning the newest released big data tool, it is easier to learn the fundamentals of data science on small-medium sized data first, then learn big data. For this reason, first part of the guide will outline the general framework and provide hands on tutorials for data analysis then go into big data, distributed systems and the the other modern paradigms.
Further reading
The wikipedia article on data science outlines the multifaceted approach including “signal processing, probability models, machine learning, statistical learning, data mining, database, data engineering, pattern recognition and learning, visualization, predictive analytics, uncertainty modeling, data warehousing, data compression, computer programming, artificial intelligence, and high performance computing.”
Now that we have an general understanding of what is Data Science is and what it involves. Next let us learn the Data Science Framework. The required background section indicates the required knowledge to be a good data scientist.
-
Preparing Data: Feature Engineering
Coming soon!
-
Data Science Framework Overview
This section outlines the steps in the data science framework and answers what is data mining. It ends with issues and important topics with data science.
Data Science is the art of turning data into actions and the overall framework is the following 7 high level steps:
Ask > Acquire > Assimilate > Analyze > Answer > Advise > Act
Asking Questions
Data science begins by asking questions, where the answers are then used to advise and act upon. A data scientist, like any good scientist, should not only have a formal mathematical background but the curiosity to ask and answer questions. Data should also be able to validate the answers to the questions and think critically if the assumptions made along the way are valid.
Acquiring and Assimilating Data
Once a series of questions are asked, a data scientist will try and acquire the required data and assimilate in a form which is usable. It is a data scientist’s role to determine which inputs or features will enable the data mining, pattern recognition and machine algorithms to work. Determining the features is a process called Feature Engineering. Once the features are determined, the data acquisition could be simple as downloading the data from an open data source or creating an collaborate framework to log or measure data. Once the data is collected, it needs to cleaned and transformed. This step usually involves dealing with missing values, incorrect values and potential outliers.
What form does data come in?
There are many different types of data and data can come in various forms. Structured data is usually in the form of discrete or categorical variables (finite set of possible values such as gender) or continuous or numeric variables which are integers or real numbers (for example temperature, salary, credit score etc.). A special case of categorical variables are boolean or binary variables which are yes/no or true/false.
We can ofter convert numeric to discrete by binning (for example hot/medium/cold for temperature). This is because some algorithms work well with categorical variables or can not handle numeric variables or we would like to purposely anonymize the data. Categorical variables can be converted numeric through encoding.
While the analysis of the data may seem to be the most important step, data collection, data cleaning and feature engineering are usually the most most expensive and difficult. Have poor data but solid modeling will not ensure good results. There is the Garbage In, Garbage Out concept in computer science and information theory that since computers operate by logical processes, will unquestioningly process unintended, even nonsensical, input data (“garbage in”) and produce undesired, often nonsensical, output (“garbage out”).
Analyzing Data
Once the data has been collected and cleaned, we are now ready to start the analysis or conduct data mining.
What is data mining?
Data mining (sometimes called knowledge discovery in data) is extracting implicit and potentially useful information from data. Dr. Saed Sayad says is best “data mining is about explaining the past and predicting the future by means of data analysis”. This is done by finding patterns and structure in data and summarizing it into useful information which can be used for decision making. It is the union of statistics, artificial intelligence & machine learning and databases.
What is not data mining?
SELECT FROM WHEREqueries, looking up a telephone number in the phone book, searching the web (information retrieval not data mining) Some can think of data mining as applied machine learning or pattern recognition. On the home page of this guide you will friend a tree or road map to the larger study of data science, this is a high level data mining road map:The outline has the links to the in depth explanation for each the topics, the rest of this section will provide a high level outline for each of the data mining topics.
What is Exploratory Data Analysis and Summary Statistics?
Summary statistics are basic measures which are used to summarize data, and exploratory data analysis (EDA) is the process of using summary statistics and visualization techniques to describe the data. Exploratory data analysis is a very important step in understanding the data before building any models or many any decisions. By understanding and representing the data, a data scientist is able to make informed decisions on how to analyze the data and validate assumptions about the data. The tutorials outline examples of why EDA is very important before building any model. The section of this guide outlines examples of all of these.
A very simple example of of exploratory data analysis is a scatter plot of the grades of a exam vs the amount of time students said they studied.
We will continue to use this example dataset (where possible) in this article to explain the basic types of analysis.
What is Association?
If you have an item-sets such a products purchased together or words in a document, you can determine which items are related (and the strength of the relation). An example is a database with supermarket transaction, a common association could be that bread is associated with butter.

Association is important as it can be used for product placement, indirectly boost the sale volume of one product by lower the price of another, and determine which products would be affect if a specific production is removed from being sold.
What is Clustering?
Clustering is a method to segment data into natural groupings. It is called an unsupervised method since the data is not labeled and the natural groups are not known. The algorithm is able to organize the data and determine clusters and cluster centers.
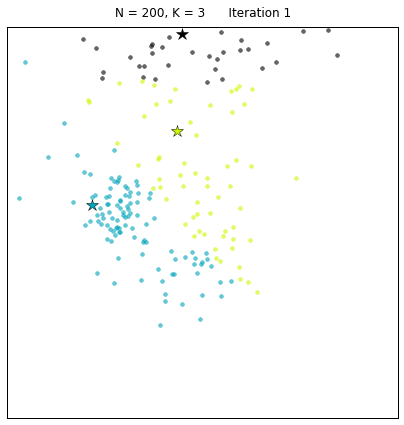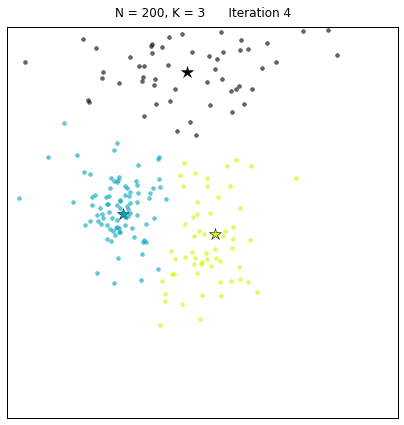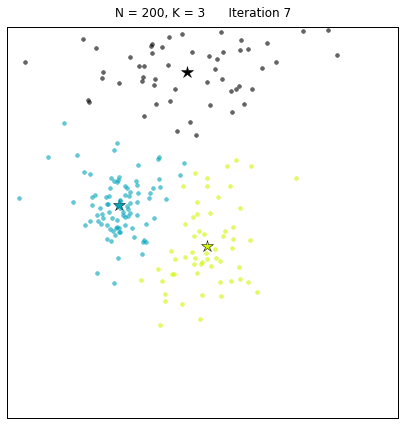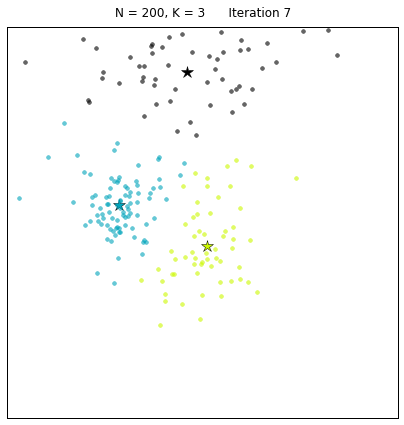 Image from here
Image from hereAn example of this clustering a class based on the grade and the hours of study. In an average class there will be students who do not study for long and get low grades (let us call them slackers), students who study for long and get high grades (let us call them keeners) and students who get high grades but do not study for long (let us call them geniuses or liars). The slackers, keeners and geniuses are show in green, red, and blue in the figure below:
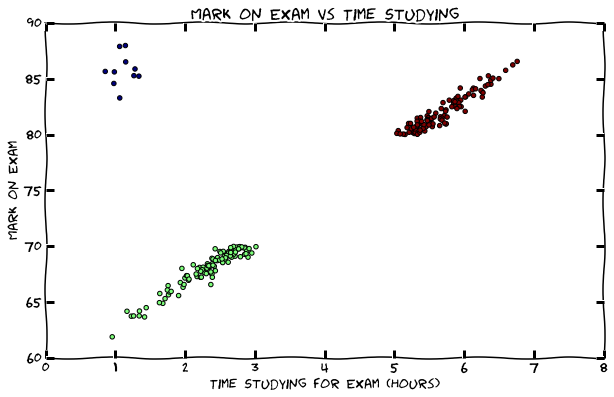
What is Regression?
Regression is fitting a line (y = mx+b) or a curve to a set of data to conduct numeric prediction. Regression can also be used to do predictive causality analysis, meaning determining the strength of the correlation of two features. Back to the example of class grades, a line can be fit against the number of hours of study and the grade. In this course, we will learn how to do robust regression and deal with the outliers as shown in the the figure below:
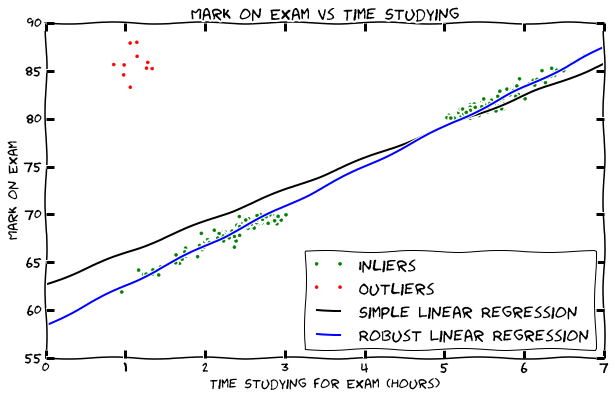
What is outlier detection?
An outlier is a data point or set of data points which deviates so much from the other observations what there is possibility that it could be generated by a different mechanism. Outlier detection are a set of methods to determine such observations. This means that it can be used to find a problem with the data (garbage) or provide an interesting observation (treasure). Back to our example of students grades, students with high grades who study very little are outliers. This could be because these students had a prior experience with the subject, could be geniuses or the real reason might be because they wrote an incorrect amount of studying or grade if a survey was used to collect the data. There are many techniques to determine outliers, but two popular methods are using clustering or using the residual error (difference of observation vs prediction) from regression as shown in the figures above.
What is Classification?
Given a set of inputs or features and a labeled discrete class variable or attribute, classification determines which class or label it belongs to for new data. This is done by determining a set of rules based on the past data. Rules can be generated using many techniques and even combination of techniques where each has their advantages and disadvantages. The model is tested by a subset of the labeled data which the algorithm has not used to generate the rules. An example of a method for classification is using a decision tree which can use information entropy to determine rules. An example of a decision tree for the marks and hours study example is the following:
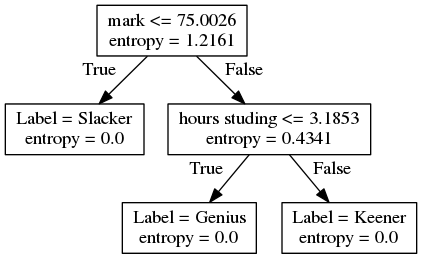
We can now predict if a person is a slacker, a keener or a genius given the grade on the exam and their hours studied. By following the tree, if we know the person has a grade less than 75% then they the would be a labeled as a Slacker. If not, and they had studied less than about 3 hours, then they are labeled as a Genius, otherwise they are labeled as a Keener.
Answering Questions with data
While the example of grade vs time studying is very intuitive and simple, examples with real data is very messy. Since there are many features (inputs) and the data has variance, it is expected that the model will have some irreducible error, and also suffer from bias and variance. Therefore after we are able to build a model with the data, we need to evaluate if the model is performing well, and then tune the model, choose another model or combine model until we have the desired performance. We will be then able to answer the question with data with a proper model. We must also always remember than since data is collected, it is not always the truth and the correlations found in the data, does not always mean causation, since there are many factors involved. This whole process from the exploratory data, to modeling and evaluation (for the purposes of the course) is called data mining, and we will learn the details of all the mentioned topics in this guide.
Advise and Act
Another very important (and often forgotten) part of data science is the Advise stage. After understanding data, a data scientist will have to provide actionable advise. This is done through optimization, simulation, project economics, and decision making under uncertainty. The guide will focus on data mining for now, but the Advise section will come soon!
Now that we understand the overall data science framework, we can move onto learn about feature engineering.
Further Reading
-
Deep Learning
More content coming soon!
What is deep learning?
In short, most machine learning deals with manually determining features (see featuring engineering)based on the datascientists understanding of the dataset. For better generalized artifical intelligence, the algorithms need to be less dependant on manual feature engienering, rather be able to determine features on their own explanatory factors.
Before diving deeply onto the topics of deep learning, it is recommended to understand how the general alogorithms work first which will give you a stronger understanding once you are dealing with unstructured data (which deep learning works best on).
Since many of the deep learning topics are subjects on their own, we will outline the common applications here, and thoughout the guide have special sections for each topic.
Natural Language Processing
Text mining
Audio classification
Sentiment Analysis
Computer Vision
Image Classification
Bioinformatics
Further reading:
-
Graph Mining
-
Clustering
Clustering
The goal of clustering is to segment the dataset into k parts (clusters) such that data points within the same cluster are similar to each other, but not similar to data points from other clusters. The k-means algorithm is a simple and popular clustering algorithm. As input, it requires k, the number of clusters, and a distance metric.
Say k=2, distance metric=Euclidean distance, and consider the following one-dimensional dataset: {2,4,10,12,3,20,30,11,25}.
Step 1: k-means randomly selects k records from the input dataset and assigns them to be the initial centres (means) of the clusters. Let’s say the two randomly chosen records are 3 and 4.
Step 2: go through the dataset, and for each record, compute the distance (using the provided distance function) from the record to the two cluster means. Assign the record to the cluster whose mean is closer to the record. We get:
cluster 1. initial mean = 3. Records: {2,3} cluster 2. initial mean = 4. Records: {4,10,12,20,30,11,25}
Step 3: recalculate the cluster means based on the records currently assigned to each cluster. We get 2.5 for cluster 1 and 16 for cluster 2. Go through the dataset again and repeat the above step (assign each record to the cluster whose mean is closer to the given record). We get:
cluster 1. mean = 2.5. Records: {2,4,3} cluster 2. mean = 16. Records: {10,12,20,30,11,25}
Step 4: repeat step 3. New means: 3 for cluster 1, 18 for cluster 2. Reassign the data points according to the new means:
cluster 1. mean = 3. Records: {2,4,10,3} cluster 2. mean = 18. Records: {12,20,30,11,25}
Step 5: repeat step 4. New means: 4.75 for cluster 1, 19.6 for cluster 2. Reassign the data points according to the new means:
cluster 1. mean = 4.75. Records: {2,4,10,12,3,11} cluster 2. mean = 19.6. Records: {20,30,25}
Step 6: repeat step 5. New means: 7 for cluster 1, 25 for cluster 2. Reassign the data points according to the new means:
cluster 1. mean = 7. Records: {2,4,10,12,3,11} cluster 2. mean = 25. Records: {20,30,25}
Since the clusters have not changed, stop.
Observations about the k-means algorithm: - Its goal is to minimize the sum of the squares of the distances between each data point and the corresponding cluster centre. In other words, it ensures that records placed in the same cluster are close together. - Different choices for the initial k means can lead to a different final answer.
-
Association Rule Mining
A popular application of association rules involves examining products that were bought together. Consider the following four sets of items (itemsets) bought together:
- {bread, diapers, milk}
- {beer, diapers, butter}
- {bread, beer, diapers, butter}
- {beer, butter}
Definition: Support of itemset A, denoted sup(A) or = the number of records (purchase transactions) containing A.
Definition: Let A and B be two itemsets. An association rule A->B asserts that if a transaction contains A, it is also likely to contain B.
Definition: The support of an association rule A->B is
Definition: The confidence of an association rule A->B is
For example, the support of beer->diapers is 2 and its confidence is 2/3.
In practice, we want to find association rules that have sufficiently high support (perhaps at least 1% of the dataset) and sufficiently high confidence (perhaps 90% or 95%). For examples of business insight that can be obtained from association rules, see Tan, Steinbach & Kumar, chapter 1 slides 23-25.
Since the number of possible association rules can be very large, we need an efficient algorithm. The APRIORI algorithm can efficiently find association rules with a desired support threshold, call it s, and a desired confidence threshold, call it c. It exploits the following properties:
-
Let A, B and C be three itemsets. The support of the following association rules is the same: AB->C, AC->B, BA->C, BC->A, A->BC, B->AC, C->BA. So, one way to solve the association rule mining problem is to first find all the FREQUENT ITEMSETS, i.e., those with support >= s. Then we construct possible association rules from the frequent itemsets and return those with confidence >= c
-
For any two itemsets A and B, . So, if we find that < s, we don’t have to consider any supersets of A since we already know that their support will be < s.
The APRIORI algorithm first finds frequent itemsets of size one (one item each), then uses them to build frequent itemsets of size 2, and so on. After finding the frequent itemsets. Recall the above dataset and suppose s=2 and c=95%.
Step 1: examine all itemsets of size 1 and compute their support |bread|=2, |diapers|=3, |milk|=1, |butter|=3, |beer|=3 Since |milk| < 2, from now on we never consider any itemsets with milk as a subset because we know they cannot have support >=2
Step 2: examine only those itemsets of size 2 where all of their subsets have support >= 2 |bread,diapers|=2, |bread,butter|=1, |bread,beer|=1, |diapers,butter|=2, |diapers,beer|=2, |butter,beer|=3 Note: none of these include milk From now on, never consider any itemsetes with milk, or {bread,butter} or {bread,beer} as a subset.
Step 3: examine only those itemsets of size 3 where all of their subsets have support >= 2 |diapers,butter,beer|=2 This is the only itemset of size 3 all of whose subsets have support >=2, as per the previous steps
Step 4: examine only those itemsets of size 4 where all of their subsets have support >=2 Nothing to examine since there is only one frequent itemset of size 3
Stop.
Answer: the frequent itemsets are: {bread}, {diapers}, {butter}, {beer}, {bread,diapers}, {diapers,butter}, {diapers,beer}, {butter,beer}, {diapers,butter,beer}.
Next step: construct possible association rules from the above frequent itemsets and return those which have confidence >= c
Final answer: bread->diapers, butter->beer, beer->butter, diapers,butter->beer, diapers,beer->butter
Note: association rules are not limited to itemset data. See, e.g., Frank&Whitten, chapter 4 slides 61-67
-
Hypothesis Testing
Content coming soon!
-
Deep Learning
More content coming soon!
What is deep learning?
In short, most machine learning deals with manually determining features (see featuring engineering)based on the datascientists understanding of the dataset. For better generalized artifical intelligence, the algorithms need to be less dependant on manual feature engienering, rather be able to determine features on their own explanatory factors.
Before diving deeply onto the topics of deep learning, it is recommended to understand how the general alogorithms work first which will give you a stronger understanding once you are dealing with unstructured data (which deep learning works best on).
Since many of the deep learning topics are subjects on their own, we will outline the common applications here, and thoughout the guide have special sections for each topic.
Natural Language Processing
Text mining
Audio classification
Sentiment Analysis
Computer Vision
Image Classification
Bioinformatics
Further reading:
-
Graph Mining
Content coming soon!
-
Map Reduce with Examples
MapReduce
Problem: Can’t use a single computer to process the data (take too long to process data).
Solution: Use a group of interconnected computers (processor, and memory independent).
Problem: Conventional algorithms are not designed around memory independence.
Solution: MapReduce
Definition. MapReduce is a programming paradigm model of using parallel, distributed algorithims to process or generate data sets. MapRedeuce is composed of two main functions:
Map(k,v): Filters and sorts data.
Reduce(k,v): Aggregates data according to keys (k).
MapReduce Phases
MapReduce is broken down into several steps:
- Record Reader
- Map
- Combiner (Optional)
- Partitioner
- Shuffle and Sort
- Reduce
- Output Format
Record Reader
Record Reader splits input into fixed-size pieces for each mapper.
- The key is positional information (the number of bytes from start of file) and the value is the chunk of data composing a single record.
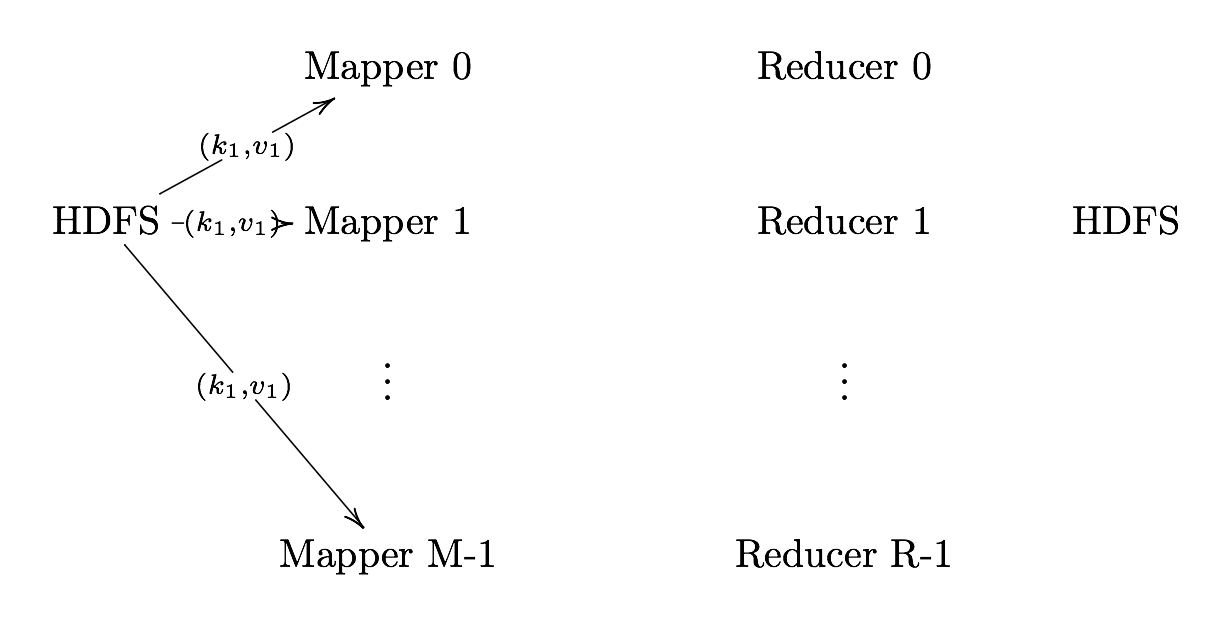
- In hadoop, each map task’s is an input split which is usually simply a HDFS block
- Hadoop tries scheduling map tasks on nodes where that block is stored (data locality)
- If a file is broken mid-record in a block, hadoop requests the additional information from the next block in the series
Map
Map User defined function outputing intermediate key-value pairs
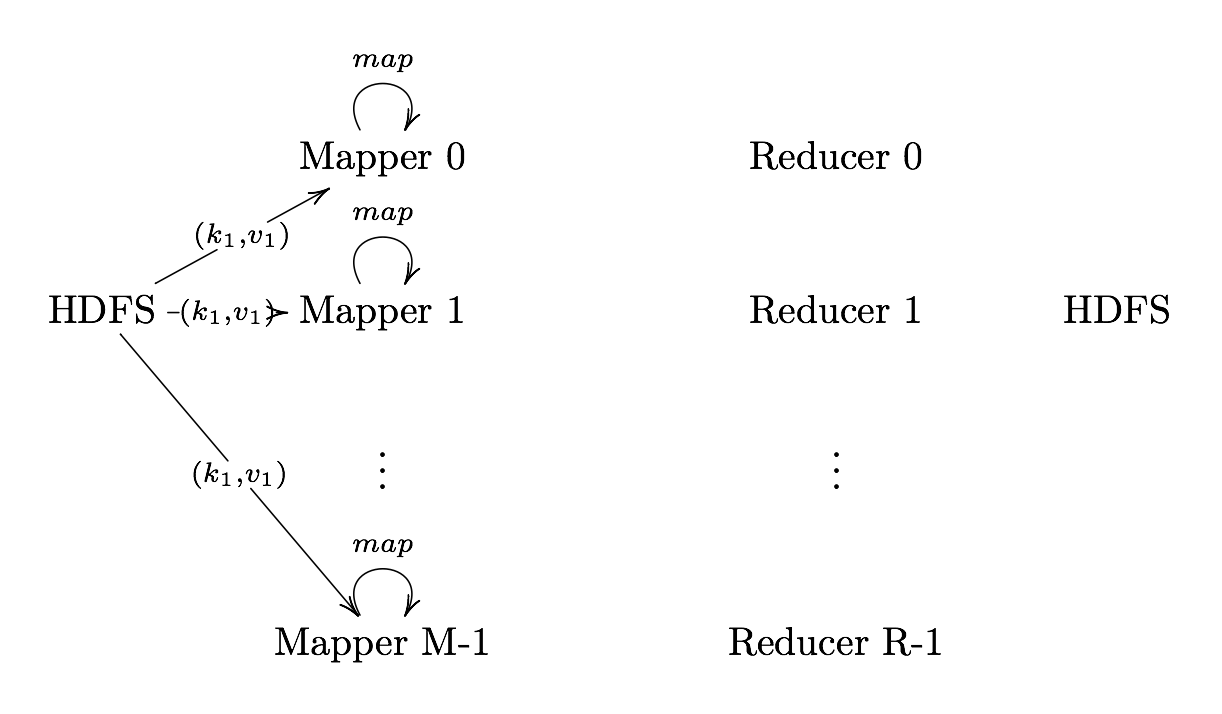
key (): Later, MapReduce will group and possibly aggregate data according to these keys, choosing the right keys is here is important for a good MapReduce job.
value (): The data to be grouped according to it’s keys.
Combiner (Optional)
Combiner UDF that aggregates data according to intermediate keys on a mapper node
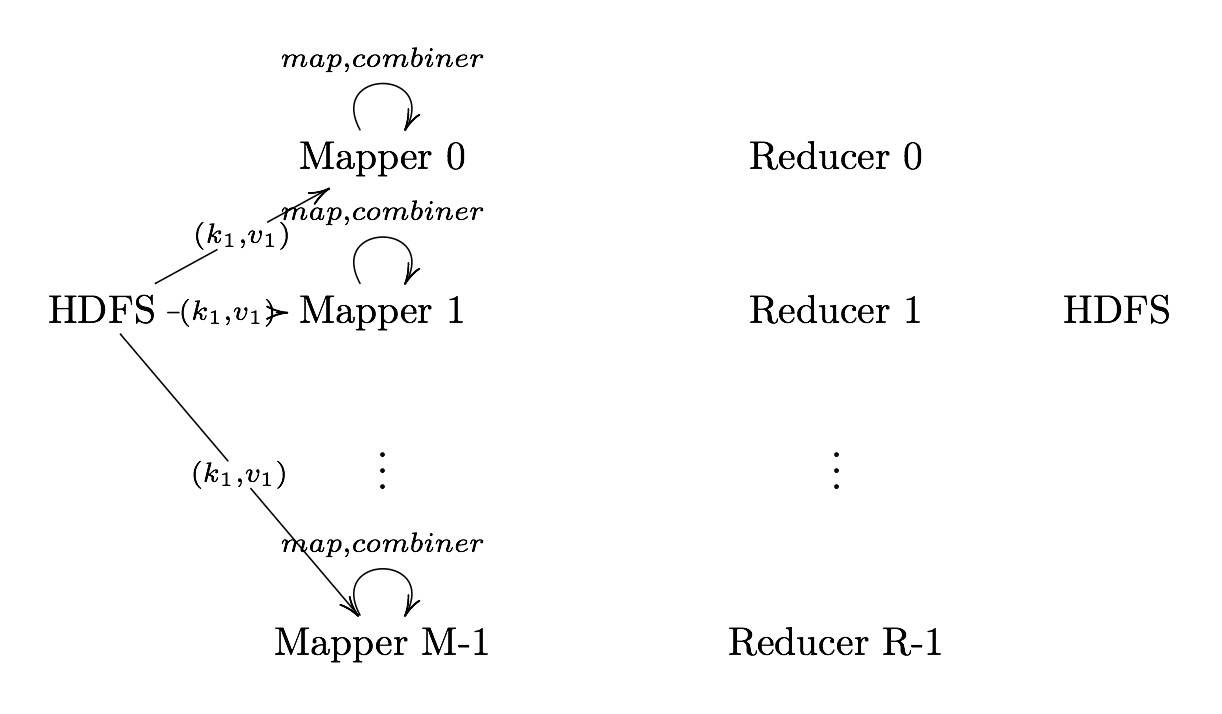
- This can usually reduce the amount of data to be sent over the network increasing efficiency
-
Combiner should be written with the idea that it is executed over most but not all map tasks. ie.
-
Usually very similar or the same code as the reduce method.
Partitioner
Partitioner Sends intermediate key-value pairs (k,v) to reducer by
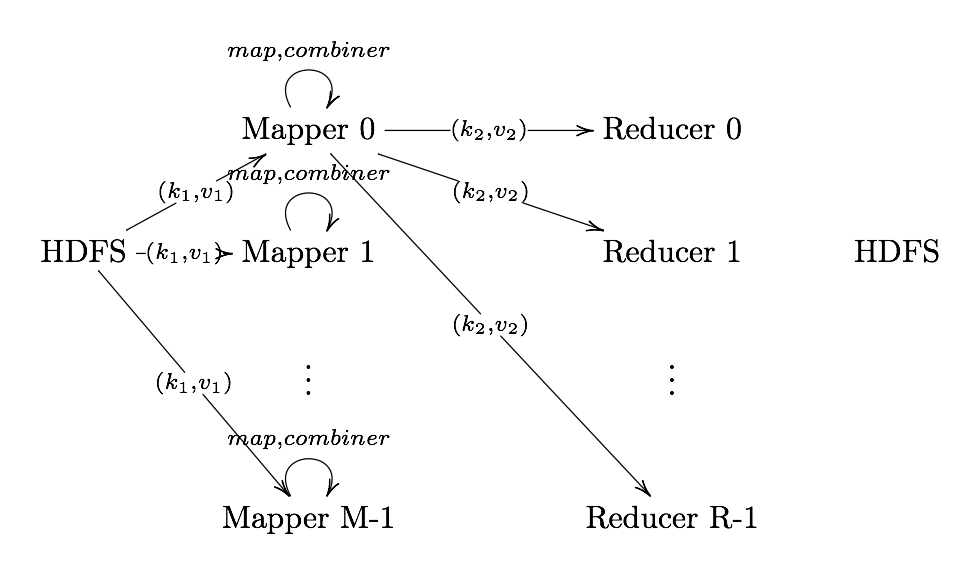
- will usually result in a roughly balanced load accross the reducers while ensuring that all key-value pairs are grouped by their key on a single reducer.
- A balancer system is in place for the cases when the key-values are too unevenly distributed.
- In hadoop, the intermediate keys () are written to the local harddrive and grouped by which reduce they will be sent to and their key.
Shuffle and Sort
Shuffle and Sort On reducer node, sorts by key to help group equivalent keys
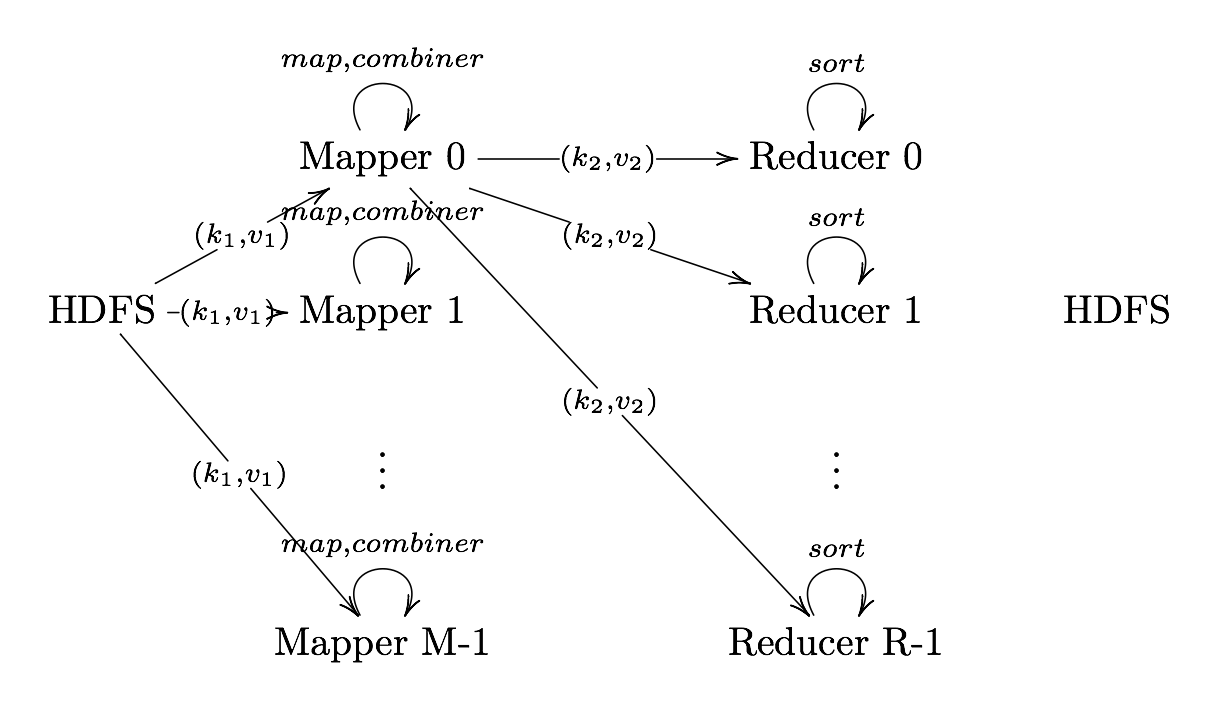
Reduce
Reduce User Defined Function that aggregates data (v) according to keys (k) to send key-value pairs to output
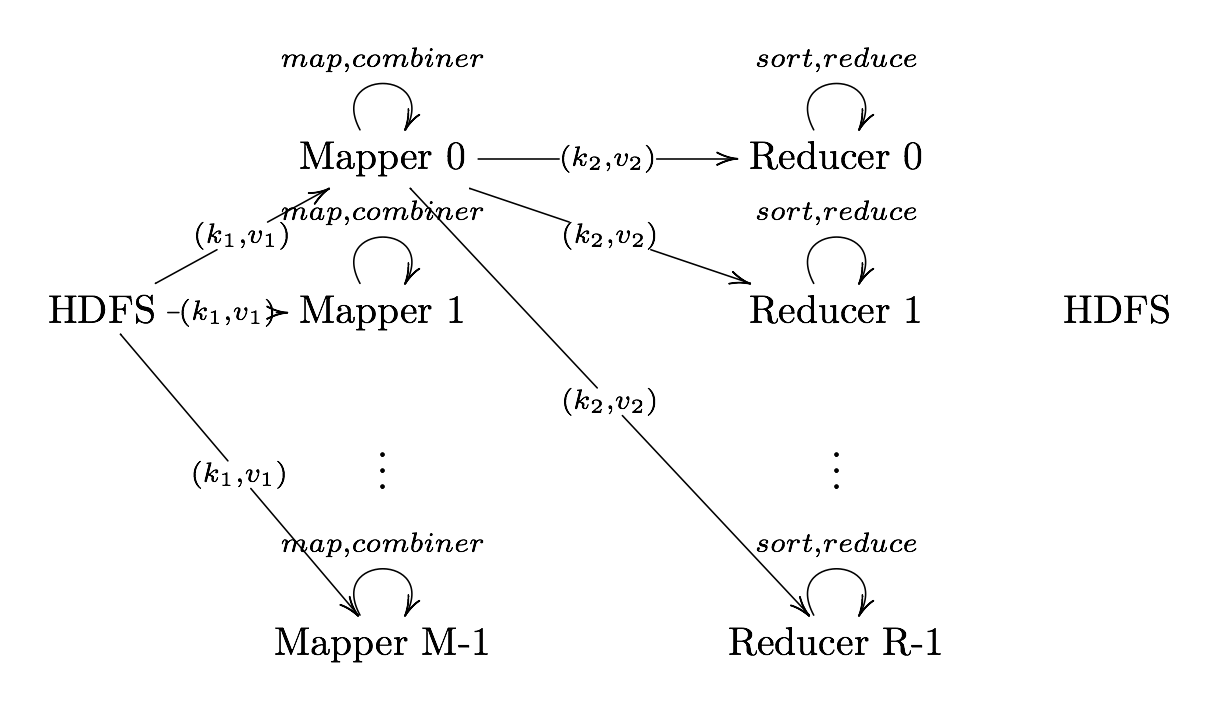
Output Format
Output Format Translates final key-value pairs to file format (tab-seperated by default).
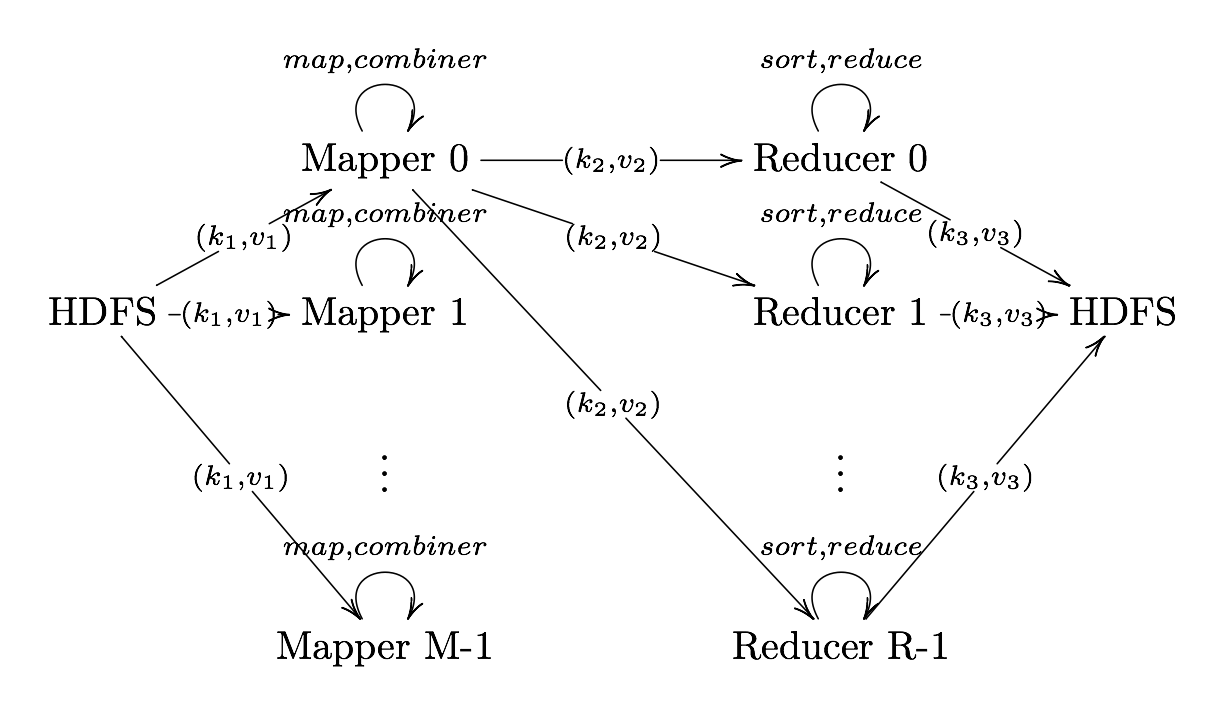
MapReduce Example: Word Count

Image Source: Xiaochong Zhang’s BlogDAG Models
A more flexible form of MapReduce is used by Spark using Directed Acyclic Graphs (DAG).
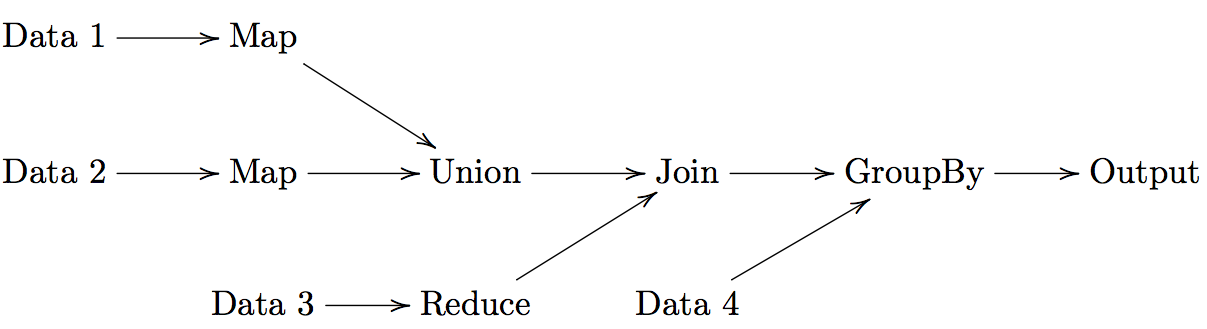
For a set of operations:
- Create a DAG for operations
- Divide DAG into tasks
- Assign tasks to nodes
MapReduce Programming Models
- Looking for parameter(s) () of a model (mean, parameters of regression, etc.)
- Partition and Model:
- Partition data,
- Apply unbiased estimator,
- Average results.
- Sketching / Sufficient Statistics:
- Partition data,
- Reduce dimensionality of data applicable to model (sufficient statistic or sketch),
- Construct model from sufficient statistic / sketch.
Partition and Model
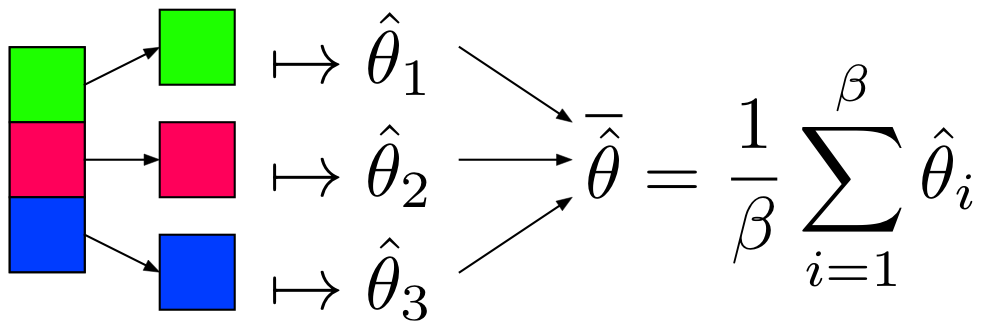
Notes
is as efficient as with the whole dataset when: 1. 2. x is IID and 3. x is equally partitioned
- Can use algorithms already in R, Python to get
- by Central Limit Theorem
Restrictions
- Values must be IID (i.e. not sorted, etc.)
- Model must produce an unbiased estimator of , denoted
Sketching / Sufficient Statistics
Streaming (Online) Algorithm: An algorithm in which the input is processed item by item. Due to limited memory and processing time, the algorithm produces a summary or “sketch” of the data.
Sufficient Statistic: A statistic with respect to a model and parameter , such that no other statistic from the sample will provide additional information.
- Sketching / Sufficient Statistics programming model aims to break down the algorithm into sketches which is then passed off into the next phase of the algorithm.
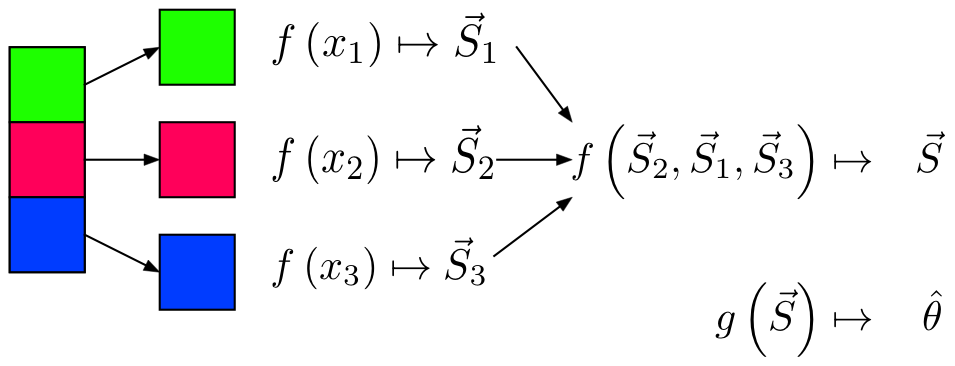
Notes
- Not all algorithms can be broken down this way.
Restrictions
- All sketches must be communicative and associative
- For each item to be processed, the order of operations must not matter
Example: Mean
Partition and Model
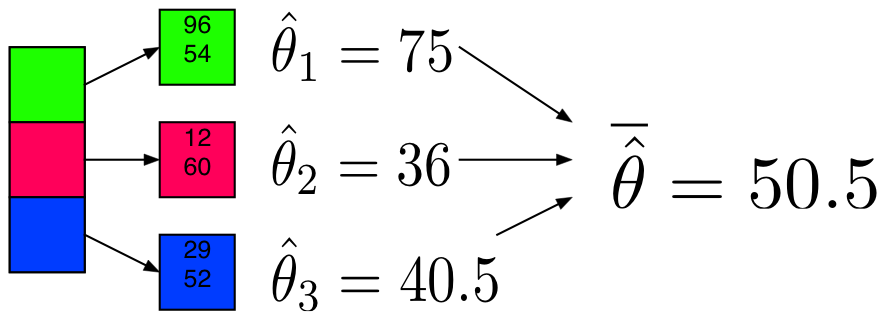
Sufficient Statistic / Sketch
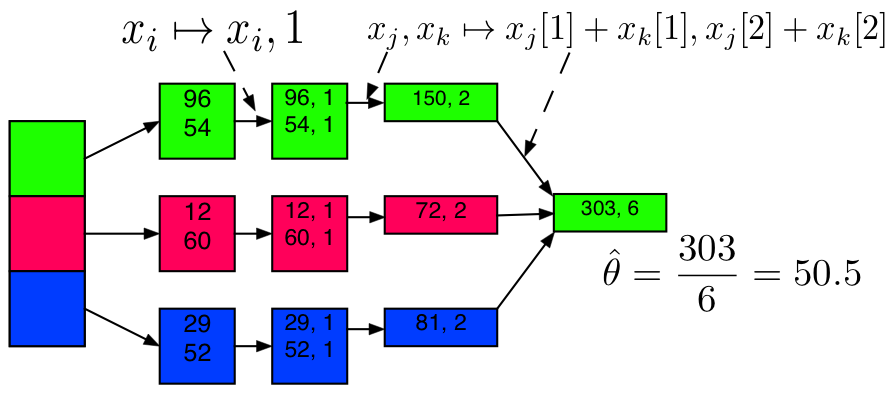
Example: Mean Code
from numpy.random import randint, chisquare import numpy as np X = sc.parallelize(randint(0, 101, 200000)) X_part = X.repartition(10).cache()Example: Mean + Partition and Model
def mean_part(interator): x = 0 n = 0 for i in interator: x+=i n+=1 avg = x / float(n) return [[avg, n]] model_mean_part = X_part.mapPartitions(mean_part) \ .collect() model_mean_part [[50.336245888157897, 19456], [50.215136718750003, 20480], [50.007421874999999, 20480], [50.135214401294498, 19776], [50.141858552631582, 19456], [50.08115748355263, 19456], [50.2578125, 20480], [50.243945312500003, 20480], [49.786543996710527, 19456], [50.072363281249999, 20480]]Example: Mean + Partition and Model
The partitions are not equally sized, thus we’ll use a weighted average.
def (theta): total = 0 weighted_avg = 0 for i in xrange(len(theta)): weighted_avg += theta[i][0] * theta[i][1] total+= theta[i][1] theta_bar = weighted_avg / total return theta_bar print("Mean via Partition and Model:") weighted_avg(model_mean_part) Mean via Partition and Model: 50.128590000000003Example: Mean + Sufficient Statistics / Sketching
sketch_mean = X_part.map(lambda num: (num, 1)) \ .reduce(lambda x, y: (x[0]+y[0], x[1]+y[1]) ) x_bar_sketch = sketch_mean[0] / float(sketch_mean[1]) print("Mean via Sketching:") x_bar_sketch Mean via Sketching: 50.128590000000003Example: Variance
Example: Variance + Partition and Model
def var_part(interator): x = 0 x2 = 0 n = 0 for i in interator: x += i x2 += i **2 n += 1 avg = x / float(n) var = (x2 + n * avg ** 2) / (n-1) return [[var, n]] var_part_model = X_part.mapPartitions(var_part) \ .collect() print("Variance via Partitioning:") print(weighted_avg(var_part_model)) Variance via Partitioning: 851.095985421Example: Variance + Sufficient Statistics / Sketching
sketch_var = X_part.map(lambda num: (num, num**2, 1)) \ .reduce(lambda x, y: (x[0]+y[0], x[1]+y[1], x[2]+y[2]) ) x_bar_4 = sketch_var[0] / float(sketch_var[2]) N = sketch_var[2] print("Variance via Sketching:") (sketch_var[1] + N * x_bar_4 ** 2 ) / (N -1) Variance via Sketching: 851.07917000774989Linear Regression
To understand the MapReduce framework, lets solve a familar problem of Linear Regression. For Hadoop/MapReduce to work we MUST figure out how to parallelize our code, in other words how to use the hadoop system to only need to make a subset of our calculations on a subset of our data.
Assumption: The value of p, the number of explanatory variables is small enough for R to easily handle i.e.
We know from linear regression, that our estimate of :
and is small enough for R to solve for , thus we only need to get .
To break up this calculation we break our matrix X into submatricies :
Sys.setenv("HADOOP_PREFIX"="/usr/local/hadoop/2.6.0") Sys.setenv("HADOOP_CMD"="/usr/local/hadoop/2.6.0/bin/hadoop") Sys.setenv("HADOOP_STREAMING"= "/usr/local/hadoop/2.6.0/share/hadoop/tools/lib/hadoop-streaming-2.6.0.jar") library(rmr2) library(data.table) # Setup variables p = 10 num.obs = 200 beta.true = 1:(p+1) X = cbind(rep(1,num.obs), matrix(rnorm(num.obs * p), ncol = p)) y = X %*% beta.true + rnorm(num.obs) X.index = to.dfs(cbind(y, X)) rm(X, y, num.obs, p)map.XtX = function(., Xi) { Xi = Xi[,-1] #Get rid of y values in Xi keyval(1, list(t(Xi) %*% Xi)) } map.Xty = function(., Xi) { yi = Xi[,1] # Retrieve the y values Xi = Xi[,-1] #Get rid of y values in Xi keyval(1, list(t(Xi) %*% yi)) } Sum = function(., YY) { keyval(1, list(Reduce('+', YY))) } Sys.setenv("HADOOP_PREFIX"="/usr/local/hadoop/2.6.0") Sys.setenv("HADOOP_CMD"="/usr/local/hadoop/2.6.0/bin/hadoop") Sys.setenv("HADOOP_STREAMING"= "/usr/local/hadoop/2.6.0/share/hadoop/tools/lib/hadoop-streaming-2.6.0.jar") library(rmr2) library(data.table) #Setup variables p = 10 num.obs = 200 beta.true = 1:(p+1) X = cbind(rep(1,num.obs), matrix(rnorm(num.obs * p), ncol = p)) y = X %*% beta.true + rnorm(num.obs) X.index = to.dfs(cbind(y, X)) rm(X, y, num.obs, p) ########################## map.XtX = function(., Xi) { Xi = Xi[,-1] #Get rid of y values in Xi keyval(1, list(t(Xi) %*% Xi)) } map.Xty = function(., Xi) { yi = Xi[,1] # Retrieve the y values Xi = Xi[,-1] #Get rid of y values in Xi keyval(1, list(t(Xi) %*% yi)) } Sum = function(., YY) { keyval(1, list(Reduce('+', YY))) }The reason we are returning a list in the map function is because otherwise Reduce will only return a some of the elements of the matricies.
List prevents this by Reduce iterating though the elements of the list (the individual matricies) and applying the binary function ‘+’ to each one.
List is used in the reduce function
Sumbecause we will also use this as a combiner function and if we didn’t use a list we would have the same problem as above.XtX = values(from.dfs( mapreduce(input = X.index, map = map.XtX, reduce = Sum, combine = TRUE)))[[1]] Xty = values(from.dfs( mapreduce( input = X.index, map = map.Xty, reduce = Sum, combine = TRUE)))[[1]] beta.hat = solve(XtX, Xty) print(beta.hat) XtX = values(from.dfs( mapreduce(input = X.index, map = map.XtX, reduce = Sum, combine = TRUE)))[[1]] Xty = values(from.dfs( mapreduce( input = X.index, map = map.Xty, reduce = Sum, combine = TRUE)))[[1]] beta.hat = solve(XtX, Xty) print(beta.hat) [,1] [1,] 1.045835 [2,] 1.980511 [3,] 2.993829 [4,] 4.011599 [5,] 5.074755 [6,] 6.008534 [7,] 6.947164 [8,] 8.024570 [9,] 9.024757 [10,] 9.888609 [11,] 10.893023 -
Big Data Fundamentals
Essential Concepts and Tools
Originally created by Darrell Aucoin for a Big data talk at uWaterloo’s Stats Club
In pioneer days they used oxen for heavy pulling, and when one ox couldn’t budge a log, they didn’t try to grow a larger ox. We shouldn’t be trying for bigger computers, but for more systems of computers.
—Grace HoppeWhat is Big Data?
The 4 V’s of Big Data
Volume: The quantity of data.
- Usually too big to fit into the memory of a single machine.
Veracity: The quality of data can vary. The inconsistency of data.
Variety: Data often comes in a variety of formats and sources often needing to be combined for a data analysis.
Velocity: The speed of generation of new data.
Volume
- 100 terabytes of data are uploaded to Facebook daily.
- 90% of all data ever created was generated in the past 2 years.
Problem: Impossible to do data analysis with one computer on data this size.
Solution: A distributed computing system.

Veracity
- Big Data sets do not have the controls of regular studies (Naming inconsistency , Inconsistency in signal strength)
- Cannot simply assume data missing at random
Veracity naming inconsistency: a musician named several different ways in several different files
Variety
- Most of Big Data is unstructured or semi-structured data (Doesn’t have the guarantees of SQL)
- Data can be structured, semi-structured, or unstructured
- Often have to combine various datasets from a variety of sources and formats
Velocity
- Speed that data is created, stored, analyzed to create actionable intelligence
Every min: - 100 hours is uploaded to Youtube
- 200 million emails are sent
- 20 million photos are viewed
Often need to be very agile in creating a data product
-
Outlier Detection
-
Assimilating Data
Ask > Aquire > Assimilate > Analyze > Answer > Advise > Act
Extract/Transform/Load
Extract: data is usually stored in a form of a source in a specific type (such as flat files, relational databases, streaming data, XML/JSON files, Open Database Connectivity (ODBC) and/or Java Database Connectivity (JDBC) data sources. Transform: Cleanse, convert, aggregate, merge, and split and modify data so it use useful. Load: Once transformed, it can be loaded into another database or warehouse
Transforming and Normalizing Data
Binning Numerical Data
If numerical data needs to transformed into categorical data, it can be binned into groups
Encoding Categorical Data
If categorical data needs to be transformed into numerical data (for example if a classifier only works with numerical data), it can be encoded. If the data is binary, it can be encoded into 1 or 0. The issue if the data is not binary, is that by adding
Normilization
Fitting data betwen a specific range (such as 1 or -1)
Format conversion
binary conversion, time conversion,
Coordiate Conversion
geo conversion.
For example gps coordiate vs distance
Fourier Transfer
Convert to frequency domain using Fast Fourier Transform or Discrete wavelet transform
Data Cleaning
Outlier Detection
As part of the data cleaning stage, outliers can be detected through outlier detection. Once outliers are determined, they can be removed and then ignored or imputed. Alternatively there are algorithms which robustly ignore (or deal with) outliers.
Imputation
Random sampling, distributions, mean, regression
Filtering
Deduplication
Removing duplicates
Dimensionality Reduction
Principal Compnent analysis
Membership Assignment
First use clustering (X means, canopy clustering) to determine the cluster, than assign a membership.
Feature hashing
Text data: Term Frequecy Inverse Document Frequency
Data enrichment
In addition to cleaning data, data can be enriched by additional sources of data. For example, features can be added based on a specific feature and an additional dataset. For example geography or weather can be added to a dataset to predict if someone is going to take a taxi, bike or walk.
Further Reading
Dimensionality Reduction
-
Aquiring Data
Ask > Acquire > assimilate > analyze > answer > act
Downloading
Scraping
Logging
Streaming
-
Simulation
More content coming soon!
-
Project Economics
More content to come soon!
-
Optimization
More content to come soon!
Linear Programming
Deals with finding the max or min of a linear function (objective function is subject to linear constraints). For example, how do you maximize profits selling different products with limited resources?
Example 1: Resource Allocation Problem
Producing n different products, maximize profit to not exhausting our n different resources.
Decision Variable
= number of unit of product j to be produced
This is the decision variable (unknown to be determined from the solution of the model).
= denote the profit (utility per unit of product j) then = total profit from producing units of product j.
total profit from all products
Objective Function
Objective to be achieved by the system as a mathematical function of the system decision variables (DV). It is usually maximizing profit or minimizing cost for example.
= the amount of resource i needed to produce 1 unit of product j
= amount of resource i needed to make units of product j
This is the total amount of resource i used or needed.
Functional Constraints
Functional contraints are limitations imposed on the variable to satisfy the restriction of the model system expressed as a math function of the system DV.
We usually assume that . This is called the non-negativity constraint.
Summary
Find so as to maximize subject to , i = 1, … m and j = 1, …, n and where n is the number of decision variables, and m is he number of contraints.
Canonical Form of Linear Programming
Maximization
) subject to and
Minimization
) subject to and
General Mathematic Form
Find X so as to max f(x) subject to
-
Forumlating the Model
-
Solving the Model
-
Intrepreting the Model
Assumptions of L. P.
- Divisibility a) Proportionality (assumption about both objective function and functional contraints). This means that for each item of product j, both the profit contribution and the amount of each resource i consumed are strictly proportional to the number of units of .
b) Continuity: Variables are continious numbers, meaning we can produce not just interget (whole number) amounts of each product. Mathematically this is representedby
- Additivity Both the equation for the value to minimize or maximize are sums, and the contraints are linear as well
Linear Programming has 3 basic components:
- Decision variables (solution of model)
- Objective function (min or mix) with a goal (maximize profit, minimize cost)
- Constraints
Further Reading:
-
-
Analyze Data
Ask > Acquire > Assimilate > Analyze > Answer > Act
Content coming soon!
-
Exploratory Data Analysis
Exploratory data analysis (EDA) is a very important step which takes place after feature engineering and acquiring data and it should be done before any modeling. This is because it is very important for a data scientist to be able to understand the nature of the data without making assumptions.
The purpose of EDA is to use summary statistics and visualizations to better understand data, and find clues about the tendencies of the data, its quality and to formulate assumptions and the hypothesis of our analysis. EDA is NOT about making fancy visualizations or even aesthetically pleasing ones, the goal is to try and answer questions with data. Your goal should be to be able to create a figure which someone can look at in a couple of seconds and understand what is going on. If not, the visualization is too complicated (or fancy) and something similar should be used.
EDA is also very iterative since we first make assumptions based on our first exploratory visualizations, then build some models. We then make visualizations of the model results and tune our models.
Types of Data
Before we can start learning about exploring data, let us first learn the different types of data or levels of measurement. I highly recommend you read Levels of Measurement in the online stats book, and continue reading the sections to bush up your knowledge in statistics. This section is just a summary.
Data comes in various forms but can be classified into two main groups: structured data and unstructured. Structured data is data which is a form of data which has a high degree or organization such as numerical or categorical data. Temperature, phone numbers, gender are examples of structured data. Unstructured data is data in a form which doesn’t explicitly have structure we are used to. Examples of unstructured data are photos, images, audio, language text and many others. There is an emerging field called Deep Learning which is using a specialized set of algorithms which perform well with unstructured data. In this guide we are going to focus on structured data, but provide brief information for the relevant topics in deep learning. The two common types of structured we commonly deal with are categorical variables (which have a finite set of values) or numerical values (which are continuous).
Categorical Variables
Categorical variables can also be nominal or ordinal. Nominal data has no intrinsic ordering to the categories. For example gender (Male, Female, Other) has no specific ordering. Ordinal data as clear ordering such as three settings on a toaster (high medium and low). A frequency table (count of each category) is the common statistic for describing categorical data of each variable, and a bar chart or a waffle chart (shown below) are two visualizations which can be used.
While a pie chart is a very common method for representing categorical variables, it is not recommended since it is very difficult for humans to understand angles. Simply put by statstician and visualization professor Edward Tufte: “pie charts are bad”, others agree and some even say that “pie charts are the worst”.
For example what you you determine from the follow pie chart?
The charts look identical, and it takes more than a couple of seconds to understand the data. Now compare this to the corresponding bar chart:
A reader an instantly compare the 5 variables. Since humans have a difficult time comparing angles, bar graphs or waffle diagrams are recommended. There are many other visualizations which are not recommended: spider charts, stacked bar charts, and many other junkcharts.
For example, this visualization is very complicated and difficult to understanding:

Often less is more: the plot redux as a simple line graph:
When dealing with multi-categorical data, avoid using stacked bar charts and follow the guidelines written by Solomon Messing (data scientist I met while working at Facebook).
Numeric Variables
Numeric or continuous variables can be any value within a finite or infinite interval. Examples include temperature, height, weight. There are two types of numeric variables are interval and ratios. Interval variables have numeric scales and the same interpretation throughout the scale, but do not have an absolute zero. For example temperature in Fahrenheit or Celcius can meaningfully be subtracted or added (difference between 10 degrees and 20 degrees is the same difference as 40 to 50 degrees) but can not be multiplied. For example, a day which is twice as hot may not be twice the temperature.
“The ratio scale of measurement is the most informative scale. It is an interval scale with the additional property that its zero position indicates the absence of the quantity being measured. You can think of a ratio scale as the three earlier scales rolled up in one. Like a nominal scale, it provides a name or category for each object (the numbers serve as labels). Like an ordinal scale, the objects are ordered (in terms of the ordering of the numbers). Like an interval scale, the same difference at two places on the scale has the same meaning. And in addition, the same ratio at two places on the scale also carries the same meaning.” A good example of a ratio scale is weight since it has a true zero and can be added, subtracted, multiplied or divided.
Binning (Numeric to Categorical)
Binning otherwise known as discretization is the process of transforming numerical variables into categorical. For example age can be categories into 0-12 (child), 13-19 (teenager), 20-65 (adult), 65+ (senior). Binning is powerful as it can be used as a filter to reduce noise or non-linearity and some algorithms such as decision trees require categorical data. Binning also allows data scientists to quickly evaluate outliers, invalid or missing values for numerical values. Techniques for binning include using equal width (based on range), equal frequency in each bin, sorted rank, quantiles, or math functions (such as log). Binning can be used based on information entropy or information gain.
Encoding
Encoding, otherwise known as continuization is the transformation of categorical variables into numerical (or binary) variables. A basic example of encoding is gender: -1, 0, 1 could be used to describe male, other and female. Binary encoding is a special case of encoding where the value is set to a 0 or 1 to indicate absence or presence of a category. One hot encoding is a special case where multiple categories are each binary encoded. Given we have k categories, this will create k extra features (thus increasing the dimensionality of the data) Another method for encoding is using a target and probability based encoding. The category is the average value and includes a probability.
Iris DataSet
For this article (and tutorial) on exploratory data analysis, we are going be investigating Anscombe’s_quartet and Fisher’s Iris data set.
“Anscombe’s quartet comprises four datasets that have nearly identical simple statistical properties, yet appear very different when graphed. Each dataset consists of eleven (x,y) points. They were constructed in 1973 by the statistician Francis Anscombe to demonstrate both the importance of graphing data before analyzing it and the effect of outliers on statistical properties.” The Iris data set is a multivariate data set introduced by Ronald Fisher in his 1936 paper The use of multiple measurements. It shows the variation of Iris flowers of three related species.
Summary Statistics
Summary statistics are measurements meant to describe data. In the field of descriptive statistics, there are many summary measurements, but we will leave the definition (and derivation ) to textbooks. Examples of summary/ descriptive statistics for a single numerical variable is the mean, median, mode, max, min, range, quartiles/percentiles, variance, standard deviation, coefficient of determination, skewness and kurtosis. Summary statistics for categorical variables is the number of distinct counts. The most basic summary statistic for text data is term frequency and inverse document frequency. For bivariate data, the summary statistics is the linear correlation, chi-squared, or the p value based z-test, t-test or analysis of variance. This link outlines the common summary statistics, their basic equations and a description. This should come as a review since you should have a solid understanding of statistics at this point.
You can download the Ansombe Excel worksheet with summary statistics from datascienceguide.github.io/datasets/anscombe.xls and the Iris dataset Excel worksheet with summary statistics for each variable from datascienceguide.github.io/datasets/iris.xls
Notice how on the Ansombe dataset, the mean, standard deviation and correlation between x and y are almost identical. When we learn about linear regression, we will also see the same coefficients for linear regression as well.
Visualization
In addition to summary statistics, visualizations can be used to explore and describe data. We will learn in the tutorials the importance of visualizations, and that it is not enough to use simple statistical properties to describe data. This is demonstrated by Anscombe’s quartet as outlined in this article Why Data Visualizations (are important). This is also a great article and Book on the flaw of averages.
Examples of visualizations for numeric data are line charts with error bars, histograms, box and whisker plots, for categorical data bar charts and waffle charts, and for bivariate data are scatter charts or combination charts. The tutorial on exploratory data analysis goes over many of these visualizations.
There are many tools and libraries which can be used for plotting visualizations: - Excel/ Libre Office - Weka - matplotlib (python) - seaborn (python) - Grammer of graphics (ggplot2) - infovis - Rshiny - data driven documents (D3.js) - panoramix
In additional, Tibco Spotfire and Tableau are popular but commercial solutions for data visualizations.
For the next set of images, click the image to be redirected to the example with source code.
Univariate data (One variable)
The two visualizations used to describe univariate (1 variable) data is the box plot and the histogram. The box plot can be used to show the minimum, maximum, mean, median, quantiles and range.
The histogram can be used to show the count, mode, variance, standard deviation, coefficient of deviation, skewness and kurtosis.
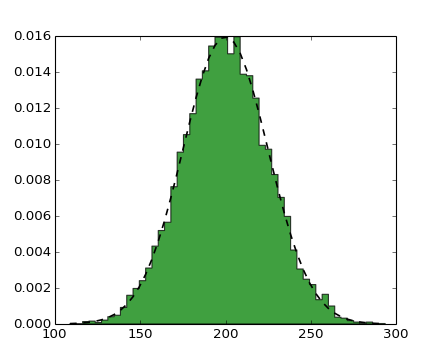
Bivariate data (Two Variables)
When plotting the relation between two variables, one can use a scatter plot.

If the data is time series or has an order, a line chart can be used.

Multivariate Visualization
When dealing with multiple variables, it is tempting to make three dimensional plots, but as show below it can be difficult to understand the data:

Rather I recommend create a scatter plot of the relation between each variable:
Combined charts also are great ways to visualize data, since each chart is simple to understand on its own.

For very large dimensionality, you can reduce the dimensionality using principle component analysis, Latent Dirichlet allocation or other techniques and then make a plot of the reduced variables. This is particularly important for high dimensionality data and has applications in deep learning such as visualizing natural language or images.
Text Data
For example with Text data, one could create a world cloud, where the size of each word is the based on its frequency in the text. To remove the words which add noise to the dataset, the documents can be grouped using Topic modeling and only the important words can be displayed.
Image data
When doing image classification, it is common to use decomposition and remove the dimensionality of the data. For example, an image before decomposition looks like:

Instead of blindly using decomposition, a data scientist could plot the result:

By looking at the contrast (black and white) in the images, we can see there is an importance with the locations of the eyes, nose and mouth, along with the head shape.
Conclusion and Next Steps
Data visualization is a fun an very important part of being a data scientist. Simplicity and the ability for others to quickly understand a message is the most important part of exploratory data analysis. Before every building any model, make sure you create a visualization to understand the data first! Exploratory is not a subject you can learn by reading book. You need to out and acquire data and start plotting! The exploratory data analysis tutorial gets you started. At the end of the tutorial there are various links to public datasets you can start exploring. After making your own visualization we can move onto describing data using clustering.
Further Reading
Baby steps for performing exploratory analysis
Theory
Descriptive Statistics and Exploratory Data Analysis
Think Stats Exploratory Data Analysis in Python
A First Look at Data Principles and Procedures of Exploratory Data Analysis